

Econometrics1_enie_aaee_iia_
.pdfсредние и среднеквадратические отклонения для новых переменных. Все средние должны быть 0, а среднеквадратические отклонения 1.
tx1 |
|
tx2 |
|
|
tx3 |
|
|
tx4 |
|
|
tx5 |
|
|
tx6 |
|
|
ty |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0.239427579 |
|
-0.0946 |
|
|
0.184116 |
|
|
-0.36891 |
|
|
0.306631 |
|
|
-0.34302 |
|
|
-0.33819 |
|
-0.315334484 |
|
0.173912 |
|
|
0.287634 |
|
|
-0.0357 |
|
|
-0.66901 |
|
|
-1.46696 |
|
|
0.017377 |
|
-0.490698547 |
|
-0.65703 |
|
|
-0.437 |
|
|
-0.2023 |
|
|
0.306631 |
|
|
0.474389 |
|
|
-0.66256 |
|
-0.815623786 |
|
-0.62256 |
|
|
-0.28172 |
|
|
0.464109 |
|
|
0.696889 |
|
|
-0.8539 |
|
|
-0.46918 |
|
-0.861495585 |
|
-0.71872 |
|
|
-0.12644 |
|
|
-2.36814 |
|
|
-0.66901 |
|
|
0.576566 |
|
|
-1.25517 |
|
-1.172085887 |
|
-1.17955 |
|
|
-1.05811 |
|
|
-0.53551 |
|
|
1.477405 |
|
|
0.883094 |
|
|
-1.09298 |
|
-1.238504429 |
|
-1.19043 |
|
|
-1.52394 |
|
|
-0.70211 |
|
|
1.477405 |
|
|
0.474389 |
|
|
-1.11169 |
|
1.442606628 |
|
1.208056 |
|
|
1.638554 |
|
|
0.464109 |
|
|
0.306631 |
|
|
-0.64955 |
|
|
1.109019 |
|
0.776032056 |
|
0.703684 |
|
|
0.349746 |
|
|
0.963918 |
|
|
-0.47388 |
|
|
0.576566 |
|
|
0.915643 |
|
1.339395081 |
|
1.340499 |
|
|
1.038146 |
|
|
0.297506 |
|
|
-0.86414 |
|
|
0.98527 |
|
|
1.171399 |
|
1.341306406 |
|
1.819471 |
|
|
0.950155 |
|
|
0.297506 |
|
|
0.306631 |
|
|
-1.05825 |
|
|
1.514487 |
|
0.13143772 |
|
-0.08553 |
|
|
0.106476 |
|
|
1.463727 |
|
|
-0.66901 |
|
|
0.883094 |
|
|
0.40413 |
|
-1.168741069 |
|
-1.21583 |
|
|
-1.92767 |
|
|
-1.03532 |
|
|
-2.23005 |
|
|
1.291799 |
|
|
-1.17407 |
|
0.792278317 |
|
0.518627 |
|
|
0.800052 |
|
|
1.297124 |
|
|
0.696889 |
|
|
-1.77349 |
|
|
0.971784 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 2.6. Пример стандартизированнных переменных
Для проверки корректности стандартизации необходимо рассчитать все средние и среднеквадратические отклонения для новых переменных. Все средние должны быть 0, а среднеквадратические отклонения 1.
Для нахождения некоррелированных новых независимых переменных необходимо воспользоваться методом, описанным в лабораторной работе № 3 на основе общей матрицы корреляции.
Построить уравнение регрессии для переменных в стандартизированном масштабе по алгоритму, описанном в предыдущей лабораторной работе.
2.Сделать заключение о наиболее информативных независимых переменных
по значениям коэффициентов регрессии и направлении их влияния на ty. (Чем больше по модулю коэффициент регрессии для независимой переменной, тем большее влияние оказывает эта переменная на зависимую ty).
3.Расчет частного коэффициента корреляции междустандартизированными y и xi необходимо произвести по формуле:
|
|
|
|
|
|
|
|
ryx x x |
|
|
|
|
|
|
1 |
1 Ryx2 x |
x |
x |
p |
|
|
, |
|||
|
|
|
|
|
|
|
|
. .x |
|
x |
|
..x |
|
|
|
1 2 |
|
i |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
1 1 2 |
|
i 1 |
|
i 1 |
|
p |
1 Ryx2 |
x |
2 |
x |
x |
i 1 |
|
x |
p |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
i 1 |
|
|
|
|||||
где |
Ryx2 |
x |
2 |
x |
i |
x |
p |
- общий коэффициент детерминации, |
|||||||||||||||||
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
Ryx2 1x2 |
xi 1xi 1 |
|
xp - коэффициент детерминации, полученный при |
|||||||||||||||||||||
исключении стандартизированной переменной xi |
из регрессионного уравнения |
||||||||||||||||||||||||
41
Врассматриваемом примере количество переменных p будет равно 3.
4.Значимость частных коэффициентов корреляции проверяется на основе t- критерия Стьюдента (см. лабораторную работу № 1).
5.Сделать заключение о наиболее информативных независимых переменных по значениям коэффициентов частной корреляции. (Чем больше коэффициент частной корреляции для независимой переменной, тем большее влияние оказывает эта переменная на зависимую ty).
6.При малом объеме выборки для оценки гетероскедастичности может использоваться метод Гольдфельда – Квандта (см. п. 2.1. теоретические основы)
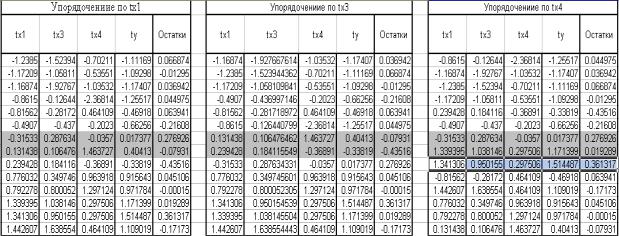
Внашем примере формируется 3 таблицы для каждой из трех независимой переменной, включенной в уравнение (Рис. 2.7). Далее необходимо упорядочить по возрастанию все элементы таблиц отдельно по каждой независимой переменной, включенной в уравнение (Рис. 2.7).
Если n=14 и p=3, то С=2, то есть из рассмотрения исключаются 4 центральных строки каждой таблицы (Рис.2.7).
Рис. 2.7. Упорядочение таблиц по каждой из трех стандартизированной переменной, включенной в регрессионное уравнение
Рассмотрим таблицу, в которой данные упорядочиваются по tx1(левая таблица на рисунке 2.7).
Построим регрессионное уравнение для первых пяти значений всех переменных (Сервис Анализ данных Корреляция).
Из таблицы на рисунке 2.8 находим остаточную дисперсию для остатков (графа «SS») S1 = 0,017. Аналогично определим остаточную дисперсию для уравнения регрессии для нижней части этой таблицы (Рис. 2.7) S2 = 0.059.
42

|
|
|
|
|
|
Значимость |
|
df |
|
SS |
MS |
F |
F |
Регрессия |
|
3 |
0.485149 |
0.161716 |
18.1081037 |
0.052787308 |
Остаток |
|
2 |
0.017861 |
0.008931 |
|
|
Итого |
|
5 |
0.50301 |
|
|
|
Рис. 2.8. Дисперсионный анализ для регрессии, проведенной для первых 6 строк анализируемой таблицы
df |
|
SS |
MS |
F |
Значимость F |
Регрессия |
3 |
1.973014 |
0.657671 |
21.95549 |
0.043877158 |
Остаток |
2 |
0.05991 |
0.029955 |
|
|
Итого |
5 |
2.032923 |
|
|
|
Рис. 2.9. Дисперсионный анализ для регрессии, проведенной для последних 6 строк анализируемой таблицы
Рассмотрим отношение:
S2 0,059
Fрасч S1 0,017 3,47
Определим критическое значение для теста Гольдфельда–Квандта как значение F-критерия со степенями свободы k1 = (n – С – 2р):2, k2 = (n – С – 2р):2. В нашем случае С = 2 и p = 3, следовательно:
k1 = k2 = (14 – 2 – 6):2 =3.
Fкрит находится при помощи функции FРАСПОБР (Число степеней свободы k1 = k2 =3 и вероятность = 0.05) и равно 9.277.
Очевидно, Fкрит>Fрасч (9,277>3,47), следовательно, остатки по переменной tx1 гомоскедастичны c вероятностью в 0,95.
Аналогичная процедура проделывается для оставшихся стандартизированных переменных, включенных в уравнение
7.Подготовить отчет в MS Word с описанием основных шагов выполнения данной лабораторной работы и интерпретацией полученных результатов.
8.Подготовленный отчет сдается через электронную систему обучения ГОУ ВПО КГТЭИ
43
Глава 3. Анализ временных рядов
3.1 Теоретические основы
При построении эконометрической модели используются два типа данных:
1)данные, характеризующие совокупность различных объектов в определенный момент времени;
2)данные, характеризующие один объект за ряд последовательных моментов времени.
Модели, построенные по данным первого типа, называются пространственными моделями. Модели, построенные на основе второго типа данных, называются моделями временных рядов.
Модели, построенные по данным, характеризующим один объект за ряд последовательных моментов (периодов), называются моделями временных рядов.
Временной ряд - это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов.
Каждый уровень временного ряда формируется из трендовой (Т),
циклической (S) и случайной (Е) компонент.
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью временного ряда. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью временного ряда.
Таким образом:
Аддитивная модель имеет вид: Y = Т + S + Е;
мультипликативная модель - Y = T S Е.
Построение аддитивной и мультипликативной моделей сводится к расчету значений Т, S и Е для каждого уровня ряда.
Основная задача эконометрического исследования отдельного временного ряда – выявление и придание количественного выражения каждой из перечисленных выше компонент с тем, чтобы использовать полученную информацию для прогнозирования будущих значений ряда или при построении моделей взаимосвязи двух или более временных рядов.
В общем случае, построение модели включает следующие шаги:
1) выравнивание исходного ряда методом скользящей средней;
44

2)расчет значений сезонной компоненты S;
3)устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных в аддитивной (T + Е) или в мультипликативной (Т ∙ Е) модели;
4)аналитическое выравнивание уровней (Т + Е) или (T ∙ Е) и расчет значений Г с использованием полученного уравнения тренда;
5)расчет полученных по модели значений (Т + S) или (T ∙ S);
6)расчет абсолютных и/или относительных ошибок.
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда.
Количественно ее можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми на несколько шагов во времени.
Автокорреляция уровней ряда - это корреляционная зависимость между последовательными уровнями временного ряда:
|
|
|
|
n |
где |
y |
|
|
yt |
|
t 2 |
|||
|
n 1 |
|||
1 |
|
|||
|
|
n |
|
|
|
|
|
|
|
|
r |
|
(yt |
y |
1) (yt 1 |
y |
2) |
|
, |
||
|
t 2 |
|
||||||||
|
|
|
|
|
|
|
|
|||
1 |
|
n |
|
n |
||||||
|
|
(yt |
y1)2 (yt 1 |
y |
2)2 |
|
||||
|
|
t 2 |
|
t 2 |
||||||
n
yt 1
; |
y |
2 |
|
t 2 |
- коэффициент автокорреляции уровней ряда первого |
|
n 1 |
||||||
|
|
|
|
порядка;
|
|
n |
|
|
|
|
|
|
|
||
r |
|
(yt |
y |
3) (yt 1 |
y |
4) |
|
, |
|||
|
t 3 |
|
|||||||||
|
|
|
|
|
|
|
|
||||
2 |
|
n |
|
n |
|||||||
|
|
(yt |
y |
3)2 (yt 2 |
y |
4)2 |
|
||||
|
|
t 3 |
|
t 3 |
|||||||
45

|
|
|
|
n |
|
|
|
|
n |
|
|
где |
y |
|
|
yt |
; |
y |
|
|
yt 1 |
- коэффициент автокорреляции уровней ряда второго |
|
3 |
t 3 |
4 |
t 3 |
||||||||
n 1 |
n 1 |
||||||||||
|
|
|
|
|
|
|
порядка.
Формулы для расчета коэффициентов автокорреляции старших порядков легко получить из формулы линейного коэффициента корреляции.
Последовательность коэффициентов автокорреляции уровней первого,
второго и т.д. порядков называют автокорреляционнои функцией временного ряда, а график зависимости ее значений от величины лага (порядка коэффициента автокорреляции) - коррелограммой.
Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка , то ряд содержит циклические колебания с периодичностью в моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать одно из двух предположений относительно структуры этого ряда: либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
Свойства коэффициента автокорреляции.
1.Он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной (или близкой к линейной) тенденции.
2.По знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда. Большинство временных рядов экономических данных содержат положительную автокорреляцию уровней, однако при этом могут иметь убывающую тенденцию.
Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом.
Построение аналитической функции для моделирования тенденции
(тренда) временного ряда называют аналитическим выравниванием временного ряда. Для этого чаще всего применяются следующие функции:
• линейная yt = a + b ∙ t;
• гипербола yt = a + b / t;
•экспонента yt = еa+bt;
•степенная функция yt = a ∙ tb ;
46

•парабола второго и более высоких порядков yt = a + bl ∙ t + b2 ∙ t2+... + bk ∙ tk.
Параметры трендов определяются обычным МНК, в качестве независимой переменной выступает время t = 1,2, ..., n, а в качестве зависимой переменной - фактические уровни временного ряда уt. Критерием отбора наилучшей формы тренда является наибольшее значение скорректированного коэффициента детерминации R2 .
Простейший подход к моделированию сезонных колебаний – это расчет значений сезонной компоненты методом скользящей средней и построение аддитивной или мультипликативной модели временного ряда.
Общий вид аддитивной модели следующий:
Y T S E.
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как сумма трендовой (T ), сезонной (S ) и случайной (E) компонент.
Общий вид мультипликативной модели выглядит так:
Y T S E.
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой (T ), сезонной (S ) и случайной ( E) компонент.
Выбор одной из двух моделей осуществляется на основе анализа структуры сезонных колебаний. Если амплитуда колебаний приблизительно постоянна, строят аддитивную модель временного ряда, в которой значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение аддитивной и мультипликативной моделей сводится к расчету значений T , S и E для каждого уровня ряда.
Процесс построения модели включает в себя следующие шаги.
1)Выравнивание исходного ряда методом скользящей средней.
2)Расчет значений сезонной компоненты S .
3)Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных (T E) в аддитивной или (T E ) в мультипликативной модели.
47

4)Аналитическое выравнивание уровней (T E) или (T E ) и расчет значений T с использованием полученного уравнения тренда.
5)Расчет полученных по модели значений (T E) или (T E ).
6)Расчет абсолютных и/или относительных ошибок. Если полученные значения ошибок не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок E для анализа взаимосвязи исходного ряда и других временных рядов.
В моделях с сезонной компонентой обычно предполагается, что сезонные воздействия за период взаимо-погашаются. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты по всем кварталам должна быть равна нулю. В мультипликативной модели это выражается в том, что сумма значений сезонной компоненты по всем кварталам должна быть равна числу периодов в цикле.
Скорректированные значения сезонной компоненты в аддитивной модели
|
|
|
|
|
n |
|
равны Si |
|
|
k, где |
k |
Si |
|
Si |
i 1 |
, в мультипликативной модели Si получаются |
||||
|
||||||
|
|
|
|
|
n |
|
при умножении ее средней оценки Si на корректирующий коэффициент k , где
n k n .
Si
i 1
Прогнозное значение Ft уровня временного ряда в аддитивной модели
есть сумма трендовой и сезонной компонент, в мультипликативной модели есть произведение трендовой и сезонной компонент.
При построении моделей регрессии по временным рядам для устранения тенденции используются следующие методы.
Метод отклонений от тренда предполагает вычисление трендовых значений для каждого временного ряда модели, например yt и xt , и расчет
отклонений от трендов: y |
t |
— |
y |
и x - |
x |
. Для дальнейшего анализа используют |
|
|
t |
t |
t |
|
не исходные данные, а отклонения от тренда.
Метод последовательных разностей заключается в следующем: если ряд содержит линейный тренд, тогда исходные данные заменяются первыми разностями:
t = yt – yt-1 = b + (ε1 – εt-1);
48

если параболический тренд - вторыми разностями:
2t t t 1 2 b2 ( t 2 t 1 t 2).
В случае экспоненциального и степенного тренда метод последовательных разностей применяется к логарифмам исходных данных.
Модель, включающая фактор времени, имеет вид
yt = a + b1 ∙ xt + b2 ∙ t + εt.
Параметры а и b этой модели определяются обычным МНК.
Автокорреляция в остатках - корреляционная зависимость между значениями остатков е, за текущий и предыдущие моменты времени.
Эта автокорреляция может быть вызвана несколькими причинами, имеющими различную природу.
1.Она может быть связана с исходными данными и вызвана наличием ошибок измерения в значениях результативного признака.
2.В ряде случаев автокорреляция может быть следствием неправильной спецификации модели. Модель может не включать фактор, который оказывает существенное воздействие на результат и влияние которого отражается в остатках, вследствие чего последние могут оказаться автокоррелированными. Очень часто этим фактором является фактор времени t.
Для определения автокорреляции остатков используют критерий Дарбина - Уотсона и расчет величины:
n
( t t 1)2
d t 2 , 0 d 4.
n
t2
t 2
49
Коэффициент автокорреляции остатков первого порядка определяется по формуле
n
t t 1
r |
|
t 2 |
, 1 r 1. |
|
n |
||||
1 |
|
1 |
||
|
|
t2 |
|
|
|
|
t 2 |
|
Критерий Дарбина - Уотсона и коэффициент автокорреляции остатков первого порядка связаны соотношением
|
|
|
|
d ≈ 2(1 - |
r |
|
|
|
|
|
|
|
|
1 ). |
|
|
|
Таким образом, если в остатках существует полная положительная |
||||||||
автокорреляция |
и |
r1 1, |
то |
d 0. Если в |
остатках |
полная |
отрицательная |
|
автокорреляция, |
то |
r1 1 |
и, следовательно, d 4. |
Если |
автокорреляция |
|||
остатков отсутствует, то r1 0 |
и d 2. Т.е. 0 d 4. |
|
|
|||||
Алгоритм выявления автокорреляции остатков на основе критерия |
||||||||
Дарбина-Уотсона следующий. Выдвигается гипотеза |
H0 |
об отсутствии |
||||||
автокорреляции |
остатков. |
Альтернативные |
|
гипотезы |
H1 и |
H1* состоят, |
||
соответственно, в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются критические значения критерия Дарбина-Уотсона dL и dU для заданного числа наблюдений n, числа независимых переменных модели m и уровня значимости . По этим значениям числовой промежуток 0; 4 разбивают на пять отрезков. Принятие
или отклонение каждой из гипотез с вероятностью 1 |
осуществляется |
||||
следующим образом: |
|
|
|
|
|
0 d dL |
– |
есть |
положительная автокорреляция |
остатков, H0 |
|
отклоняется, с вероятностью P 1 принимается H1; |
|
||||
dL d dU |
– зона неопределенности; |
|
|||
dU d 4 dU |
– |
нет |
оснований отклонять H0 , т.е. |
автокорреляция |
|
остатков отсутствует; |
|
|
|
|
|
4 dU d 4 dL |
– зона неопределенности; |
|
|||
50