

2.6. Методы классификации. Алгоритмы классификации.
Системы классификации, построенные с использованием методов обучения, реализуются с помощью различных алгоритмов, в большей или меньшей степени эвристических. Среди множества таких алгоритмов рассмотрим три: алгоритм максимина, алгоритм К-средних, алгоритм ИЗОДАТА.
2.6.1. Алгоритм максимина
Алгоритм Максимина используют для
автоматического нахождения экземпляров
классов на базе обучающей выборки
объёмом
![]() и распределения образов по классам.
При этом неизвестны, ни количество
классов, ни экземпляры классов. Идея
данного алгоритма заключается в
следующем. В качестве экземпляра первого
класса выбирают произвольно один из
образов. Пусть это будет образ
и распределения образов по классам.
При этом неизвестны, ни количество
классов, ни экземпляры классов. Идея
данного алгоритма заключается в
следующем. В качестве экземпляра первого
класса выбирают произвольно один из
образов. Пусть это будет образ
![]() .
Вычисляют расстояния между экземпляром
первого класса и всеми оставшимися
образами -
.
Вычисляют расстояния между экземпляром
первого класса и всеми оставшимися
образами -
![]() .
Среди этих расстояний найдем наибольшее
.
Среди этих расстояний найдем наибольшее
![]() .
.
О чевидно,
что образ
чевидно,
что образ
![]() ,
расположенный на наибольшем расстоянии,
является экземпляром второго класса:
,
расположенный на наибольшем расстоянии,
является экземпляром второго класса:
![]() .
Обозначим через
.
Обозначим через
 подмножество образов не являющихся
экземплярами классов. Вычислим расстояния
между экземпляром второго класса и
всеми оставшимися образами:
подмножество образов не являющихся
экземплярами классов. Вычислим расстояния
между экземпляром второго класса и
всеми оставшимися образами:
![]() .
Для дальнейшего, необходимо установить
решающее правило, которое, с одной
стороны, обеспечивало бы распределение
образов по классам, а с другой – создание
новых классов. Сформулируем его следующим
образом. Обозначим через
.
Для дальнейшего, необходимо установить
решающее правило, которое, с одной
стороны, обеспечивало бы распределение
образов по классам, а с другой – создание
новых классов. Сформулируем его следующим
образом. Обозначим через
![]() пороговое значение расстояния. При этом
параметр
пороговое значение расстояния. При этом
параметр
![]() - это радиус сферы, ограничивающей класс,
в центре которой расположен экземпляр
класса. На рис.2.17 изображены на плоскости
два класса и их границы – окружности с
радиусом равным
- это радиус сферы, ограничивающей класс,
в центре которой расположен экземпляр
класса. На рис.2.17 изображены на плоскости
два класса и их границы – окружности с
радиусом равным
![]() .
Образы, принадлежащие каждому из классов,
находятся внутри этих окружностей. При
этом если минимальное расстояние между
образом и экземплярами классов меньше
порогового
.
Образы, принадлежащие каждому из классов,
находятся внутри этих окружностей. При
этом если минимальное расстояние между
образом и экземплярами классов меньше
порогового
![]() ,
то данный образ принадлежит одному из
классов. В случае, когда образ находится
за пределами границ классов, то его,
очевидно, необходимо рассматривать как
экземпляр нового класса (см. рис. 2.17.).
Для того, что бы выполнить классификацию
для каждого образа найдем наименьшие
расстояния между образом и экземплярами
классов. Среди этих наименьших расстояний
найдем наибольшее (этим и обусловлено
название алгоритма) и сравним его с
пороговым расстоянием. Если наибольшее
из наименьших расстояний больше
порогового, т.е. образ расположен за
границами классов, то данный образ
является экземпляром нового класса.
Если наибольшее из наименьших расстояний
меньше порога, то необходимо распределить
объекты по классам, по принципу наименьшего
расстояния. При этом задача классификации
будет выполнена.
,
то данный образ принадлежит одному из
классов. В случае, когда образ находится
за пределами границ классов, то его,
очевидно, необходимо рассматривать как
экземпляр нового класса (см. рис. 2.17.).
Для того, что бы выполнить классификацию
для каждого образа найдем наименьшие
расстояния между образом и экземплярами
классов. Среди этих наименьших расстояний
найдем наибольшее (этим и обусловлено
название алгоритма) и сравним его с
пороговым расстоянием. Если наибольшее
из наименьших расстояний больше
порогового, т.е. образ расположен за
границами классов, то данный образ
является экземпляром нового класса.
Если наибольшее из наименьших расстояний
меньше порога, то необходимо распределить
объекты по классам, по принципу наименьшего
расстояния. При этом задача классификации
будет выполнена.
Рассмотрим словесное описание этого алгоритма.
-
Задать количество образов в выборке -
 и значения их существенных признаков.
Выбрать метрику для вычисления
расстояний.
и значения их существенных признаков.
Выбрать метрику для вычисления
расстояний. -
Из совокупности образов (обучающей выборки), произвольным образом выбрать один, в качестве экземпляра первого класса. Пусть это будет образ
 ,
т.е.
,
т.е. .
Положить
.
Положить
 ,
т.е. задать количество созданных классов.
,
т.е. задать количество созданных классов. -
Вычислить расстояния между экземпляром первого класса
 и всеми оставшимися образами -
и всеми оставшимися образами -
 .
Из всей совокупности расстояний выбрать
наибольшее
.
Из всей совокупности расстояний выбрать
наибольшее
![]() .
.
При этом образ
![]() ,
расположенный на наибольшем расстоянии
от экземпляра класса
,
расположенный на наибольшем расстоянии
от экземпляра класса
![]() представляет другой класс.
представляет другой класс.
-
Вычислить величину порогового расстояния, равную половине расстояния между экземплярами классов
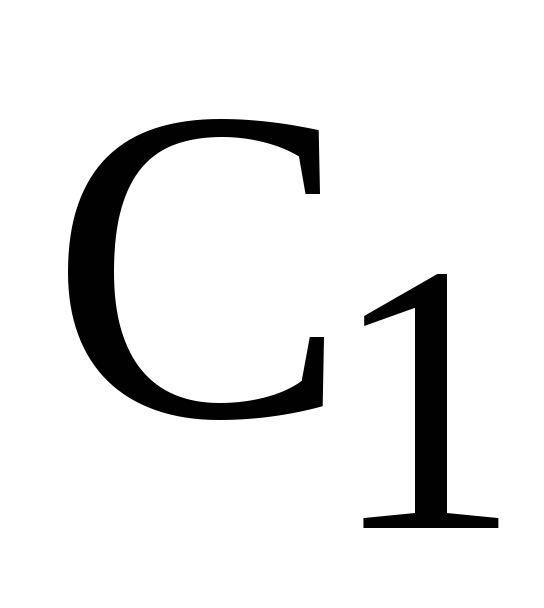 и
и
 :
:
![]() .
.
-
Увеличить число классов на единицу:
 .
. -
Выбрать образ
 в качестве экземпляра следующего класса
в качестве экземпляра следующего класса
 .
. -
Вычислить расстояния между экземплярами классов
 и всеми оставшимися образами
и всеми оставшимися образами

-
Найти наименьшие расстояния между образом и экземплярами классов
 :
:
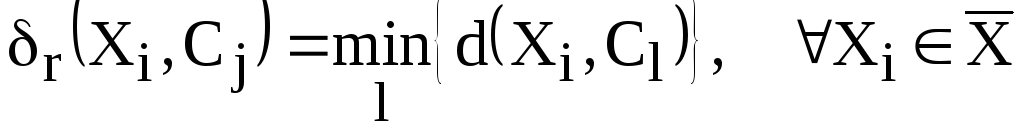 и упорядочить их в порядке убывания.
Установить количество образов, которые
не являются экземплярами классов
и упорядочить их в порядке убывания.
Установить количество образов, которые
не являются экземплярами классов
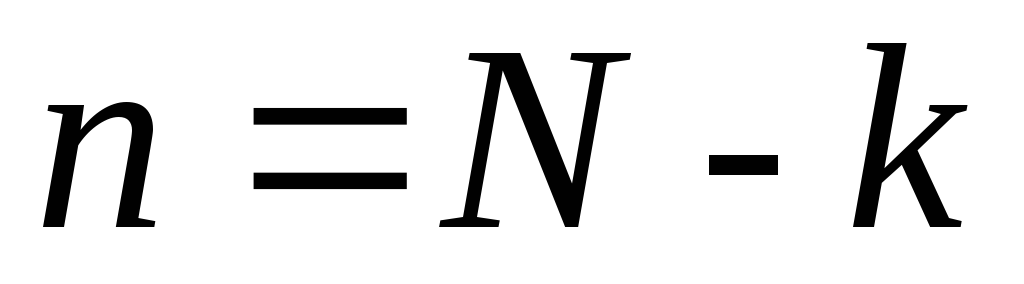 ,
и положить
,
и положить
 .
. -
Если наибольшее из наименьших расстояний
 ,
то к уже имеющимся классам добавляется
новый экземпляр класса
,
то к уже имеющимся классам добавляется
новый экземпляр класса
 .
Предварительно необходимо уточнить
значение величины
.
Предварительно необходимо уточнить
значение величины
 ,
например, следующим образом: находят
половину среднего расстояния между
всеми экземплярами классов. Затем
возвращаются к шагу 5.
,
например, следующим образом: находят
половину среднего расстояния между
всеми экземплярами классов. Затем
возвращаются к шагу 5. -
Если
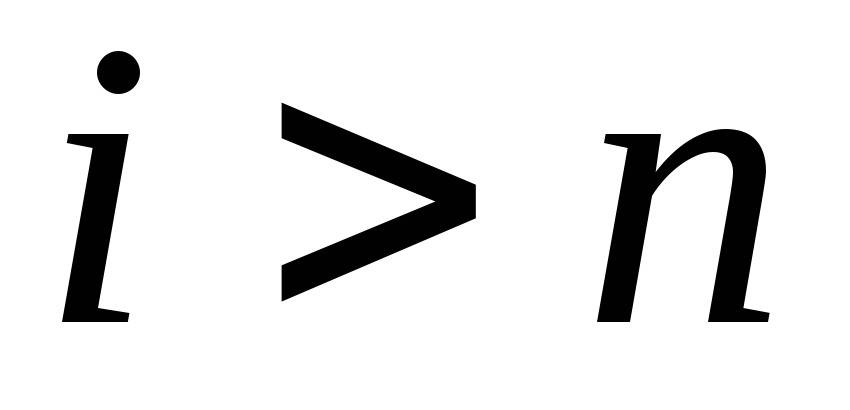 ,
то алгоритм закончен.
,
то алгоритм закончен.
-
Из массива
 определить номер образа и номер класса.
Отнести образ
определить номер образа и номер класса.
Отнести образ
 к классу
к классу
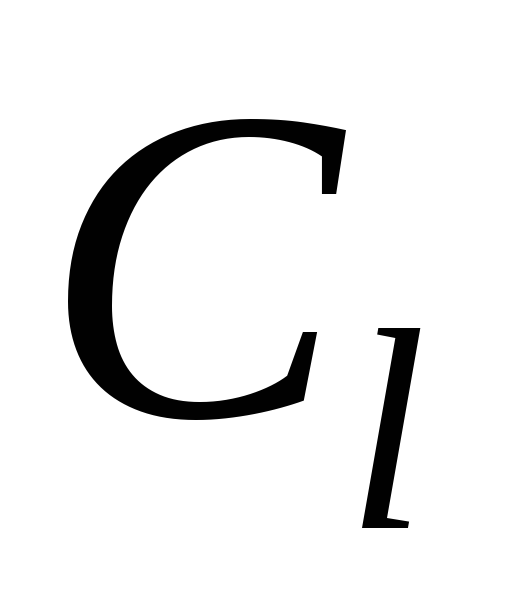 ,
т.е.
,
т.е.
 .
Увеличить счетчик классифицированных
образов на единицу
.
Увеличить счетчик классифицированных
образов на единицу
 и перейти к шагу 10.
и перейти к шагу 10.
Задача классификации считается выполненной, если количество экземпляров классов не изменяется, а все образы распределены по классам.
Рассмотрим реализацию данного алгоритма на примере. Пусть в обучающей выборке шесть объектов, а количество существенных признаков объектов равно двум.
Для удобства описания вычислений, будем использовать четыре таблицы.
Первая – это таблица значений существенных
признаков объектов
![]() (номер строки – номер объекта номер
столбца – номер существенного признака).
(номер строки – номер объекта номер
столбца – номер существенного признака).
-
Y(i,j)
1
2
1
4
12
2
4
14
3
13
11
4
16
14
5
6
4
6
7
4
Вторая таблица – таблица пометок объектов. Если объект – это экземпляр класса, то ему присваивают отрицательную пометку (номер экземпляра класса с отрицательным знаком) или положительную пометку равную номеру класса, к которому отнесён данный объект.
-
Pm(i)
1
2
3
4
5
6
Третья таблица – это расстояния в выбранной метрике между экземплярами классов и непомеченными объектами.
-
d(i,j)
1
2
3
4
5
6
1
2

6
Четвертая таблица – это таблица наименьших расстояний между объектом, который нужно классифицировать, и экземплярами классов. Она имеет следующую структуру:
-

1
2
3
1
2

6
Номер строки таблицы – это порядковый номер экземпляра класса; первый столбец – значение минимального расстояния; второй столбец – порядковый номер непомеченного объекта, который находится на минимальном расстоянии от данного экземпляра класса; третий столбец – номер этого класса.
Выберем
в качестве экземпляра первого класса
первый объект:
![]() .
В таблице пометок, первому элементу
присвоим пометку
.
В таблице пометок, первому элементу
присвоим пометку
![]() .
.
-
Pm(i)
1
2
3
4
5
6
-1
Вычислим
расстояния
![]() между экземпляром класса k=1 и всеми
непомеченными объектами с номерами
между экземпляром класса k=1 и всеми
непомеченными объектами с номерами
![]() в метрике Манхеттена.
в метрике Манхеттена.
![]()
Занесем
полученные расстояния в таблицу
![]() .
.
-
d(i,j)
№ об.
№ кл.
1
2
3
4
5
6
1
2
10
14
10
11
Находим наибольшее расстояние между экземпляром класса и непомеченными объектами
![]() ,
,
запоминаем
номер этого объекта
![]() .
.
Выберем этот объект в качестве экземпляра
следующего класса
![]() .
Присвоим объекту
.
Присвоим объекту
![]() пометку
пометку
![]() .
.
-
Pm(i)
1
2
3
4
5
6
-1
-2
Вычислим пороговое значение расстояния
![]() .
.
Вычислим
расстояния между экземпляром нового
класса и всеми непомеченными объектами
![]() и занесем данные в таблицу
и занесем данные в таблицу
-
d(i,j)
№ об.
№ кл.
1
2
3
4
5
6
1
2
10
14
10
11
2
12
6
20
19
Для всех объектов находим наименьшие расстояния между непомеченным объектом экземплярами классов:
![]()
Занесем
эти расстояния, номера соответствующих
объектов и классов в таблицу
![]() .
В рассматриваемом примере - это
.
В рассматриваемом примере - это
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ...
...
-

1
2
3
1
2
2
1
2
6
3
2
3
10
5
1
4
11
6
1
Упорядочим данные в таблице в порядке убывания расстояний
-

1
2
3
1
11
6
1
2
10
5
1
3
6
3
2
1
2
2
1
Сравним
![]() с порогом. Если значение
с порогом. Если значение
![]() ,
то увеличим количество классов на
единицу
,
то увеличим количество классов на
единицу
![]() и объекту с номером
и объекту с номером
![]() присвоим пометку
присвоим пометку
![]() .
.
Таблица пометок будет иметь вид
-
Pm(i)
1
2
3
4
5
6
-1
-2
-3
Уточним значение порогового расстояния
![]() .
.
Тогда
![]() .
.
Вычисляем
расстояния от экземпляра класса
![]() до всех непомеченных объектов.
до всех непомеченных объектов.
-
d(i,j)
№ об.
№ кл.
1
2
3
4
5
6
1
2
10
14
10
11
2
12
6
20
19
3
13
13
1
Находим
наименьшие расстояния между непомеченными
объектами и экземплярами классов:
![]() .Упорядочим
их в порядке убывания и занесем в таблицу
.Упорядочим
их в порядке убывания и занесем в таблицу
-

1
2
3
1
6
3
2
2
2
2
1
3
1
5
3
Все значения наименьших расстояний,
как это следует из таблицы, меньше
порога. Распределим объекты по классам:
объект с номером
![]() принадлежит к классу с номером
принадлежит к классу с номером
![]() ,
т.е.
,
т.е.
![]() ,
и т.д. Занесем соответствующие пометки
в таблицу пометок.
,
и т.д. Занесем соответствующие пометки
в таблицу пометок.
-
Pm(i)
1
2
3
4
5
6
-1
1
2
-2
3
-3
Поскольку в таблице пометок больше нет непомеченных объектов, то, следовательно, алгоритм закончен. Таблица пометок содержит информацию об экземплярах классов и распределении объектов между этими классами.