

Бодалев А.А. - Общая психодиагностика
.pdfТесты первого типа плохо дифференцируют испытуемых с низ-
ким уровнем способностей: все эти испытуемые получают примерно одинаковый низкий балл. Тесты второго типа, наоборот, хуже диффе-
ренцируют испытуемых с высоким уровнем способностей.
Если пункты обладают оптимальным уровнем трудности(силы),
то кривая распределения зависит от того, насколько пункты однород-
ны. Если пункты разнородны (исход по одному пункту не предопре-
деляет исход по другому), то мы получаем тест в виде последователь-
ности независимых испытаний Бернулли. Как известно из математи-
ческой статистики, при достаточно большом количестве независимых испытаний с двумя разновероятными исходами кривая биномиального распределения (кривая суммарного балла) по закону больших чисел
автоматически приближается к кривой нормального распределения
(центральная предельная теорема МуавраЛапласа). Если тест со-
держит разнородные задания примерно равного уровня трудности
(именно такие задания и подбираются для измерения интегральных свойств личности), то нормальность распределения суммарных баллов возникает автоматически - как артефакт самой процедуры подсчета суммарных баллов. При этом, конечно, форма кривой распределения баллов не позволяет говорить о реальной форме распределения изме-
ряемого свойства, каким оно является само по себе - в широкой попу-
ляции испытуемых. Нормальность распределения есть артефакт, пря-
мое следствие направленного отбора пунктов с заданными свойствами.
Если подбираются пункты, тесно положительно коррелирующие
между собой (испытания не |
являются статистически независимыми), |
то в распределении баллов |
возникает отрицательный эксцесс(рис. |
3,а), Максимальных значений отрицательный эксцесс достигает по ме-
ре возрастания вогнутости вершины распределениядо образования двух вершин -двух мод (с «провалом» между ними -рис. 3,6). Бимо-
дальная конфигурация распределения баллов указывает на то, что вы-
борка испытуемых разделилась на две категории(с плавными пере-
ходами между ними): одни справились с большинством заданий(со-
гласились с большинством «ли-вопросов»), другие - не справились.
81
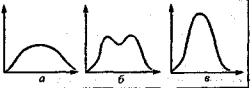
Рис. 3. Отрицательные (а, б) положительный (в) эксцессы
распределения тестовых баллов
Такая конфигурация распределения свидетельствует о том, что в основе пунктов лежит какой-то один общий им всем признак, соот-
ветствующий определенному свойству испытуемых: если у испытуе-
мых есть это свойство (способность, умение, знание), то они справля-
ются с большинством пунктов, если этого свойства нет - то не справ-
ляются. В некоторых редких ситуациях пункты могут отрицательно коррелировать друг с другом. В этом случае на кривой возникает по-
ложительный эксцесс (рис. 3, в): вся масса эмпирических точек соби-
рается вблизи среднего значения. Такое возможно в двух случаях: 1)
когда ключ составлен неверно -объединены при подсчете отрицатель-
но связанные признаки, которые обусловливают взаимоуничтожение баллов; 2) когда испытуемые применяют, разгадав направленность оп-
росника, специальную тактику «медианного балла» - искусственно ба-
лансируют ответы «за» и «против» одного из полюсов измеряемого качества.
Итак, когда в качестве единственного эталона измерения психо-
диагностами рассматривается сам тест, то в качестве меры измеряе-
мого свойства выступает положение балла на кривой распределения.
Применяется процентильная шкала. В качестве универсальной меры,
пригодной для разных (по своей качественной направленности и ко-
личеству пунктов) тестов, используется «процентильная мера». Про-
центилъ — процент испытуемых из выборки стандартизации, которые получили равный или более низкий балл, чем балл данного испы-
туемого. Таким образом, в качестве источника данной меры выступает нормативная выборка (выборка стандартизации), на которой построе-
но нормативное распределение тестовых баллов. Процентильные шка-
лы лежат в основе всех традиционных шкал, применяемых в тестоло-
гии (Т-очки MMPI, баллы IQ, стены 16 PF и др.).
82
Подчеркнем, что с точки зрения теории измерений, процентиль-
ные шкалы относятся к порядковым шкалам: они дают информацию о том, у кого из испытуемых сильнее выражено измеряемое свойство, но не позволяют говорить о том, во сколько раз сильнее. Для того чтобы строить на базе таких шкал количественный прогноз, нужно повысить уровень измерения (популярное изложение представлений о теории измерений см. в книге: Клигер С. А. и др., 1978). Переход к шкалам интервалов производят либо на базе эмпирического распределения,
либо на базе произвольной модели теоретического распределения. В
абсолютном большинстве случаев в роли такой теоретической модели оказывается модель нормального распределения(хотя в принципе может быть использована любая модель).
В целом кроме статистических, процентильных шкал следует от-
личать нередко используемые в дифференциальной психометрике еще
2 вида шкал (и соответственно 2 вида тестовых норм). Это, во-первых,
то, что можно условно назвать «абсолютными тестовыми нормами» —
в роли шкалы для вынесения диагноза выступает сама шкала «сырых» очков, во-вторых, «критериальные» тестовые нормы. Применение та-
ких норм можно считать оправданным в двух случаях: 1) когда сама тестовая «сырая» шкала имеет практический смысл(например, сту-
дент, изучающий иностранный язык, должен знать как можно больше слов этого языка, и сырой показатель лексического теста имеет прак-
тический смысл); 2) когда сырой балл по тесту в результате эмпириче-
ских исследований связывается с заданной вероятностью успешности какой-либо практической деятельности (вероятность успеха «критери-
альной» деятельности, каковой для упомянутого выше примера может быть синхронный перевод монолога в течение 30 минут).
Процентильная нормализация шкалы. Выше Показано, что нор-
мальность распределения достигается искусственным подбором пун-
ктов теста с заданными статистическими свойствами: Опишем еще ряд процедур, которые также широко используются для искусственной нормализации.
1. Нормализация пунктов. Ключ для данного пункта корректиру-
ется на базе нормальной модели. Если среди нормативной выборки с данным заданием справились только16 % испытуемых, то данному пункту на интервальной шкале«трудности» (при условии априорного
83
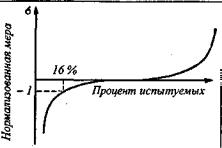
принятия нормальной модели с параметрами М = 0 и а = 1) соот-
ветствует значение +1 (см. график в книге: Анастазй А., 1982, с. 181).
Если справились 75 % испытуемых, то балл пункта на сигма-шкале равен-0,67. В результате суммирования по пунктам баллов, скоррек-
тированных нормализацией, суммарные баллы лучше приближаются к нормальному распределению.
2. Нормализация распределения суммарных баллов (или интер-
вальная нормализация). В этом случае по таблице нормального рас-
пределения (нормального интеграла) производится переход от про-
центильной шкалы к сигма-шкале: используется функция, обратная интегральной, - от ординаты производится переход к абсциссе нор-
мального распределения.
Рис. 4. Преобразование процентильной шкалы (по оси X)
в нормализованную сигма-шкалу (по оси Y)
На рис. 4 дана условная графическая иллюстрация этого пере-
хода (кривая, обратная традиционной S-образной интегральной кри-
вой нормального распределения).
Приведем пример интервальной нормализации(табл. 3). Пусть строка X содержит сырые баллы (не нормализованные) по тесту, по-
лученные простым подсчетом правильных ответов. В строке Р - час-
тоты встречаемости сырых баллов в выборке из 62 испытуемых. В
i
строке F - кумулятивные частоты: Fi = åPji . В строке F* - кумулятив-
|
|
|
|
|
|
j=1 |
ные баллы: |
F |
* = F - |
1 |
P |
. В строке PR - процентильные ранги: |
|
|
||||||
i |
i |
2 |
i |
|||
|
|
|
|
|
||
84
PRi = Fi* ×100 / n . В строке σ даются нормализованные баллы, по-
лученные из соответствующих процентильных рангов по таблицам, а -
оценки часто называются в зарубежной литературе также z-оценками.
Таблица 3
X |
3 |
4 |
5 |
6 |
7 |
8 |
|
P |
2 |
18 |
13 |
8 |
10 |
6 |
|
F |
2 |
20 |
33 |
41 |
51 |
57 |
|
F* |
1 |
11 |
26,5 |
37 |
46 |
54 |
|
PR |
1,6 |
17,7 |
42,7 |
59,7 |
74,2 |
87,1 |
|
σ |
- |
-0,9 |
-0,2 |
0,2 |
0,6 |
1,1 |
|
|
2,1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Трудность, с которой сталкиваются начинающие при использо-
вании интервальной нормализации, состоит в том, что обычные стати-
стические таблицы не приспособлены для психометрики: нужно отыс-
кивать значение процентильного ранга внутри таблицы, а соответству-
ющую сигма-оценку – с краю. Для облегчения ориентации приведем фрагмент таблицы соответствий PR, а и стенов (табл. 4):
Таблица 4
PR |
99 |
95 |
90 |
85 |
80 |
75 |
7 |
σ |
2,33 |
1,64 |
1,28 |
1,04 |
0,84 |
0,68 |
0 |
стен |
10 |
10 |
9 |
8 |
8 |
7 |
6 |
|
|
|
|
|
|
|
|
PR |
50 |
45 |
40 |
35 |
30 |
25 |
2 |
σ |
0,0 |
- |
- |
- |
- |
- |
- |
стен |
5,5 |
0,13 |
0,25 |
0,39 |
0,52 |
0,68 |
0,84 |
|
|
5 |
|
4,5 |
4 |
4 |
|
|
|
|
|
|
|
|
|
В обычных таблицах из соображений симметрии даны лишь зна-
чения для PR > 50. Для PR < 50 соответствующие значения находятся из тех же таблиц σ = ψ -1(1- PR/100). Например, для PR =35 мы нахо-
дим 1 - PR/100 = 1 - 0,35 = 0,65, затем - по табл. ψ -1 = 0,39 и берем это значение с отрицательным знаком -0,39. Для нормализации удобно пользоваться графическим методом (нормальной бумагой, стандартной
5-образной кривой и т. п.).
В результате нормализации интервалы между исходными сыры-
85
ми баллами переоцениваются в соответствии с нормальной моделью. В
отличие от процентильной шкалы, нормальная шкала придает боль-
ший вес (в дифференциации испытуемых) краям распределения: раз-
личия между испытуемыми, набравшими 95 и 90 процентилей, оце-
ниваются как более высокие, чем различия между испытуемыми, на-
бравшими 65 и 60 процентилей.
В применении к шкалам оценок(рейтинговым шкалам) метод нормализации интервалов называется «методом последовательных ин-
тервалов» (Клигер С. А. и др., 1978, с. 75-81).
В результате применения процедуры нормализации исследова-
тель-психометрист получает для нормативной выборки таблицу пере-
вода сырых баллов в нормализованные баллы. На основе этих таблиц часто строят графики: деления сырых баллов наносят на числовую ось с неравными интервалами, так что эмпирическое распределение час-
тот максимально близко приближается к нормальной форме. Пример такой графической нормализации - профильные листы MMPI (Анастази А., 1982, с. 129).
Так как нормальное распределение описывается всего двумя па-
раметрами: средним М (мерой положения) и средним квадратическим
(или стандартным) отклонением а (мерой рассеяния), то диаг-
ностические нормы в случае нормализованных шкал описываются в единицах отклонений от среднего по выборке; например, заключают,
что испытуемый А показал результат, превышающий средний балл на две сигмы, испытуемый В -результат, оказавшийся ниже среднего бал-
ла на одну сигму, и т. п. На процентильной шкале этому соответствуют процентильные ранги 95 и 16 соответственно.
Переход к нормальному распределению создает очень удобные условия для количественных операций с диагностической шкалой: как со шкалой интервалов с ней можно производить операции линейного преобразования (умножение и сложение), можно описывать диагно-
стические нормы в компактной форме (в единицах отклонений), можно применять линейный коэффициент корреляции Пирсона, критерии для проверки статистических гипотез, построенные в применении к нор-
мальному распределению, т. е. весь аппарат традиционной статистики
(основанной на нормальном распределении). !
Неправомерность онтологизации нормального закона. В тради-
86
ционной психометрике нормальное распределение выступает в роли инструментального понятия, облегчающего оперирование с данными.
Но это не означает, что можно забывать об искусственном проис-
хождении нормального распределения. Традиции западной тестоло-
гии, основанные еще Ф. Гальтоном, предполагают однородность тео-
ретических представлений психометрики и биометрики. Точно так же как происхождение нормального распределения при исследовании ва-
риативности биологических характеристик человеческого организма связывается с наличием взаимодействия постоянного фактора гено-
типа и изменчивых случайных факторов фенотипа, - происхождение межиндивидуальных психологических различий связывается с гене-
тическим кодом, якобы предопределяющим положение индивида на оси нормальной кривой. В действительности же нет никаких основа-
ний приписывать появление нормальной кривой, часто получаемой с помощью специальных статистических непростых процедур, действию механизма наследственности.
В тех случаях, когда на большой выборке удается получить нор-
мальное распределение без каких-либо искусственных способствую-
щих этому мер, это опять-таки не означает вмешательства генетики.
Закон нормального распределения воспроизводится всякий раз, когда на измеряемое свойство (на формирование определенного уровня спо-
собностей индивида) действует множество разных по силе и направ-
ленности факторов, независимых друг от друга. История прижизнен-
ных средовых воздействий, которые испытывает на себе субъект, так-
же подобна последовательности независимых событий: одни факторы действуют в благоприятном направлении, другие - в неблагоприятном,
а в результате взаимопогащение их влияний происходит чаще, чем тенденциозное однонаправленное сочетание (большинство благопри-
ятных или большинство неблагоприятных), т. е. возникает нормальное распределение. Массовые исследования показывают, что введение контроля над одним из средовых популяционных факторов(уровень образования родителей, например) приводит к расслоению кривой нормального распределения: выборочные кривые оказываются сме-
щенными относительно друг друга (Анастази А., 1982, с. 201). Эти ре-
зультаты служат ярким подтверждением социокультурного происхож-
дения статистических диагностических норм, что одновременно служит
87

основанием для серьезных предосторожностей при переносе норм, по-
лученных на одной популяции, на другие популяции. Однородными можно считать только те популяции, по отношению к которым дейст-
вует одинаковый механизм выборки: ив ситуации создания (стандар-
тизации) теста, и в ситуации его диагностического применения. Здесь приходится учитывать и такие нюансы выборочного механизма, как феномен нормальных добровольцев. Если выборку стандартизации формировать на студентах, добровольно согласившихся участвовать в тестировании, а применение теста планируется на сплошных выборках
(в административном порядке), то это грозит определенными ошибка-
ми в диагностических суждениях, так как психологический портрет
«добровольца» в существенных чертах отличается от портрета испы-
туемого, соглашающегося на тестирование только под административ-
ным давлением (Шихирев П.Н, 1979, с. 181).
Подсчет параметров и оценка типа распределения. Для описа-
ния выборочного распределения, как правило, используются следую-
щие известные параметры:
1. Среднее арифметическое значение:
n |
|
x =1nåj=1 pj yj , |
(3.1.1) |
где xj – балл i-го испытуемого;
yi -значение i-го балла по порядку возрастания; pi - частота встречающегося i-го балла;
n - количество испытуемых в выборке (объем);
m - количество градаций шкалы (количество баллов).
2. Среднее квадратическое (стандартное) отклонение:
3.
|
|
|
|
|
|
|
|
s = |
å(x - |
x |
) 2 |
|
å x 2 - (å x 2 )/ n |
(3.1.2) |
|
» |
, |
||||||
|
n |
n -1 |
|
||||
88

где å x 2 - сумма квадратов тестовых баллов для и испытуемых. 3. Асимметрия:
AS = |
1 |
(q - 3C 2 |
x |
+ 2 |
x |
3 ) |
|
S 3 |
|||||||
|
|
|
|
|
|
(3.1.3)
где x - среднее арифметическое значение; S - стандартное отклонение;
θ - среднее кубическое значение: |
|
q = 3 |
1 |
å x3 , |
||||||||||
|
n |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С - среднее квадратическое: C = |
1 |
å x 2 |
|
|||||||||||
n |
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4. Эксцесс: |
|
|
|
|
|
|||||||||
Ex= |
1 |
(Q4 -403 |
x |
+6C2 |
x |
2 -3 |
x |
4 )-3, |
|
|
|
|
(3.1.4) |
|
|
|
|
|
|
||||||||||
|
s4 |
|
|
|
|
|
||||||||
 1
1
где Q - среднее значение четвертой степени: Q = 4 n åx4 .
Стандартная ошибка среднего арифметического значения (мате-
матического ожидания) оценивается по формуле:
sm |
= |
s |
(3.1.5) |
|
|
|
|||
|
|
|
||
|
|
|
n |
|
На основе ошибки математического ожидания строятся довери-
тельные интервалы: (x - 2S m ; x + 2S m )
Если тестовый балл какого-либо испытуемого попадает в грани-
цы доверительного интервала, то нельзя считать, что испытуемый об-
ладает повышенным (или пониженным) значением измеряемого свой-
ства с заданным уровнем статистической значимости.
Асимметрия и эксцесс нормального распределения должны быть
равны нулю. Если хотя бы один из двух параметров существенно -от личается от нуля, то это означает анормальность полученного эмпи-
рического распределения.
Проверку значимости асимметрии можно произвести на основе
общего неравенства Чебышева:
As £ |
Sa |
(3.1.6) |
 1 - p
1 - p
89

где Sa - дисперсия эмпирической оценки асимметрии:
S |
= |
6(n-1) |
|
|
a |
|
(n+1)(n+3) |
, |
(3.1.7) |
где р - уровень значимости или вероятность ошибки первого ро-
да: ошибки в том, что будет принят вывод о незначимости асимметрии при наличии значимой асимметрии(в формулу подставляют стандар-
тные р = 0,05 или р = 0,01 и проверяют выполнение неравенства).
Сходным образом оценивается значимость эксцесса:
Ex £ |
Se |
(3.1.8) |
 1 - p
1 - p
где Sе - эмпирическая дисперсия оценки эксцесса:
S e |
= |
24n(n - 2)(n - 3) |
. |
(3.1.9) |
|
||||
|
|
(n +1)2 (n + 3)(n + 5) |
|
|
] |
|
|
|
|
Гипотезы об отсутствии |
асимметрии и эксцесса принимаются с |
|||
вероятностью ошибки р (пренебрежимо малой), если выполняются не-
равенства (3.1.6) и (3.1.8).
Более легкий метод проверки нормальности эмпирического рас-
пределения основывается на универсальном критерии Колмогорова.
Для каждого тестового балла у. (для каждого интервала равнозначно-
сти при дискретизации непрерывной хронометрической шкалы) вы-
числяется величина D. - модуль отклонения эмпирической и теорети-
ческой интегральных функций распределения:
D j = |
F ( y j ) -U (z j ) |
(3.1.10) |
где F- эмпирическая интегральная функция (значение кумуляты в данной точке уj); U — теоретическая интегральная функция, взятая из таблиц1. Среди Dj отыскивается максимальное значениеDmax 
 n , и
n , и
величина le = Dmax 
 n сравнивается с табличным значениемlt крите-
n сравнивается с табличным значениемlt крите-
рия Колмогорова.
1 Значение zj определяется после стандартизации шкалы в единицах стандартно-
го отклонения: S:zj = yj -x
S
90