

Полностью ассоциативное распределение
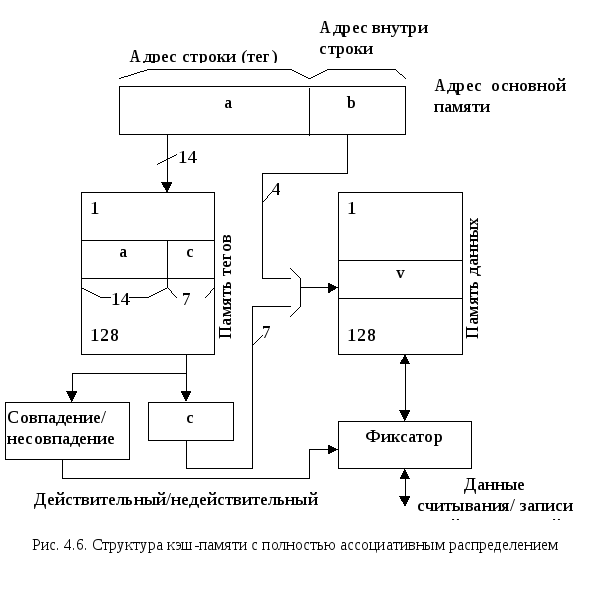
При полностью ассоциативном распределении допускается размещение каждой строки основной памяти на месте любой строки кэш-памяти. Структура кэш-памяти с полностью ассоциативным распределением представлена на рис. 4.6.
Адрес основной памяти состоит из 14-разрядного адреса строки (тега) и 4-разрядного адреса внутри строки.
При полностью ассоциативном распределении механизм преобразования адресов должен быстро дать ответ, существует ли копия строки с произвольно указанным адресом в кэш-памяти, и если существует, то по какому адресу. Для этого необходимо, чтобы теговая память являлась ассоциативной памятью. Входной информацией для ассоциативной памяти тегов является тег – 14-разрядный адрес строки, а выходной информацией – адрес строки внутри кэш-памяти. Каждое слово теговой памяти состоит из 14-разрядного тега и 7- разрядного адреса строки внутри кэш-памяти. Ключом для поиска адреса строки внутри кэш-памяти является тег (старшие 14 разрядов адреса основной памяти).
При совпадении ключа с одним из тегов теговой памяти (кэш-попадание) происходит выборка соответствующего данному тегу адреса и обращение к памяти данных. Входной информацией для памяти данных является 11-разрядное слово (7 бит адреса строки и 4 бит адреса слова в данной строке).
При несовпадении ключа ни с одним из тегов теговой памяти (кэш-промах) осуществляется обращение к основной памяти и чтение необходимой строки.
По этому способу при замене строк кандидатом на удаление могут быть все строки в кэш-памяти.
Частично ассоциативное распределение
При данном способе несколько соседних строк (фиксированное число, не менее двух) из 128 строк кэш-памяти образуют структуру, называемую группой.
Структура кэш-памяти, основанная на использовании частично ассоциативного распределения, показана на рис. 4.7. В данном случае в одну группу входят 4 строки.

Адрес строки основной памяти (14 бит) разделяется на две части: b – тег (старшие 9 бит) и е –адрес группы (младшие 5 бит). Адрес строки внутри кэш-памяти, состоящий из 7 бит, разделяется на адрес группы (5 бит) и адрес строки внутри группы (2 бит).
Массивы тегов и данных состоят из четырех банков данных, доступ к каждому из которых осуществляется параллельно одинаковыми адресами. Каждый банк массива тегов имеет длину слова 9 бит для помещения значения тега, а число слов равно числу групп, т.е. 32. Каждый банк массива данных имеет длину слова такую же, как и у основной памяти, а ёмкость его определяется числом слов в одной строке, умноженных на число групп в кэш-памяти.
Для помещения в кэш-память строки, хранимой в ОП по адресу b, необходимо выбрать группу с адресом е. При этом не имеет значения, какая из четырех строк в группе может быть выбрана. Для выбора группы используется метод прямого распределения, а для выбора строки в группе используется метод полностью ассоциативного распределения.
Когда центральный процессор запрашивает доступ по i-му адресу, то осуществляется обращение к массиву тегов по адресу е, выбирается группа из четырёх тегов (a, b, c, d), каждый из которых сравнивается со старшими 9 битами (b) адреса строки. На выходе четырех схем сравнения формируется унитарный код совпадения (0100), который на шифраторе преобразуется в двухразрядный позиционный код, служащий адресом для выбора банка данных (01).
Одновременно осуществляется обращение к массиву данных по адресу e.f (9 бит) и считывание из банка V2требуемой строки или слова.
При пересылке новой строки в кэш-память удаляемая из нее строка выбирается из четырех строк соответствующего набора (группы).