

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfКонтрольные вопросы |
5 8 5 |
Контрольные вопросы
1. Какой уровень параллелизма в обработке информации обеспечивают вычислительные системы класса SIMD?
2.На какие структуры данных ориентированы средства векторной обработки?
3.Благодаря чему многомерные массивы при обработке можно рассматривать в качестве одномерных векторов?
4.Поясните различие между конвейерными и векторно-конвейерными вычислительными системами.
5.Поясните назначение регистров векторного процессора: регистра длины вектора, регистра максимальной длины вектора, регистра вектора индексов и регистра маски.
6.Для чего используются операции упаковки/распаковки вектора?
7.Оцените выигрыш в быстродействии векторного процессора за счет сцепления векторов.
8.В чем заключается принципиальное различие между векторными и матричными вычислительными системами?
9.Какими средствами обеспечивается подготовка программ для матричных вычислительных систем и их загрузка?
10.По какому принципу в матричной ВС команды программы распределяются между центральным процессором и массивом процессоров?
И.Каким образом в матричной ВС реализуются предложения типа IF-THEN- ELSE?
12.Как идентифицируются отдельные процессорные элементы в массиве процессоров матричной ВС?
13.Какие схемы глобального маскирования применяются в матричных ВС и в каких случаях каждая из них является предпочтительной?
14.Могут ли участвовать в вычислениях замаскированные (пассивные) процессорные элементы матричной ВС и в каким виде это участие проявляется?
15.Поясните различие между ассоциативной памятью и ассоциативным процессором.
16.В чем выражается аналогия между матричными и ассоциативными ВС?
17.Какую особенность систолической ВС отражает ее название?
18.Объясните достоинства и недостатки систолических массивов типа ULA, BLA, TLA.
19.Сформулируйте правилаобъединения простых команд в командное слово сверхбольшой длины.
20.Чем ограничивается количество объединяемых команд в технологии EPIC?
21.Поясните назначение системы предикации и ее реализацию в архитектуре
•IA-64.

Глава14
Вычислительные системы класса MIMD
Технология SIMD исторически стала осваиваться раньше, что и предопределило широкое распространение SIMD-систем. В настоящее время тем не менее наметился устойчивый интерес к архитектурам класса MIMD. MIMD-системы обладают большей гибкостью, в частности могут работать и как высокопроизводительные однопользовательские системы, и как многопрограммные ВС, выполняющие множество задач параллельно. Кроме того, архитектура MIMD позволяет наиболее эффективно распорядиться всеми преимуществами современной микропроцессорной технологии,
ВMIMD-системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других ПЭ. В то же время ПЭ должны как-то взаимодействовать друг с другом. Различие в способе такого взаимодействия определяет условное деление MIMD-систем на ВС с общей памятью и системы
сраспределенной памятью. В системах с общей памятью, которые характеризуют как сильно связанные (tightly coupled), имеется общая память данных и команд, доступная всем процессорным элементам с помощью общей шины или сети соединений. К этому типу, в частности, относятся симметричные мультипроцессоры
(SMP,SymmetricMultiprocessor)исистемыснеоднороднымдоступомкпамяти
(NUMA, Non-Uniform Memory Access).
Всистемах с распределенной памятью или слабо связанных (loosely coupled) многопроцессорных системах вся память распределена между процессорными элементами, и каждый ёлок памяти доступен только «своему» процессору. Сеть соединений связывает процессорные элементы друг сдругом. Представителями этой группымогутслужитьсистемысмассовымпараллелизмом(МРР,MassivelyParallel Processing)икластерныевычислительныесистемы.
Базовой моделью вычислений на MIMD-системе является совокупность независимых процессов, эпизодически обращающихся к совместно используемымданным. Существует множество вариантов этой модели. На одном конце спектра - распределенные вычисления, в рамках которых программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм.

Симметричные мультипроцессорныесистемы 5 8 7
Числопроцессоров
Рис. 14 . 1 . ПроизводительностьMIMD-систем как функция ихтипа и числа процессоров
На другом конце — модель потоковых вычислений, где каждая операция в программе может рассматриваться как отдельный процесс. Такая операция ожидает поступления входныхданных (операндов), которые должны быть переданы ейдругими процессами. По их получении операция выполняется, и результирующее значение передается тем процессам, которые в нем нуждаются. Примерные значения пиковой производительности для различных типов систем класса MIMD показаны на рис. 14.1.
Симметричные мультипроцессорные системы
До сравнительно недавнего времени практически все однопользовательские персональные ВМ и рабочие станции содержали по одному микропроцессору общего назначения. По мере возрастания требований к производительности и снижения стоимости микропроцессоров поставщики вычислительных средств как альтернативу однопроцессорнымВМсталипредлагатьсимметричныемультипроцессорныевычис- лительныесистемы,такназываемыеSMP-системы(SMP,SymmetricMultiprocessor). Это понятие относится как к архитектуре ВС, так и к поведению операционной системы, отражающему данную архитектурную организацию. SMP можно определить как вычислительную систему, обладающую следующими характеристиками:
-Имеются два или более процессоров сопоставимой производительности.
-Процессоры совместно используют основную память и работают в едином виртуальном и физическом адресном пространстве.
-Все процессоры связаны между собой посредством шины или по иной схеме, так что время доступа к памяти любого из них одинаково.
-Все процессоры разделяют доступ к устройствам ввода/вывода либо через одни
ите же каналы, либо через разные каналы, обеспечивающие доступ к одному
итому же внешнему устройству.


Симметричные мультипроцессорные системы 5 8 9
-Расширяемость. Производительность системы может быть увеличена добавлением дополнительных процессоров.
-Масштабируемость. Варьируя число процессоров в системе, можно создать системы различной производительности и стоимости.
Необходимо отметить, что перечисленное — это только потенциальные преимущества, реализация которых невозможна, если в операционной системе отсутствуют средства; для поддержки параллелизма.
Архитектура SMP-системы
На рис. 14.3 в самом общем виде показана архитектура симметричной мультипроцессорной ВС.
Рис. 14.3. Организация симметричной мультипроцессорной системы
Типовая SMP-система содержит от двух до 32 идентичных процессоров, в качестве которых обычно выступают недорогие RISC-процессоры, такие, например, как DEC Alpha, Sun SPARC, MIPS или HP PA-RISC. В последнее время наметилась тенденция оснащения SMP-систем также и CISC-процессорами, в частности Pentium.
Каждый процессор снабжен локальной кэш-памятью, состоящей из кэш-памя- ти первого (L1) и второго (L2) уровней. Согласованность содержимого кэш-памяти всех процессоров обеспечивается аппаратными средствами. В некоторых SMPсистемах проблема когерентности снимается за счет совместно используемой кэшпамяти (рис. 14.4). К сожалению., этот прием технически и экономически оправдан лишь, если число процессоров не превышает четырех. Применение общей кэш-памяти сопровождается повышением стоимости и снижением быстродействия кэш-памяти.
Все процессоры ВС имеют равноправный доступ к разделяемым основной памяти и устройствам ввода/вывода. Такая возможность обеспечивается коммуникационной системой. Обычно процессоры взаимодействуют между собой через основную память (сообщения и информация о состоянии оставляются в области общих данных). В некоторых SMP-системах предусматривается также прямой обмен сигналами между процессорами.
Память системы обычно строится по модульному принципу и организована так, чтодопускается одновременное обращение к разным ее модулям (банкам). В неко-

5 9 0 Глава 14. Вычислительные системы класса MIMD
Рис. 14.4. SMP-система с совместно используемой кэш-памятью
торых конфигурациях в дополнение к совместно используемым ресурсам каждый процессор обладает также собственными локальной основной памятью и каналами ввода/вывода.
Важным аспектом архитектуры симметричных мультипроцессоров является способ взаимодействия процессоров с общими ресурсами (памятью и системой ввода/вывода). С этих позиций можно выделить следующие виды архитектуры SMP-систем:
-с общей шиной и временным разделением;
-с коммутатором типа «кроссбар»;
-с многопортовой памятью;
-с централизованным устройством управления.
Архитектура с общей шиной
Структура и интерфейсы общей шины в основном такие же, как и в однопроцессорной ВС, где шина служит для внутренних соединений (рис. 14.5).
Рис. 14.5. Структура SMP-системы собщей шиной
Достоинства и недостатки систем коммуникации на базе общей шины с разделением времени достаточно подробно обсуждались ранее. Применительно к SMPсистемам отметим, что физический интерфейс, а также логика адресации, арбитража и разделения времени остаются теми же, что и в однопроцессорных системах.

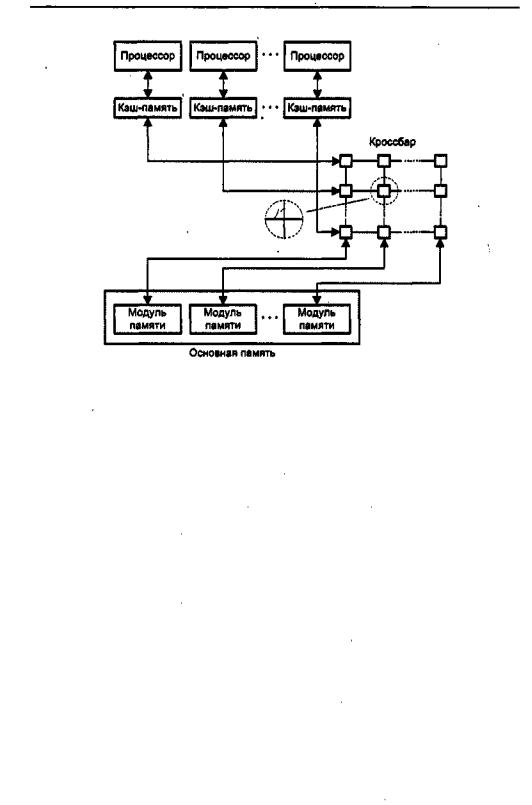

Кластерные вычислительные системы 5 9 3
поскольку требует придания ЗУ основной памяти дополнительной, достаточно сложной логики. Тем не менее это позволяет поднять производительность, так как каждый процессор имеет выделенный тракт к каждому модулю ОП. Другое преимущество многопортовой организации — возможность назначить отдельные модули памяти в качестве локальной памяти отдельного процессора. Эта особенность позволяет улучшить защиту данных от несанкционированного доступа со стороны других процессоров.
Архитектура с централизованным устройствомуправления
Централизованное устройство управления (ЦУУ) сводит вместе отдельные потоки данных между независимыми модулями: процессором, памятью, устройствами ввода/вывода. ЦУУ может буферйзировать запросы, выполнять синхронизацию и арбитраж. Оно способно передавать между процессорами информацию о состоянии и управляющие сообщения, а также предупреждать об изменении информации в кэшах. Недостаток такой организации заключается в сложности устройства управления, что становится потенциальнымузким местом в плане производительности. В настоящее время подобная архитектура встречается достаточно редко, но она широко использовалась при создании вычислительных систем на базе машин семейства IBM 370.
Кластерные вычислительные системы
Одно из самых современных направлений в области создания вычислительных систем — это кластеризация. По производительности и коэффициенту готовности кластеризация представляет собой альтернативу симметричным мультипроцессорным системам. Понятие кластер определим как группу взаимно соединенных вычислительных систем (узлов), работающих совместно, составляя единый вычислительный ресурс и создавая иллюзию наличия единственной ВМ. В качестве узла кластера может выступать как однопроцессорная ВМ, так и ВС типа SMP или МРР. Важно лишь то, что каждый узел в состоянии функционировать самостоятельно и отдельно от кластера. В плане архитектуры суть кластерных вычислений сводится к объединению нескольких узлов высокоскоростной сетью. Для описания такого подхода, помимо термина «кластерные вычисления», достаточно часто применяют такие названия, как: кластеррабочихстанций (workstationcluster),гипервычисления(hypercomputing), параллельные вычисления на базе сети (network-based concurrent computing), ультравычисления (ultracomputing).
Изначально перед кластерами ставились две задачи: достичь большой вычислительной мощности и обеспечить повышенную надежность ВС. Пионером в области кластерных архитектур считается корпорация DEC, создавшая первый коммерческий кластер в начале 80-х годов прошлого века.
В качестве узлов кластеров могут использоваться как одинаковые ВС (гомогенные кластеры), так и разные (гетерогенные кластеры). По своей архитектуре кластерная ВС является слабо связанной системой.

5 9 4 Глава 14. Вычислительные системы класса MIMD
В работе [65] перечисляются четыре преимущества, достигаемые с помощью кластеризации:
-Абсолютная масштабируемость. Возможно создание больших кластеров, превосходящих по вычислительной мощности даже самые производительные одиночные ВМ. Кластер в состоянии содержать десятки узлов, каждый из которых представляет собой мультипроцессор.
-Наращиваемая масштабируемость. Кластер строится так, что его можно наращивать, добавляя новыеузлы небольшими порциями. Таким образом, пользователь может начать с умеренной системы, расширяя ее по мере необходимости.
-Высокий коэффициент готовности. Поскольку каждый узел кластера — самостоятельная ВМ или ВС, отказ одного из узлов не приводит к потере работоспособности кластера. Во многих системах отказоустойчивость автоматически поддерживается программным обеспечением.
-Превосходное соотношение цена/производительность. Кластер любой производительности можно создать, соединяя стандартные «строительные блоки»-, при этом его стоимость будет ниже, чем у одиночной ВМ с эквивалентной вычислительной мощностью.
На уровне аппаратного обеспечения кластер — это просто совокупность независимых вычислительных систем, объединенных сетью. При соединении машин в кластер почти всегда поддерживаются прямые межмашинные связи. Решения могут быть простыми, основывающимися на аппаратуре Ethernet, или сложными с высокоскоростными сетями с пропускной способностью в сотни мегабайтов в секунду. К последней категории относятся RS/6000 SP компании IBM, системы фирмы Digital на основе Memory Channel, ServerNet корпорации Compaq.
Узлы кластера контролируют работоспособность друг друга и обмениваются специфической,характернойдля кластераинформацией. Контрольработоспособности осуществляется с помощью специального сигнала, часто называемого heartbeat, что можно перевести как «сердцебиение». Этот сигнал передается узлами кластера друг другу, чтобы подтвердить их нормальное функционирование.
Неотъемлемая часть кластера — специализированное программное обеспечение (ПО), на которое возлагается задача обеспечения бесперебойной работы при отказе одного или нескольких узлов. Такое ПО производит перераспределение вычислительной нагрузки при отказеодного или нескольких узлов кластера, а также восстановление вычислений при сбое в узле. Кроме того, при наличии в кластере совместно используемых дисков кластерное ПО поддерживает единую файловую систему.
Классификация архитектур кластерных систем
Влитературе приводятся различные способы классификации кластеров. Так,
впростейшем варианте ориентируются на то, являются ли диски в кластере разделяемыми всеми узлами. На рис. 14.8, а показан кластер из двух узлов, совместная работа которых координируется за счет высокоскоростной линии, по которой происходит обмен сообщениями. Такой линией может быть локальная сеть, используемая также и не входящими в кластер компьютерами, либо выделенная линия.