

КОНСПЕКТ ЛЕКЦИЙ КОДЭИ
.pdfКак и в случае простой линейной регрессии, об ошибке ε высказываются следующие предположения:
1. Предположение о нулевом среднем. Ошибка е представляет собой случайную переменную со средним, равным 0.
2. Предположение о постоянстве дисперсии. Дисперсия ошибки является постоянной величиной для всех значений переменных х1,
х2,...хm.
3. Предположение о независимости. Значения переменной ε являются статистически независимыми.
4. Предположение о нормальности. Значения ошибки ε распределены по нормальному закону.
12.03.13 Доцент С.Т. Касюк |
7 |

Оценка значимости множественной регрессионной модели
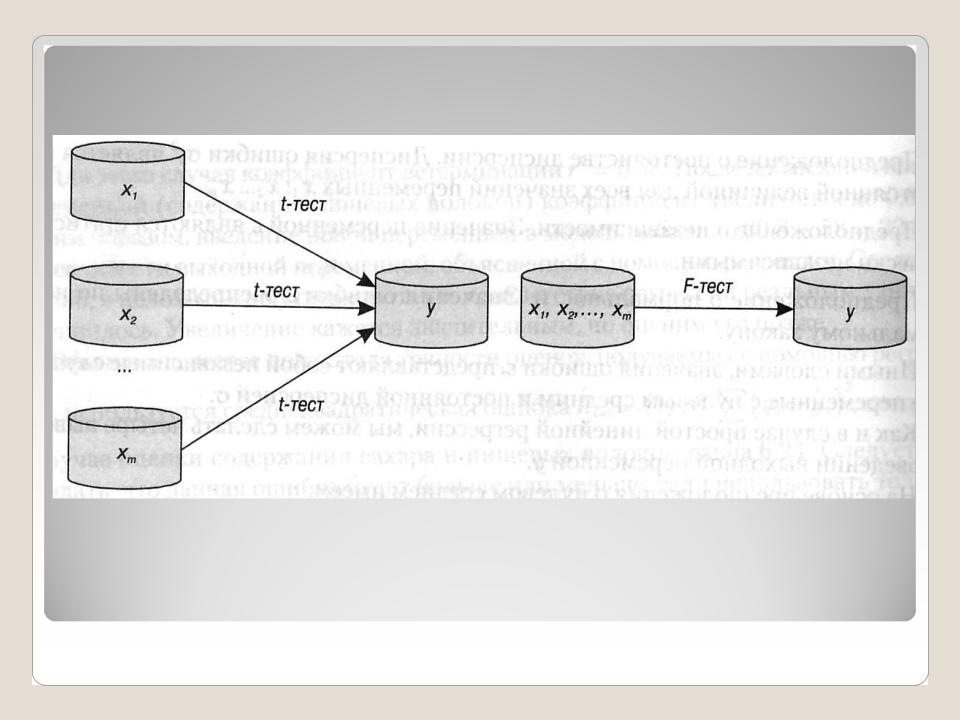
Как и в случае простой регрессионной модели, для оценки значимости множественной регрессии используются гипотезы о наличии или отсутствии линейной зависимости между набором входных переменных и выходной переменной. Для проверки этих гипотез также можно применять t-критерий и F- критерий. Но в случае множественной линейной регрессии применение данных критериев несколько иное. Если t-критерий исследует линейную зависимость между каждой отдельной входной переменной хi, и выходной переменной у, то F- критерий исследует линейную зависимость для всей модели, то есть между набором входных переменных х1, х2,.., хm и переменной у.
12.03.13 Доцент С.Т. Касюк |
8 |
12.03.13 Доцент С.Т. Касюк |
9 |

Методы отбора переменных в регрессионные модели
Большинство реальных анализируемых процессов и объектов являются сложными, для их описания требуется много признаков и показателей. Поэтому типична ситуация, когда аналитику при построении регрессионных моделей приходится иметь дело с десятками переменных и, соответственно, производить отбор переменных для построения модели. Данная задача совсем не так проста, как кажется. На первый взгляд, нужно отобрать только те переменные, которые непосредственно связаны с решаемой задачей. Однако даже после того, как посторонние переменные будут отсеяны, нет гарантии успешного решения.
12.03.13 Доцент С.Т. Касюк |
10 |

На практике приходится соблюдать два противоречивых требования:
1.В регрессионной модели нужно использовать как можно больше входных переменных, содержащих информацию о выходной переменной.
2.Поскольку включение в модель каждой новой переменной увеличивает временные и вычислительные затраты на ее реализацию, нужно стремиться, чтобы модель содержала как можно меньше входных переменных.
Выбор лучшей регрессионной модели заключается в поиске компромисса между данными требованиями.
12.03.13 Доцент С.Т. Касюк |
11 |

После того как нежелательные переменные будут исключены, среди оставшихся производится поиск тех, набор которых обеспечит лучшую регрессионную модель. Однако и на этом этапе возникает ряд проблем. Во-первых, понятие «Лучшая модель» не имеет строгих критериев и во многом субъективно. Вовторых, ни один из известных методов отбора не гарантирует получение набора перемени позволяющих достичь наилучшего результата. Зачастую такого набора просто не существует. В-третьих, различные методы отбора приводят к различным результатам. Поэтому на практике аналитики чаще всего ставят целью получить не наилучший, а приемлемый набор входных переменных, который позволит соблюсти баланс между противоречивыми требованиями.
12.03.13 Доцент С.Т. Касюк |
12 |

Наиболее популярные методы отбора входных переменных в регрессионные модели:
1)метод прямого выбора (forward selection);
2)метод обратного исключения (backward elimination);
3)метод последовательного отбора (stepwise selection);
4)метод лучших подмножеств (best subsets);
5)метод всех возможных регрессий.
12.03.13 Доцент С.Т. Касюк |
13 |

Метод прямого выбора
Прямой выбор начинается с пустой модели, в которую еще не включена ни одна переменная, и содержит следующие шаги:
1. Для первой переменной, вводимой в модель, основным критерием выбора является высокая корреляция с выходной переменной. Если полученная в результате модель не обладает достаточной значимостью, из этого следует, что среди доступных переменных исходной выборки значимые переменные отсутствуют. В противном случае переходим ко второму шагу.
12.03.13 Доцент С.Т. Касюк |
14 |

2. Для каждой из остальных переменных вычисляется последовательная F-статистика для данной переменной и переменных, уже включенных в модель. При этом каждый раз выбирается та переменная, для которой значение последовательной F-статистики будет наибольшим
(обозначим ее Fmax).
3. Для значения Fmах проводится тест значимости. Если после добавления переменной, выбранной на шаге 2, модель не обладает достаточной значимостью, то алгоритм останавливается и текущая модель остается без перемени выбранной на шаге 2. В противном случае изменение модели принимается и осуществляется переход на шаг 2 для выбора следующей переменной.
12.03.13 Доцент С.Т. Касюк |
15 |
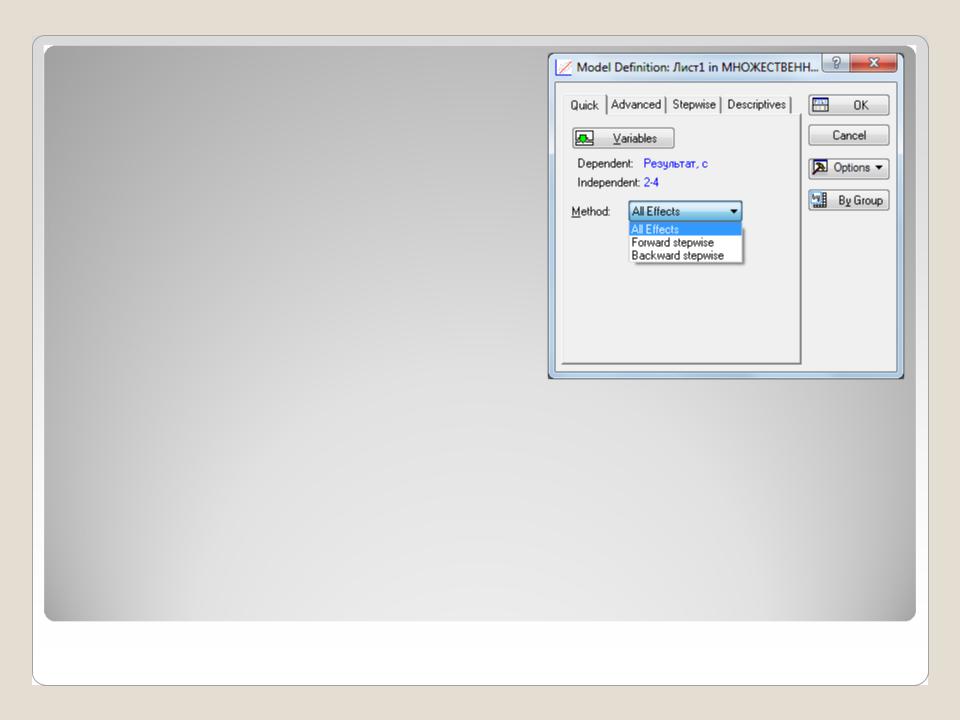
Процесс продолжается до тех пор, пока все значимые переменные не будут включены в модель.
12.03.13 Доцент С.Т. Касюк |
16 |