

Коды Хафмана.
Коды Хафмана строятся по иному алгоритму. Процедура кодирования состоит из двух этапов. На первом этапе последовательно проводят однократные сжатия алфавита. Однократное сжатие – замена двух последних символов (с низшими вероятностями) одним, с суммарной вероятностью. Сжатия проводят до тех пор, пока не останется два символа. При этом заполняют таблицу кодирования, в которой проставляют результирующие вероятности, а также изображают маршруты, по которым новые символы переходят на следующем этапе.
На втором этапе происходит собственно кодирование, которое начинается с последнего этапа: первому из двух символов присваивают код 1, второму – 0. После этого переходят на предыдущий этап. К символам, которые не участвовали в сжатии на этом этапе, приписывают коды с последующего этапа, а к двум последним символам дважды приписывают код символа, полученного после склеивания, и дописывают к коду верхнего символа 1, нижнего – 0. Если символ дальше в склеивании не участвует, его код остается неизменным. Процедура продолжается до конца (то есть до первого этапа).
Таблица 2.3.
Кодирование по алгоритму Хафмана
N |
|
код |
I |
II |
III |
IV |
V |
VI |
VII |
4 |
0.3 |
11 |
0.3 11 |
0.3 11 |
0.3 11 |
0.3 11 |
0.3 11 |
0.4 0 |
0.6 1 |
2 |
0.2 |
01 |
0.2 01 |
0.2 01 |
0.2 01 |
0.2 01 |
0.3 10 |
0.3 11 |
0.4 0 |
6 |
0.15 |
101 |
0.15 101 |
0.15 101 |
0.15 101 |
0.2 00 |
0.2 01 |
0.3 10 |
|
3 |
0.1 |
001 |
0.1 001 |
0.1 001 |
0.15 100 |
0.15 101 |
0.2 00 |
|
|
1 |
0.1 |
000 |
0.1 000 |
0.1 000 |
0.1 001 |
0.15 100 |
|
|
|
9 |
0.05 |
1000 |
0.05 1000 |
0.1 1001 |
0.1 000 |
|
|
|
|
5 |
0.05 |
10011 |
0.05 10011 |
0.05 1000 |
|
|
|
|
|
7 |
0.03 |
100101 |
0.05 10010 |
|
|
|
|
|
|
8 |
0.02 |
100100 |
|
|
|
|
|
|
|






В таблице 2.3 показано кодирование по алгоритму Хафмана. Как видно из таблицы, кодирование осуществлялось за семь этапов. Слева указаны вероятности символов, справа – промежуточные коды. Стрелками показаны перемещения вновь образованных символов. На каждом этапе два последних символа отличаются только младшим разрядом, что соответствует методике кодирования. Вычислим среднюю длину слова:
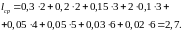
Недостатком кода Хафмана можно считать то, что нулевая кодовая комбинация не всегда соответствует наименее вероятному символу. Это может привести к потере этого символа при передаче нулей низкими уровнями.
Оба кода удовлетворяют требованию однозначности декодирования: как видно из таблиц, более короткие комбинации не являются началом более длинных кодов.
При увеличении количества символов эффективности кодов возрастают, поэтому в некоторых случаях кодируют более крупные блоки (например, если речь идет о текстах, можно кодировать некоторые наиболее часто встречающиеся слоги, слова и даже фразы).
Эффект от внедрения таких кодов определяется в сравнении их с равномерным кодом:
|
(2.24) |

где – количество разрядов равномерного кода, который заменяется эффективным.
Классический алгоритм Хафмана относится к двухпроходным, т. е. требует вначале набора статистики по символам и сообщениям, а потом описанных выше процедур. Это неудобно на практике, поскольку увеличивает время обработки сообщений и накопления словаря. Чаще используются однопроходные методы, в которых процедуры накопления и кодирования совмещаются. Такие методы называются ещё адаптивным сжатием по Хафману [48].
Сущность адаптивного сжатия по Хафману сводится к построению первоначального кодового дерева и последовательной его модификации после поступления каждого очередного символа. Как и прежде, деревья здесь бинарные, т. е. из каждой вершины графа – дерева исходит максимум две дуги. Принято называть исходную вершину родителем, а две связанных с ней следующих вершины – детьми. Введём понятие веса вершины – это количество символов (слов), соответствующих данной вершине, полученных при подаче исходной последовательности. Очевидно, что сумма весов детей равна весу родителя.
После введения очередного символа входной последовательности пересматривается кодовое дерево: пересчитываются веса вершин и при необходимости вершины переставляются. Правило перестановки вершин следующее: веса нижних вершин наименьшие, причём вершины, находящиеся слева на графе, имеют наименьшие веса.
Одновременно вершины нумеруются. Нумерация начинается с нижних (висячих, т. е. не имеющих детей) вершин слева направо, потом переносится на верхний уровень и т.д. до нумерации последней, исходной вершины. При этом достигается следующий результат: чем меньше вес вершины, тем меньше её номер.
Перестановка осуществляется в основном для висячих вершин. При перестановке должно учитываться сформулированное выше правило: вершины с большим весом имеют и больший номер.
После прохождения последовательности (она называется также контрольной или тестовой) всем висячим вершинам присваиваются кодовые комбинации. Правило присвоения кодов аналогично вышеизложенному: количество разрядов кода равно количеству вершин, через которые проходит маршрут от исходной до данной висячей вершины, а значение конкретного разряда соответствует направлению от родителя к «ребёнку» (скажем, переход влево от родителя соответствует значению 1, вправо – 0).
Полученные кодовые комбинации заносятся в память устройства сжатия вместе с их аналогами и образуют словарь. Использование алгоритма заключается в следующем. Сжимаемая последовательность символов разбивается на фрагменты в соответствии с имеющимся словарём, после чего каждый из фрагментов заменяется его кодом из словаря. Не обнаруженные в словаре фрагменты образуют новые висячие вершины, приобретают вес и также заносятся в словарь. Таким образом формируется адаптивный алгоритм пополнения словаря.
Для повышения эффективности метода желательно увеличивать размер словаря; в этом случае коэффициент сжатия повышается. Практически размер словаря составляет 4 – 16 килобайт памяти.
Проиллюстрируем приведённый алгоритм примером. На рис. 2.12 приведена исходная диаграмма (её называют также деревом Хафмана). Каждая вершина дерева показана прямоугольником, в котором вписаны через дробь две цифры: первая означает номер вершины, вторая – её вес. Как можно убедиться, соответствие весов вершин и их номеров выполняется.
|
|
Рис. 2.2. Исходное дерево кода Хафмана |
Рис. 2.3. Изменение весов |


Предположим теперь, что символ, соответствующий вершине 1, в тестовой последовательности встретился вторично. Вес вершины изменился, как показано на рис. 2.13, вследствие чего правило нумерации вершин нарушено. На следующем этапе меняем расположение висячих вершин, для чего меняем местами вершины 1 и 4 и перенумеровываем все вершины дерева. Полученный граф приведён на рис. 2.14. Далее процедура продолжается аналогично.

Рис. 2.4. Перестановки в дереве Хафмана
Следует помнить, что каждая висячая вершина в дереве Хафмана соответствует определённому символу или их группе. Родитель отличается от детей тем, что группа символов, ему соответствующая, на один символ короче, чем у его детей, а эти дети различаются последним символом. Например, родителю соответствуют символы «кар»; тогда у детей могут быть последовательности «кара» и «карп».