

14.1 Strategies to achieve low delay
Strategy 1. Reduce frame length to 20 samples. From Chapter 1 we know that the
biggest component of coding delay is due to buffering at the encoder and is
directly linked to the length of the frame selected for analysis. Therefore, an
obvious solution is to reduce the length of the frame. Like conventional CELP,
the LD-CELP coder partitions the input speech samples into frames that are
further divided into subframes; each frame consists of 20 samples, containing
four subframes of five samples each. As we will see later, encoding starts
when five samples are buffered (one subframe); this leads to a buffering delay
of 0.625 ms, producing a coding delay in the range of 1.25 to 1.875 ms. These
value are much lower than conventional CELP, having a buffering delay of
20 to 30 ms.
Strategy 2. Recursive autocorrelation estimation. The first step for finding the
LPCs is to calculate the autocorrelation values, which can be done using conventional techniques such as Hamming windowing (nonrecursive); due to the short
frame length, the scheme gets highly computationally expensive and inefficient
since the windows become overlapping for consecutive frames. To simplify,
STRATEGIES TO ACHIEVE LOW DELAY 373
recursive methods can be employed. The LD-CELP coder utilizes the Chen windowing method (Chapter 3) to estimate the autocorrelation values, which in principle is a hybrid technique, combining both recursive and nonrecursive
approaches.
Strategy 3. External prediction. Since the signal frame is relatively short, its statistical properties tend to be close to the near past or near future. It is therefore possible to estimate the LPCs entirely from the past and apply these coefficients to
the current frame, which is the definition of external prediction (Chapter 4). By
using external prediction, the encoder does not have to wait to buffer the whole
frame (20 samples) before analysis; instead, the LPCs are available at the instant
that the frame begins; encoding starts as soon as one subframe (five samples) is
available. This is in high contrast to conventional CELP, where the LPCs are
derived from a long frame, with the resultant coefficients used inside the frame
(internal prediction).
Strategy 4. Backward adaptive linear prediction. Conventional speech coders use
forward adaptation in linear prediction, where the LPCs are derived from the
input speech samples; the coefficients are then quantized and transmitted as
part of the bit-stream. The LD-CELP coder utilizes backward adaptation, with
the LPCs obtained from the synthetic speech. By doing so, there is no need
to quantize and transmit the LPCs since the synthetic speech is available
at both the encoder and decoder side, thus saving a large number of bits for transmission. Note that this is a necessity to achieve low bit-rate, since otherwise
the quantized LPCs must be transmitted at short frame intervals, leading to
unacceptably high bit-rate. A disadvantage of the approach is its vulnerability
toward channel errors: any error will propagate toward future frames while
decoding.
Strategy 5. High prediction order. The LD-CELP coder utilizes a short-term synthesis filter with a prediction order equal to 50; no long-term predictor is employed.
This design choice is due to the following reasons.
 The
operation
The
operation
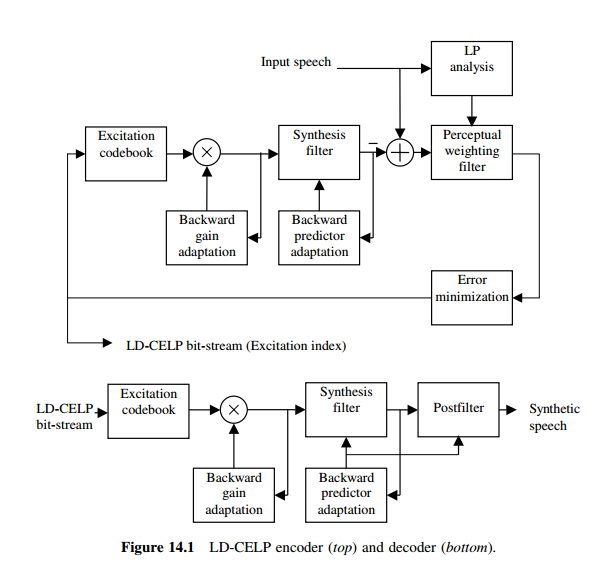
of the LD-CELP algorithm can be summarized as follows.
Like conventional CELP, samples of speech are partitioned into frames and
subdivided into subframes. In LD-CELP, each frame consists of 20 samples,
which contains four subframes of five samples each. Since LP analysis is
performed in a backward adaptive fashion, there is no need to buffer an entire
frame before processing. Only one subframe (five samples) needs to be stored
before the encoding process begins.
The perceptual weighting filter has ten linear prediction coefficients derived
from the original speech data. The filter is updated once per frame. The
current frame’s coefficients are obtained from previous frames’ samples.
The synthesis filter corresponds to that of a 50th-order AR process. Its
coefficients are obtained from synthetic speech data of previous frames.
The filter is updated once per frame. The zero-input response of the current
frame can be obtained from the known initial conditions.
Excitation gain is updated every subframe, with the updating process
performed with a tenth-order adaptive linear predictor in the logarithmic-gain
domain. The coefficients of this predictor are updated once per frame, with the
LP analysis process done on gain values from previous subframes.
The excitation sequence is searched once per subframe, where the search
procedure involves the generation of an ensemble of filtered sequences: each
excitation sequence is used as input to the formant synthesis filter to obtain an
output sequence. The excitation sequence that minimizes the final error is
selected.
In the decoder, the initial conditions are restored. The synthetic speech is
generated by filtering the indicated excitation sequence through the filter
without any perceptual weighting. Since the excitation gain and the LPCs are
backward adaptive, there is no need to transmit these parameters. A postfilter
can be added to further enhance the output speech quality