

Побудова таблиць ідентифікаторів методом бінарного дерева.
Нехай в нас є ідентифікатори: BA,D1,M22,E,A12,BP,F.
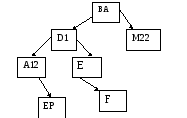
Для того, щоб скоротити час пошуку шуканого елементу в таблиці не збільшуючи значення часу на її заповнення потрібно відмовитись від організації таблиці у вигляді безперервного таблиці даних. Існує метод побудови таблиць у формі бінарного дерева. Вузол кожного дерева являє собою елемент таблиці, причому кореневим вузлом є перший елемент, що зустрівся при заповнені таблиці. Дерево називається бінарним, тому, що кожна вершина в ньому може мати не більше двох віток. Алгоритм заповнення і пошуку дивитись в методичці. Для даного методу число необхідних порівнянь і форма дерева, що вийшла залежить від того порядку, з якого надходять ідентифікатори. ABC… якщо взяти послідовність операторів, які впорядковані за алфавітом, то дерево перетвориться в одно направлений впорядкований зв’язаний список. Ця особливість є недоліком даного методу. Інший недолік є динамічний спосіб виділення пам’яті. Тз=N*Q(log2N) Tn=Q(log2N).
Не 2.3 Хеш-функції та хеш–адресація. Принципи роботи хеш-функцій.
Процес відображення області визначення хеш-функції на множину значень називається хешування. При роботі з таблицями ідентифікаторів ця функція повинна виконувати відображення імен ідентифікаторів на множину цілих не від’ємних значень. Областю визначення хеш-функції буде множина всіх можливих імен ідентифікаторів. Хеш-адресація полягає у використанні значення, що повертається хеш-функцією як адреси комірки деякого масиву даних. Розмір масиву даних повинен відповідати областю значень використовуваних хеш-функції. В реальному компіляторі область значень хеш-функції не повинна перевищувати область.
Метод організації таблиць ідентифікаторів заснований на використання хеш адресації, полягає в розміщені кожного елемента таблиці в комірку, адреса якої повертає хеш-функцію. Тоді для пошуку елемента необхідно обчислити хеш-функцію для шуканого елемента і перевірити, чи не є задана комірка порожньою. Якщо вона не порожня, то елемент знайдений, якщо порожня – не знайдений.
Перевага – цей метод є дуже ефективним, оскільки час розміщення елемента в таблиці і час його пошуку визначаються тільки часом, що затрачується на обчислення хеш-функції, що є незрівняно менше ніж багаторазове порівняння елементів в таблиці.
Недоліки: 1. неефективне використання обсягу пам’яті, тобто, що розмір пам’яті повинен відповідати області значень хеш-функції, а реально збережених ідентифікаторів може бути істотно менше. 2. необхідність вибору хорошої хеш-функції.
Ситуація, коли двом або більше ідентифікаторам відповідає одне і те саме значення функції називається колізією. Для вирішення таких ситуацій використовується ре хешування і інші методи. Адреса обчислена за допомогою хеш-функції вказує на задану колізії, то необхідно обчислити значення функції h1(A) і перевірити чи вона не займана. Якщо і вона зайнята то обчислюється значення h2(A) і так доти, поки не буде знайдена вільна комірка, або поки hі(A) не співпаде з h(A). В останньому випадку вважається, що таблиця ідентифікаторів заповнена і більше місця немає і видається помилка.
Розглянемо приклад: нехай в нас є ряд послідовних комірок n1,n2,n3,n4,n5 і необхідно розмістити такі ідентифікатори: A1,A2,A3,A4,A5
h(A1)=h(A2)=h(A5)=n1
h(A3)=n2
h(A4)=n4
Заповнення таблиці в результаті ре хешування.
h(A1)=n1
h(A2)=n1
h(A3)=n2
h(A4)=n4
h(A5)=n1
|
n1 |
|
|
n2 |
|
|
n3 |
|
|
N4 |
|
|
n5 |
|




 A1
A1 A2
A2 A3
A3 A4
A4
Найпростіше є організація у вигляді ???
Середній час пошуку: ???
Ефективність методу буде вище при рості числа ідентифікаторів і зниження заповнення таблиці.