

3.4.4. Критические значенияZ-статистики при множественных сравнениях
Для выяснения значимости вычисляется критическое значение максимальной по модулю Z-статистики таблицы (max|Zij|), и значимыми считаемZij, превышающие это значение. Как обычно, критическое значение выбирается так, чтобы вероятность случайно его превзойти была равна заданному значению (обычно 5 %).
3.4.5. Статистические эксперименты
Для выяснения критического значения max |Zij|многократно (заданное число раз) имитируется ситуация независимости ответов, соответствующих строкам и столбцам. В ходе имитации в клетках таблицы получаются значенияZ-статистик. Такая имитация осуществляется за счет случайного перемешивания данных, которое можно представить так, будто мы рассыпали листочки с разными вопросами анкеты и собираем их вместе в случайном порядке.
По эмпирической функции распределения получаются критические значения для максимума Z-статистики.
Эксперименты позволяют также оценить в каждой клетке наблюдаемую множественную значимость Z-статистики – вероятность на всей таблице случайно получить большее значение Z-статистики.
3.4.6. Работа с программой Typology Tables
Коротко статистический анализ таблиц при помощи Typology Tables можно представить последовательностью следующих естественных действий.
Задание групповых переменных
Выбор переменных для строк, столбцов, если необходимо – переменных для вычисления средних и условий (слоев).
Выбор таблицы сопряженности или средних (на основе числа валидных («немиссинговых») объектов внутри таблицы.
Статистический эксперимент.
Выдача результатов. Программа может выводить результат в текстовый файл, формат, применяемый в Интернет (HTML) и в виде файла EXCEL.
Каждое из этих действий в программе обеспечено своей экранной формой; переход от одной формы к другой происходит естественным путем (запуском очередных расчетов) или с помощью специальных кнопок-переключателей.
3.4.7. Примеры использования программы Typology Tables
В информации RLMS содержатся сведения о покупках 3 700 семей, сделанных в течение 1 недели (молочных продуктов, спиртного и табачных изделий, сладостей и др.), о размерах жилья и имеющихся в жилье удобствах, о наличии в семье дорогостоящих предметов и недвижимости.
3.4.7.1. Частотная таблица. Наличие крупной собственности и покупки спиртного и табака.
Связаны ли ответы о покупках спиртного и табака с наличием автомобиля, дачи и других предметов длительного пользования? Этот вопрос мы проанализируем с помощью Typology Tables. Табл. 3.10, полученная по совокупности городских семей (подвыборка из RLMS 2604 семей), показывает такую связь. Строки таблицы соответствуют ответам по вопросу о благосостоянии, столбцы – ответам по вопросу о пристрастиях к напиткам и курению. Отличие таблицы для неальтернативных признаков от обычной таблицы частот заключается в том, что группы объектов (семей), соответствующие разным ответам, могут пересекаться.
Явно видно, что в семьях, владеющих крупной собственностью, употребляют больше алкоголя и табака (может быть, сказывается наличие в них большего числа мужчин?). Однако насколько надежен этот вывод? Особенно для группы владельцев грузового автомобиля – уж слишком мала эта группа для надежных выводов.
Таблица 3.10
Покупка алкоголя и табачных изделий и наличие крупной собственности (фрагмент таблицы сопряженности, частоты и % по строкам)

Z-статистики в табл. 3.11 показывают значимость связей некоторых ответов. Однако множественные сравнения не позволяют полностью доверять этим результатам.
Таблица 3.11
Z-статистики и значимость (%) связи покупки алкоголя и табачных изделий и наличие крупной собственности (фрагмент таблицы, Z-статистики)
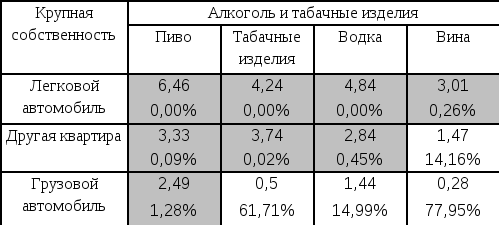
В табл. 3.12 отмечены значимые с точки зрения множественных сравнений Z-статистики. При этом оценка 5 %-го критического значенияZравна 3,09, а не 1,96, как это было бы в обычном анализе.
В каждой клетке расположены также наблюдаемые множественные значимости. Например, Z-статистика6,46 в клетке «Легковой автомобиль – пиво» практически не может быть получена случайно (вероятность получить большее значение равна нулю). Связь, характеризуемая значениемZ = 2,84 в клетке «Наличие второй квартиры – водка» – под сомнением: такие и большие значения в одной из 28 клеток таблицы можно получить случайно с вероятностью10,8 %. С точки зрения обычного анализа эта связь существенна, с точки зрения множественных сравнений не существенна.
Таблица 3.12
Z-статистики отклонений частот и их наблюдаемая множественная значимость (в %, 5 %-е критическое значение max |Z ij| = 3,09)
