

Общие принципы построения современных эвм
Основным принципом построения всех современных ЭВМ является программное управление. В основе его лежит представление алгоритма решения любой задачи в виде программы вычислений.
“Алгоритм - конечный набор предписаний, определяющий решение задачи посредством конечного количества операций”. “Программа ( для ЭВМ) - упорядоченная последовательность команд, подлежащая обработке” (стандарт ISO 2382/1-84). Следует заметить, что строгого, однозначного определения алгоритма, равно как и однозначных методов его преобразования в программу вычислений, не существует. Принцип программного управления может быть осуществлен различными способами. Стандартом для построения практически всех ЭВМ стал способ, описанный Дж. фон Нейманом в 1945 г. при построении еще первых образцов ЭВМ. Суть его заключается в следующем.
Все вычисления, предписанные алгоритмом решения задачи, должны быть представлены в виде программы, состоящей из последовательности управляющих слов-команд. Каждая команда содержит указания на конкретную выполняемую операцию, место нахождения (адреса) операндов и ряд служебных признаков. Операнды - переменные, значения которых участвуют в операциях преобразования данных. Список (массив) всех переменных (входных данных, промежуточных значений и результатов вычислений) является еще одним неотъемлемым элементом любой программы.
Для доступа к программам, командам и операндам используются их адреса. В качестве адресов выступают номера ячеек памяти ЭВМ, предназначенных для хранения объектов. Информация ( командная и данные: числовая, текстовая, графическая и т.п.) кодируется двоичными цифрами 0 и 1. Поэтому различные типы информации, размещенные в памяти ЭВМ, практически неразличимы, идентификация их возможна лишь при выполнении программы, согласно ее логике, по контексту.
Каждый тип информации имеет форматы - структурные единицы информации, закодированные двоичными цифрами 0 и 1. Обычно все форматы данных, используемые в ЭВМ, кратны байту, т.е. состоят из целого числа байтов.
Последовательность битов в формате, имеющая определенный смысл, называется полем. Например, в каждой команде программы различают поле кода операций, поле адресов операндов. Применительно к числовой информации выделяют знаковые разряды, поле значащих разрядов чисел, старшие и младшие разряды.
Последовательность, состоящая из определенного принятого для данной ЭВМ числа байтов, называется словом. Для больших ЭВМ размер слова составляет четыре байта, для ПЭВМ - два байта. В качестве структурных элементов информации различают также полуслово, двойное слово и др.
Схема ЭВМ, отвечающая программному принципу управления, логично вытекает из последовательного характера преобразований, выполняемых человеком по некоторому алгоритму (программе). Обобщенная структурная схема ЭВМ первых поколений представлена на рис. 1.1.
В любой ЭВМ имеются устройства ввода информации (УВв), с помощью которых пользователи вводят в ЭВМ программы решаемых задач и данные к ним. Введенная информация полностью или частично сначала запоминается в оперативном запоминающем устройстве (ОЗУ), а затем переносится во внешнее запоминающее устройство (ВЗУ), предназначенное для длительного хранения информации, где преобразуется в специальный программный объект - файл. “Файл - идентифицированная совокупность экземпляров полностью описанного в конкретной программе типа данных, находящихся вне программы во внешней памяти и доступных программе посредством специальных операций (ГОСТ 20866 - 85)”.
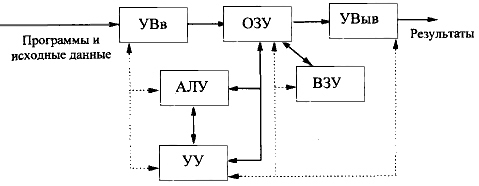
Рис. 1.1. Структурная схема ЭВМ первого и второго поколений
При использовании файла в вычислительном процессе его содержимое переносится в ОЗУ. Затем программная информация команда за командой считывается в устройство управления (УУ).
Устройство управления предназначается для автоматического выполнения программ путем принудительной координации всех остальных устройств ЭВМ. Цепи сигналов управления показаны на рис. 1.1 штриховыми линиями. Вызываемые из ОЗУ команды дешифрируются устройством управления:
определяются код операции, которую необходимо выполнить следующей, и адреса операндов, принимающих участие в данной операции.
В зависимости от количества используемых в команде операндов различаются одно-, двух-, трехадресные и безадресные команды. В одноадресных командах указывается, где находится один из двух обрабатываемых операндов. Второй операнд должен быть помещен заранее в арифметическое устройство (для этого в систему команд вводятся специальные команды пересылки данных между устройствами).
Двухадресные команды содержат указания о двух операндах, размещаемых в памяти (или в регистрах и памяти). После выполнения команды в один из этих адресов засылается результат, а находившийся там операнд теряется.
В трехадресных командах обычно два адреса указывают, где находятся исходные операнды, а третий - куда необходимо поместить результат.
В безадресных командах обычно обрабатывается один операнд, который до и после операции находится на одном из регистров арифметико-логического устройства (АЛУ). Кроме того, безадресные команды используются для выполнения служебных операций (очистить экран, заблокировать клавиатуру, снять блокировку и др.).
Все команды программы выполняются последовательно, команда за командой, в том порядке, как они записаны в памяти ЭВМ (естественный порядок следования команд). Этот порядок характерен для линейных программ, т.е. программ, не содержащих разветвлений. Для организации ветвлений используются команды, нарушающие естественный порядок следования команд. Отдельные признаки результатов r(r = 0, r < 0, r > 0 и др.) устройство управления использует для изменения порядка выполнения команд программы.
АЛУ выполняет арифметические и логические операции над данными. Основной частью АЛУ является операционный автомат, в состав которого входят сумматоры, счетчики, регистры, логические преобразователи и др. Оно каждый раз перенастраивается на выполнение очередной операции. Результаты выполнения отдельных операций сохраняются для последующего использования на одном из регистров АЛУ или записываются в память. Результаты, полученные после выполнения всей программы вычислений, передаются на устройства вывода (УВыв) информации. В качестве УВыв могут использоваться экран дисплея, принтер, графопостроитель и др.
Современные ЭВМ имеют достаточно развитые системы машинных операций. Например, ЭВМ типа IBM PC имеют около 200 различных операций (170 - 230 в зависимости от типа микропроцессора). Любая операция в ЭВМ выполняется по определенной микропрограмме, реализуемой в схемах АЛУ соответствующей последовательностью сигналов управления (микрокоманд). Каждая отдельная микрокоманда- это простейшее элементарное преобразование данных типа алгебраического сложения, сдвига, перезаписи информации и т.п.
Уже в первых ЭВМ для увеличения их производительности широко применялось совмещение операций. При этом последовательные фазы выполнения отдельных команд программы (формирование адресов операндов, выборка операндов, выполнение операции, отсылка результата) выполнялись отдельными функциональными блоками. В своей работе они образовывали своеобразный конвейер, а их параллельная работа позволяла обрабатывать различные фазы целого блока команд. Этот принцип получил дальнейшее развитие в ЭВМ следующих поколений. Но все же первые ЭВМ имели очень сильную централизацию управления, единые стандарты форматов команд и данных, “жесткое” построение циклов выполнения отдельных операций, что во многом объясняется ограниченными возможностями используемой в них элементной базы. Центральное УУ обслуживало не только вычислительные операции, но и операции ввода-вывода, пересылок данных между ЗУ и др. Все это позволяло в какой-то степени упростить аппаратуру ЭВМ, но сильно сдерживало рост их производительности.
В ЭВМ третьего поколения произошло усложнение структуры за счет разделения процессов ввода-вывода информации и ее обработки (рис. 1.2).

Рис. 1.2. Структурная схема ЭВМ третьего поколения
Сильносвязанные устройства АЛУ и УУ получили название процессор, т.е. устройство, предназначенное для обработки данных. В схеме ЭВМ появились также дополнительные устройства, которые имели названия: процессоры ввода-вывода, устройства управления обменом информацией, каналы ввода-вывода (КВВ). Последнее название получило наибольшее распространение применительно к большим ЭВМ. Здесь наметилась тенденция к децентрализации управления и параллельной работе отдельных устройств, что позволило резко повысить быстродействие ЭВМ в целом.
Среди каналов ввода-вывода выделяли мультиплексные каналы, способные обслуживать большое количество медленно работающих устройств ввода-вывода (УВВ), и селекторные каналы, обслуживающие в многоканальных режимах скоростные внешние запоминающие устройства (ВЗУ).
В персональных ЭВМ, относящихся к ЭВМ четвертого поколения, произошло дальнейшее изменение структуры (рис. 1.3). Они унаследовали ее от мини-ЭВМ.

Рис. 1.3. Структурная схема ПЭВМ
Соединение всех устройств в единую машину обеспечивается с помощью общей шины, представляющей собой линии передачи данных, адресов, сигналов управления и питания. Единая система аппаратурных соединений значительно упростила структуру, сделав ее еще более децентрализованной. Все передачи данных по шине осуществляются под управлением сервисных программ.
Ядро ПЭВМ образуют процессор и основная память (ОП), состоящая из оперативной памяти и постоянного запоминающего устройства (ПЗУ). ПЗУ предназначается для записи и постоянного хранения наиболее часто используемых программ управления. Подключение всех внешних устройств (ВнУ), дисплея, клавиатуры, внешних ЗУ и других обеспечивается через соответствующие адаптеры - согласователи скоростей работы сопрягаемых устройств или контроллеры - специальные устройства управления периферийной аппаратурой. Контроллеры в ПЭВМ играют роль каналов ввода-вывода. В качестве особых устройств следует выделить таймер - устройство измерения времени и контроллер прямого доступа к памяти (КПД) - устройство, обеспечивающее доступ к ОП, минуя процессор.
Способ формирования структуры ПЭВМ является достаточно логичным и естественным стандартом для данного класса ЭВМ.
Децентрализация построения и управления вызвала к жизни такие элементы, которые являются общим стандартом структур современных ЭВМ:
Модульность построения, магистральность, иерархия управления.
Модульность построения предполагает выделение в структуре ЭВМ достаточно автономных, функционально и конструктивно законченных устройств (процессор, модуль памяти, накопитель на жестком или гибком магнитном диске).
Модульная конструкция ЭВМ делает ее открытой системой, способной к адаптации и совершенствованию. К ЭВМ можно подключать дополнительные устройства, улучшая ее технические и экономические показатели. Появляется возможность увеличения вычислительной мощности, улучшения структуры путем замены отдельных устройств на более совершенные, изменения и управления конфигурацией системы, приспособления ее к конкретным условиям применения в соответствии с требованиями пользователей.
В современных ЭВМ принцип децентрализации и параллельной работы распространен как на периферийные устройства, так и на сами ЭВМ (процессоры). Появились вычислительные системы, содержащие несколько вычислителей (ЭВМ или процессоры), работающие согласованно и параллельно. Внутри самой ЭВМ произошло еще более резкое разделение функций между средствами обработки. Появились отдельные специализированные процессоры, например сопроцессоры, выполняющие обработку чисел с плавающей точкой, матричные процессоры и др.
Все существующие типы ЭВМ выпускаются семействами, в которых различают старшие и младшие модели. Всегда имеется возможность замены более слабой модели на более мощную. Это обеспечивается информационной, аппаратурной и программной совместимостью. Программная совместимость в семействах устанавливается по принципу снизу-вверх, т.е. программы, разработанные для ранних и младших моделей, могут обрабатываться и на старших, но не обязательно наоборот.
Модульность структуры ЭВМ требует стандартизации и унификации оборудования, номенклатуры технических и программных средств, средств сопряжения - интерфейсов, конструктивных решений, унификации типовых элементов замены, элементной базы и нормативно-технической документации. Все это способствует улучшению технических и эксплуатационных характеристик ЭВМ, росту технологичности их производства.
Децентрализация управления предполагает иерархическую организацию структуры ЭВМ. Централизованное управление осуществляет устройство управления главного, или центрального, процессора. Подключаемые к центральному процессору модули (контроллеры и КВВ) могут, в свою очередь, использовать специальные шины или магистрали для обмена управляющими сигналами, адресами и данными. Инициализация работы модулей обеспечивается по командам центральных устройств, после чего они продолжают работу по собственным программам управления. Результаты выполнения требуемых операций представляются ими “вверх по иерархии” для правильной координации всех работ.
Иерархический принцип построения и управления характерен не только для структуры ЭВМ в целом, но и для отдельных ее подсистем. Например, по этому же принципу строится система памяти ЭВМ.
Так, с точки зрения пользователя желательно иметь в ЭВМ оперативную память большой информационной емкости и высокого быстродействия. Однако одноуровневое построение памяти не позволяет одновременно удовлетворять этим двум противоречивым требованиям. Поэтому память современных ЭВМ строится по многоуровневому, пирамидальному принципу.
В состав процессоров может входить сверхоперативное запоминающее устройство небольшой емкости, образованное несколькими десятками регистров с быстрым временем доступа (единицы нс). Здесь обычно хранятся данные, непосредственно используемые в обработке.
Следующий уровень образует кэш-память или память блокнотного типа. Она представляет собой буферное запоминающее устройство, предназначенное для хранения активных страниц объемом десятки и сотни Кбайтов. Время обращения к данным составляет 10-20 нс, при этом может использоваться ассоциативная выборка данных. Кэш-память, как более быстродействующая ЗУ, предназначается для ускорения выборки команд программы и обрабатываемых данных. Сами же программы пользователей и данные к ним размещаются в оперативном запоминающем устройстве (емкость - миллионы машинных слов, время выборки - до 100 нс).
Часть машинных программ, обеспечивающих автоматическое управление вычислениями и используемых наиболее часто, может размещаться в постоянном запоминающем устройстве (ПЗУ). На более низких уровнях иерархии находятся внешние запоминающие устройства на магнитных носителях:
на жестких и гибких магнитных дисках, магнитных лентах, магнитооптических дисках и др. Их отличает более низкое быстродействие и очень большая емкость.
Организация заблаговременного обмена информационными потоками между ЗУ различных уровней при децентрализованном управлении ими позволяет рассматривать иерархию памяти как единую абстрактную кажущуюся (виртуальную) память. Согласованная работа всех уровней обеспечивается под управлением программ операционной системы. Пользователь имеет возможность работать с памятью, намного превышающей емкость ОЗУ. ,
Децентрализация управления и структуры ЭВМ позволила перейти к более сложным многопрограммным (мультипрограммным) режимам. При этом в ЭВМ одновременно может обрабатываться несколько программ пользователей.
В ЭВМ, имеющих один процессор, многопрограммная обработка является кажущейся. Она предполагает параллельную работу отдельных устройств, задействованных в вычислениях по различным задачам пользователей. Например, компьютер может производить распечатку каких-либо документов и принимать сообщения, поступающие по каналам связи. Процессор при этом может производить обработку данных по третьей программе, а пользователь - вводить данные или программу для новой задачи, слушать музыку и т.п.
В ЭВМ или вычислительных системах, имеющих несколько процессоров обработки, многопрограммная работа может быть более глубокой. Автоматическое управление вычислениями предполагает усложнение структуры за счет включения в ее состав систем и блоков, разделяющих различные вычислительные процессы друг от друга, исключающие возможность возникновения взаимных помех и ошибок (системы прерываний и приоритетов, защиты памяти). Самостоятельного значения в вычислениях они не имеют, но являются необходимым элементом структуры для обеспечения этих вычислений.
Как видно, полувековая история развития ЭВТ дала не очень широкий спектр основных структур ЭВМ. Все приведенные структуры не выходят за пределы классической структуры фон Неймана. Их объединяют следующие Традиционные признаки [53]:
ядро ЭВМ образует процессор - единственный вычислитель в структуре, дополненный каналами обмена информацией и памятью;
линейная организация ячеек всех видов памяти фиксированного размера;
одноуровневая адресация ячеек памяти, стирающая различия между всеми типами информации;
внутренний машинный язык низкого уровня, при котором команды содержат элементарные операции преобразования простых операндов;
последовательное централизованное управление вычислениями;
достаточно примитивные возможности устройств ввода-вывода. Несмотря на все достигнутые успехи, классическая структура ЭВМ не обеспечивает возможностей дальнейшего увеличения производительности. Наметился кризис, обусловленный рядом существенных недостатков:
плохо развитые средства обработки нечисловых данных (структуры, символы, предложения, графические образы, звук, очень большие массивы данных и др.);
несоответствие машинных операций операторам языков высокого уровня;
примитивная организация памяти ЭВМ;
низкая эффективность ЭВМ при решении задач, допускающих параллельную обработку и т.п.
Все эти недостатки приводят к чрезмерному усложнению комплекса программных средств, используемого для подготовки и решения задач пользователей.
В ЭВМ будущих поколений, с использованием в них “встроенного искусственного интеллекта”, предполагается дальнейшее усложнение структуры; В-первую очередь это касается совершенствования процессов общения пользователей с ЭВМ (использование аудио-, видеоинформации, систем мультимедиа и др.) , обеспечения доступа к базам данных и базам знаний, организации параллельных вычислений. Несомненно, что этому должны соответствовать новые параллельные структуры с новыми принципами их построения. В качестве примера укажем, что самая быстрая ЭВМ фирмы IBM в настоящее время обеспечивает быстродействие 600 MIPS (миллионов команд в секунду), самая же большая гиперкубическая система nCube дает быстродействие 123.103 MBPS. Расчеты показывают, что стоимость одной машинной операции в гиперсисте-ме примерно в тысячу раз меньше. Вероятно, подобными системами будут обслуживаться большие информационные хранилища.
Архитектура системы команд. Классификация процессоров (CISC и RISC)
Как уже было отмечено, архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту или разработчику компиляторов.
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники являются архитектуры CISC и RISC. Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360, ядро которой используется с1964 года и дошло до наших дней, например, в таких современных мейнфреймах как IBM ES/9000.
Лидером в разработке микропроцессоров c полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно: сравнительно небольшое число регистров общего назначения; большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов; большое количество методов адресации; большое количество форматов команд различной разрядности; преобладание двухадресного формата команд; наличие команд обработки типа регистр-память.
Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд (RISC - Reduced Instruction Set Computer). Зачатки этой архитектуры уходят своими корнями к компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин. Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research. Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета.
Разработка экспериментального проекта компании IBM началась еще в конце 70-х годов, но его результаты никогда не публиковались и компьютер на его основе в промышленных масштабах не изготавливался. В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой проект и изготовили две машины, которые получили названия RISC-I и RISC-II. Главными идеями этих машин было отделение медленной памяти от высокоскоростных регистров и использование регистровых окон. В 1981году Дж.Хеннесси со своими коллегами опубликовал описание стенфордской машины MIPS, основным аспектом разработки которой была эффективная реализация конвейерной обработки посредством тщательного планирования компилятором его загрузки.
Эти три машины имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт). Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата.
Среди других особенностей RISC-архитектур следует отметить наличие достаточно большого регистрового файла (в типовых RISC-процессорах реализуются 32 или большее число регистров по сравнению с 8 - 16 регистрами в CISC-архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле большее время и упрощает работу компилятора по распределению регистров под переменные. Для обработки, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
Ко времени завершения университетских проектов (1983-1984 гг.) обозначился также прорыв в технологии изготовления сверхбольших интегральных схем. Простота архитектуры и ее эффективность, подтвержденная этими проектами, вызвали большой интерес в компьютерной индустрии и с 1986 года началась активная промышленная реализация архитектуры RISC. К настоящему времени эта архитектура прочно занимает лидирующие позиции на мировом компьютерном рынке рабочих станций и серверов.
Развитие архитектуры RISC в значительной степени определялось прогрессом в области создания оптимизирующих компиляторов. Именно современная техника компиляции позволяет эффективно использовать преимущества большего регистрового файла, конвейерной организации и большей скорости выполнения команд. Современные компиляторы используют также преимущества другой оптимизационной техники для повышения производительности, обычно применяемой в процессорах RISC: реализацию задержанных переходов и суперскалярной обработки, позволяющей в один и тот же момент времени выдавать на выполнение несколько команд.
Следует отметить, что в последних разработках компании Intel (имеется в виду Pentium P54C и процессор следующего поколения P6), а также ее последователей-конкурентов (AMD R5, Cyrix M1, NexGen Nx586 и др.) широко используются идеи, реализованные в RISC-микропроцессорах, так что многие различия между CISC и RISC стираются. Однако сложность архитектуры и системы команд x86 остается и является главным фактором, ограничивающим производительность процессоров на ее основе.
Методы адресации и типы данных
Методы адресации
В машинах к регистрами общего назначения метод (или режим) адресации объектов, с которыми манипулирует команда, может задавать константу, регистр или ячейку памяти. Для обращения к ячейке памяти процессор прежде всего должен вычислить действительный или эффективный адрес памяти, который определяется заданным в команде методом адресации.
На рис. 4.1 представлены все основные методы адресации операндов, которые реализованы в компьютерах, рассмотренных в настоящем обзоре. Адресация непосредственных данных и литеральных констант обычно рассматривается как один из методов адресации памяти (хотя значения данных, к которым в этом случае производятся обращения, являются частью самой команды и обрабатываются в общем потоке команд). Адресация регистров, как правило, рассматривается отдельно. В данном разделе методы адресации, связанные со счетчиком команд (адресация относительно счетчика команд) рассматриваются отдельно. Этот вид адресации используется главным образом для определения программных адресов в командах передачи управления.
На рисунке на примере команды сложения (Add) приведены наиболее употребительные названия методов адресации, хотя при описании архитектуры в документации разные производители используют разные названия для этих методов. На этом рисунке знак "(" используется для обозначения оператора присваивания, а буква М обозначает память (Memory). Таким образом, M[R1] обозначает содержимое ячейки памяти, адрес которой определяется содержимым регистра R1.
Использование сложных методов адресации позволяет существенно сократить количество команд в программе, но при этом значительно увеличивается сложность аппаратуры. Возникает вопрос, а как часто эти методы адресации используются в реальных программах? На рис. 4.2 представлены результаты измерений частоты использования различных методов адресации на примере трех популярных программ (компилятора с языка Си GCC, текстового редактора TeX и САПР Spice), выполненных на компьютере VAX.
Метод адресации |
Пример команды |
Смысл команды метода Использование |
Регистровая |
Add R4,R3 |
R4(R4+R5 Требуемое значение в регистре |
Непосредственная или литеральная |
Add R4,#3 |
R4(R4+3 Для задания констант |
Базовая со смещением |
Add R4,100(R1) |
R4(R4+M[100+R1] Для обращения к локальным переменным |
Косвенная регистровая |
Add R4,(R1) |
R4(R4+M[R1] Для обращения по указателю или вычисленному адресу |
Индексная |
Add R3,(R1+R2) |
R3(R3+M[R1+R2] Иногда полезна при работе с массивами: R1 - база, R3 - индекс |
Прямая или абсолютная |
Add R1,(1000) |
R1(R1+M[1000] Иногда полезна для обращения к статическим данным |
Косвенная |
Add R1,@(R3) |
R1(R1+M[M[R3]] Если R3-адрес указателя p, то выбирается значение по этому указателю |
Автоинкрементная |
Add R1,(R2)+ |
R1(R1+M[R2] R2(R2+d Полезна для прохода в цикле по массиву с шагом: R2 - начало массива В каждом цикле R2 получает приращение d |
Автодекрементная |
Add R1,(R2)- |
R2(R2-d R1(R1+M[R2] Аналогична предыдущей Обе могут использоваться для реализации стека |
Базовая индексная со смещением и масштабированием |
Add R1,100(R2)[R3] |
R1( R1+M[100]+R2+R3*d Для индексации массивов |
Рис. 4.1. Методы адресации
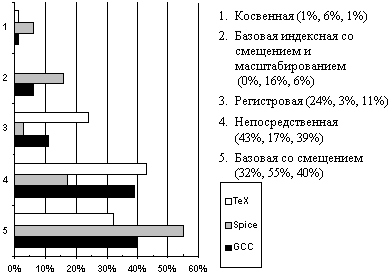
Рис. 4.2. Частота использования различных методов адресации на программах TeX, Spice, GCC
Из этого рисунка видно, что непосредственная адресация и базовая со смещением доминируют.
При этом основной вопрос, который возникает для метода базовой адресации со смещением, связан с длиной (разрядностью) смещения. Выбор длины смещения в конечном счете определяет длину команды. Результаты измерений показали, что в подавляющем большинстве случаев длина смещения не превышает16 разрядов.
Этот же вопрос важен и для непосредственной адресации. Непосредственная адресация используется при выполнении арифметических операций, операций сравнения, а также для загрузки констант в регистры. Результаты анализа статистики показывают, что в подавляющем числе случаев 16 разрядов оказывается вполне достаточно (хотя для вычисления адресов намного реже используются и более длинные константы).
Важным вопросом построения любой системы команд является оптимальное кодирование команд. Оно определяется количеством регистров и применяемых методов адресации, а также сложностью аппаратуры, необходимой для декодирования. Именно поэтому в современных RISC-архитектурах используются достаточно простые методы адресации, позволяющие резко упростить декодирование команд. Более сложные и редко встречающиеся в реальных программах методы адресации реализуются с помощью дополнительных команд, что вообще говоря приводит к увеличению размера программного кода. Однако такое увеличение длины программы с лихвой окупается возможностью простого увеличения тактовой частоты RISC-процессоров. Этот процесс мы можем наблюдать сегодня, когда максимальные тактовые частоты практически всех RISC-процессоров (Alpha, R4400, Hyper SPARC и Power2) превышают тактовую частоту, достигнутую процессором Pentium.
Типы команд
Команды традиционного машинного уровня можно разделить на несколько типов, которые показаны на рис. 4.3.
Тип операции |
Примеры |
Арифметические и логические |
Целочисленные арифметические и логические операции: сложение, вычитание, логическое сложение, логическое умножение и т.д. |
Пересылки данных |
Операции загрузки/записи |
Управление потоком команд |
Безусловные и условные переходы, вызовы процедур и возвраты |
Системные операции |
Системные вызовы, команды управления виртуальной памятью и т.д. |
Операции с плавающей точкой |
Операции сложения, вычитания, умножения и деления над вещественными числами |
Десятичные операции |
Десятичное сложение, умножение, преобразование форматов и т.д. |
Операции над строками |
Пересылки, сравнения и поиск строк |
Рис. 4.3. Основные типы команд
Команды управления потоком команд
В английском языке для указания команд безусловного перехода, как правило, используется термин jump, а для команд условного перехода - термин branch, хотя разные поставщики необязательно придерживаются этой терминологии. Например компания Intel использует термин jump и для условных, и для безусловных переходов. Можно выделить четыре основных типа команд для управления потоком команд: условные переходы, безусловные переходы, вызовы процедур и возвраты из процедур.
Частота использования этих команд по статистике примерно следующая. В программах доминируют команды условного перехода. Среди указанных команд управления на разных программах частота их использования колеблется от 66 до 78%. Следующие по частоте использования - команды безусловного перехода (от 12 до 18%). Частота переходов на выполнение процедур и возврата из них составляет от 10 до 16%.
При этом примерно 90% команд безусловного перехода выполняются относительно счетчика команд. Для команд перехода адрес перехода должен быть всегда заранее известным. Это не относится к адресам возврата, которые не известны во время компиляции программы и должны определяться во время ее работы. Наиболее простой способ определения адреса перехода заключается в указании его положения относительно текущего значения счетчика команд (с помощью смещения в команде), и такие переходы называются переходами относительно счетчика команд. Преимуществом такого метода адресации является то, что адреса переходов, как правило, расположены недалеко от текущего адреса выполняемой команды и указание относительно текущего значения счетчика команд требует небольшого количества бит в смещении. Кроме того, использование адресации относительно счетчика команд позволяет программе выполняться в любом месте памяти, независимо от того, куда она была загружена. То есть этот метод адресации позволяет автоматически создавать перемещаемые программы.
Реализация возвратов и переходов по косвенному адресу, в которых адрес не известен во время компиляции программы, требует методов адресации, отличных от адресации относительно счетчика команд. В этом случае адрес перехода должен определяться динамически во время работы программы. Наиболее простой способ заключается в указании регистра для хранения адреса возврата, либо для перехода может разрешаться любой метод адресации для вычисления адреса перехода.
Одним из ключевых вопросов реализации команд перехода состоит в том, насколько далеко целевой адрес перехода находится от самой команды перехода? И на этот вопрос статистика использования команд дает ответ: в подавляющем большинстве случаев переход идет в пределах 3 - 7 команд относительно команды перехода, причем в 75% случаев выполняются переходы в направлении увеличения адреса, т.е. вперед по программе.
Поскольку большинство команд управления потоком команд составляют команды условного перехода, важным вопросом реализации архитектуры является определение условий перехода. Для этого используются три различных подхода. При первом из них в архитектуре процессора предусматривается специальный регистр, разряды которого соответствуют определенным кодам условий. Команды условного перехода проверяют эти условия в процессе своего выполнения. Преимуществом такого подхода является то, что иногда установка кода условия и переход по нему могут быть выполнены без дополнительных потерь времени, что, впрочем, бывает достаточно редко. А недостатками такого подхода является то, что, во-первых, появляются новые состояния машины, за которыми необходимо следить (упрятывать при прерывании и восстанавливать при возврате из него). Во-вторых, и что очень важно для современных высокоскоростных конвейерных архитектур, коды условий ограничивают порядок выполнения команд в потоке, поскольку их основное назначение заключается в передаче кода условия команде условного перехода.
Второй метод заключается в простом использовании произвольного регистра (возможно одного выделенного) общего назначения. В этом случае выполняется проверка состояния этого регистра, в который предварительно помещается результат операции сравнения. Недостатком этого подхода является необходимость выделения в программе для анализа кодов условий специального регистра.
Третий метод предполагает объединение команды сравнения и перехода в одной команде. Недостатком такого подхода является то, что эта объединенная команда довольно сложна для реализации (в одной команде надо указать и тип условия, и константу для сравнения и адрес перехода). Поэтому в таких машинах часто используется компромиссный вариант, когда для некоторых кодов условий используются такие команды, например, для сравнения с нулем, а для более сложных условий используется регистр условий. Часто для анализа результатов команд сравнения для целочисленных операций и для операций с плавающей точкой используется разная техника, хотя это можно объяснить и тем, что в программах количество переходов по условиям выполнения операций с плавающей точкой значительно меньше общего количества переходов, определяемых результатами работы целочисленной арифметики.
Одним из наиболее заметных свойств большинства программ является преобладание в них сравнений на условие равно/неравно и сравнений с нулем. Поэтому в ряде архитектур такие команды выделяются в отдельный поднабор, особенно при использовании команд типа "сравнить и перейти".
Говорят, что переход выполняется, если истинным является условие, которое проверяет команда условного перехода. В этом случае выполняется переход на адрес, заданный командой перехода. Поэтому все команды безусловного перехода всегда выполняемые. По статистике оказывается, что переходы назад по программе в большинстве случаев используются для организации циклов, причем примерно 60% из них составляют выполняемые переходы. В общем случае поведение команд условного перехода зависит от конкретной прикладной программы, однако иногда сказывается и зависимость от компилятора. Такие зависимости от компилятора возникают вследствие изменений потока управления, выполняемого оптимизирующими компиляторами для ускорения выполнения циклов.
Вызовы процедур и возвраты предполагают передачу управления и возможно сохранение некоторого состояния. Как минимум, необходимо уметь где-то сохранять адрес возврата. Некоторые архитектуры предлагают аппаратные механизмы для сохранения состояния регистров, в других случаях предполагается вставка в программу команд самим компилятором. Имеются два основных вида соглашений относительно сохранения состояния регистров. Сохранение вызывающей (caller saving) программой означает, что вызывающая процедура должна сохранять свои регистры, которые она хочет использовать после возврата в нее. Сохранение вызванной процедурой предполагает, что вызванная процедура должна сохранить регистры, которые она собирается использовать. Имеются случаи, когда должно использоваться сохранение вызывающей процедурой для обеспечения доступа к глобальным переменным, которые должны быть доступны для обеих процедур.
Типы и размеры операндов
Имеется два альтернативных метода определения типа операнда. В первом из них тип операнда может задаваться кодом операции в команде. Это наиболее употребительный способ задания типа операнда. Второй метод предполагает указание типа операнда с помощью тега, который хранится вместе с данными и интерпретируется аппаратурой во время выполнения операций над данными. Этот метод использовался, например, в машинах фирмы Burroughs, но в настоящее время он практически не применяется и все современные процессоры пользуются первым методом.
Обычно тип операнда (например, целый, вещественный с одинарной точностью или символ) определяет и его размер. Однако часто процессоры работают с целыми числами длиною 8, 16, 32 или 64 бит. Как правило целые числа представляются в дополнительном коде. Для задания символов (1 байт = 8 бит) в машинах компании IBM используется код EBCDIC, но в машинах других производителей почти повсеместно применяется кодировка ASCII. Еще до сравнительно недавнего времени каждый производитель процессоров пользовался своим собственным представлением вещественных чисел (чисел с плавающей точкой). Однако за последние несколько лет ситуация изменилась. Большинство поставщиков процессоров в настоящее время для представления вещественных чисел с одинарной и двойной точностью придерживаются стандарта IEEE 754.
В некоторых процессорах используются двоично кодированные десятичные числа, которые представляются в в упакованном и неупакованном форматах. Упакованный формат предполагает, что для кодирования цифр 0-9 используются 4 разряда и что две десятичные цифры упаковываются в каждый байт. В неупакованном формате байт содержит одну десятичную цифру, которая обычно изображается в символьном коде ASCII.
В большинстве процессоров, кроме того, реализуются операции над цепочками (строками) бит, байт, слов и двойных слов.
Лекция 4. Центральный процессор ЭВМ
Принципы построения элементарного процессора. Операционные устройства. Управляющие устройства. Структура базового микропроцессора. Взаимодействие элементов при работе микропроцессора.
Принципы построения элементарного процессора
Ранее, при рассмотрении обобщенной структуры ЭВМ, отмечалось, что основным устройством, непосредственно осуществляющим переработку поступающей в ЭВМ информации, является процессор (в больших ЭВМ – центральный процессор). Естественно, что конкретные типы ЭВМ содержат в своем составе процессоры, построенные по различным схемам, и процессоры больших ЭВМ существенно отличаются от процессоров мини- и микроЭВМ (о суперЭВМ и говорить не приходится). Однако основные принципы построения процессоров, в общем-то, одинаковые, причем наиболее наглядно их можно продемонстрировать на примере простейшего микропроцессора. Это оправдано и с той точки зрения, что инженер-разработчик радиоэлектронной аппаратуры или аппаратов автоматического управления имеет дело не с большими ЭВМ, а с микропроцессорными комплектами и построенными на их базе мини- и микроЭВМ. Ввиду этого рассмотрев общие вопросы построения ЭВМ, более подробно остановимся на обобщенной структуре гипотетического микропроцессора.
Ранее рассматривались действия над числами (сложение, вычитание, умножение), представленными в различной форме. Было подчеркнуто, что все эти действия осуществляются с помощью элементарных операций, выполняемых в определенной последовательности.
К таким элементарным операциям относятся:
запись числа в регистр;
инвертирование содержимого разрядов регистра;
пересылка содержимого регистров;
сдвиг содержимого регистра;
сложение кодов;
поразрядные логические операции или анализ разрядов;
операция счета с+1 или с-1 (инкремент или декремент).
Пример.
Операция умножения реализуется с помощью:
анализа разряда множителя;
суммирования;
сдвига.
Все эти действия выполняются в устройстве, называемом процессором, которое состоит из двух устройств – операционного (ОУ) и управляющего (УУ).
ОУ – выполняет указанные элементарные операции.
УУ – управляет ОУ, задавая необходимую последовательность выполнения этих операций.
Это соответствует принципу В.М. Глушкова, что в любом устройстве обработки цифровой информации можно выделить операционный и управляющий блоки.
В качестве узлов УУ и ОУ включают в себя регистры, счетчики, сумматоры, мультиплексоры, дешифраторы и т.д., т.е. устройства импульсной цифровой техники. Кроме того, нормальное функционирование процессора и всей ЭВМ возможно только при наличии высокостабильных импульсных последовательностей, формируемых, как правило, из одной импульсной последовательности, вырабатываемой кварцевым генератором. Эти тактовые импульсные последовательности синхронизируют работу узлов процессора, а иногда и всей ЭВМ.
Обобщенная структура любого процессора изображена на рис. 3.1.
Каждая элементарная операция, выполняемая в одном из узлов ОУ в течение одного тактового периода, называется микрооперацией.
В определенные тактовые периоды одновременно могут выполняться несколько микроопераций, например: R2 0, Сч (Сч) – 1 и т.д. Такая совокупность непротиворечивых микроопераций называется микрокомандой, а набор микрокоманд, предназначенный для решения задачи, называется микропрограммой.
Если в ОУ предусмотрена возможность выполнения n различных микроопераций, то из УУ должно выходить n управляющих цепей S1,...,Sn, каждая из которых соответствует своей микрооперации. В силу того что УУ определяет микропрограмму, т.е. какие и в какой временной последовательности должны выполняться микрооперации, оно получило название микропрограммного автомата. Соответственно ОУ часто называют операционным автоматом.

Формирование управляющих сигналов S1,...,Sn может зависеть как от внешних сигналов КОП (команды ассемблера), так и от состояния узлов ОУ, определяемого известительными сигналами признаков состояния P1,...,Pm, поступающими с выхода ОУ на соответствующие входы УУ.
Как уже отмечалось, ОУ выполняет над исходными данными различные арифметические и логические операции, поэтому ОУ наиболее часто называют арифметико-логическим устройством, или АЛУ.
Деление любого процессора на программный и операционный автоматы достаточно очевидно и не вызывает особых трудностей в понимании. Однако структурные схемы даже простейших реальных процессоров, помимо АЛУ и УУ, содержат еще ряд узлов (регистров, счетчиков, дешифраторов), которые вроде бы не относятся ни к АЛУ, ни к УУ. Для устранения путаницы в дальнейшем материале необходимо сделать ряд замечаний:
В абсолютном большинстве случаев устройства обработки цифровой информации имеют многоуровневую структуру, т.е. построены по принципу "матрешки". Это означает, что УУ и ОУ могут сами распадаться на пары УУ' и ОУ', которые, в свою очередь, также могут распадаться на соответствующие УУ и ОУ. Все зависит от степени детализации рассмотрения данного цифрового устройства. Этот принцип многоуровневости справедлив для всех устройств ЭВМ.
Действительно, если рассматривать процессор в целом и делить его на УУ и ОУ, то совершенно безразлично, как выполняются арифметико-логические операции в ОУ – с помощью очень сложных логических схем или с помощью простой логики, работающей под управлением какого-либо вспомогательного УУ. Аналогичные рассуждения справедливы и для УУ.
Так, например, центральный процессор больших ЭВМ общего назначения середины 70-х годов разбивался на 4-5 уровней, на каждом из которых можно выделить свое УУ и ОУ. Современные процессоры имеют еще более сложную структуру.
Более того, эти рассуждения справедливы в целом для ЭВМ, которую можно разложить на ряд виртуальных (кажущихся) машин и с каждой работать на соответствующем уровне. В общем случае современные универсальные ЭВМ имеют шесть уровней:
у
 ровень
проблемно-ориентированного языка;
ровень
проблемно-ориентированного языка;процедурно-ориентированный язык;
ассемблерный уровень (язык ассемблера);
уровень операционной системы (язык операционной системы);
т
 радиционный
машинный уровень (язык машинных команд);
радиционный
машинный уровень (язык машинных команд);микропрограммный уровень (язык микрокоманд).
Машинные языки двух нижних уровней являются цифровыми, и программы на них состоят из длинных числовых последовательностей, очень неудобных для человека, но понятных машине. Все более высокие уровни содержат слова и аббревиатуру, что более удобно для человека.
Из сказанного следует, что только самые простейшие процессоры имеют один уровень и могут быть в чистом виде разложены на УУ и ОУ, состоящие из комбинационных логических схем, способных выполнять элементарные арифметико-логические операции.
В настоящее время нет строгого определения АЛУ, что вызывает некоторую путаницу при пользовании различной литературой. АЛУ обычно обозначают так, как показано на рис. 3.2. При этом одни авторы подразумевают под АЛУ только комбинационные логические схемы, способные выполнять операции двоичного суммирования (т.е. фактически двоичный сумматор), другие – целый комплекс схем для выполнения арифметико-логических операций, который сам может быть разложен на УУ и ОУ.
Из сказанного следует вывод, что в общем случае понятия микрооперации и микропрограммы относительны и требуют конкретизации уровня рассмотрения процессора, поскольку один такт верхнего уровня может включать в себя несколько тактов нижнего уровня.
Для устранения путаницы при изучении основных принципов построения элементарных процессоров будем считать:
процессор имеет один уровень;
процессор пользуется одной тактовой последовательностью;
значок АЛУ (см. рис. 3.2) обозначает комплекс комбинационных схем, способных выполнять двоичное суммирование, сдвиг двоичного числа, простейшие поразрядные логические операции;
узлы микропроцессора, не относящиеся непосредственно к схеме управления, будем считать вспомогательными узлами АЛУ, или, точнее, узлами, обеспечивающими нормальное функционирование АЛУ.