

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfКластерныевычислительные системы 5 9 5
В последнем случае один или несколько узлов кластера будут иметь выход на локальную или глобальную сеть, благодаря чему обеспечивается связь между серверным кластером и удаленными клиентскими системами.
б
Рис. 14.8. Конфигурации кластеров:а — безсовместно используемыхдисков; б — с совместно используемыми дисками
Более ясную картину дает группировка кластеров на основе сходства их функциональных особенностей. Такая классификация приведена в табл. 14.1.
Таблица 14.1. Методы кластеризации

5 9 6 Глава 14. Вычислительные системы класса MIMD
Кластеризация с резервированием — наиболее старый и универсальный метод. Один из серверов берет на себя всю вычислительную нагрузку, в то время как второй остается неактивным, но готовым перенять вычисления при отказе основного сервера. Активный или первичный сервер периодически посылает резервномутактирующее сообщение. При отсутствии тактирующих сообщений (это рассматривается как отказ первичного сервера) вторичный сервер берет управление на себя. Такой подход повышает коэффициент готовности, но не улучшает производительности. Более того, если единственный вид взаимодействия между узлами — обмен сообщениями, и если оба сервера кластера не используют диски коллективно, то резервный сервер не имеет доступа к базам данных, управляемым первичным сервером.
Пассивное резервирование для кластеров не характерно. Термин «кластер» относят к множеству взаимосвязанных узлов, активно участвующих в вычислительном процессе и совместно создающих иллюзию одной мощной вычислительной машины. Ктакой конфигурации обычно применяют понятие системысактивным вторичным сервером, и здесь выделяют три метода кластеризации: самостоятельные серверы, серверы без совместного использования дисков и серверы с совместным использованием дисков.
При первом подходе каждый узел кластера рассматривается как самостоятельный сервер с собственными дисками, причем ни один из дисков в системе не является общим (см. рис. 14.8, я). Схема обеспечивает высокую производительностьи высокийкоэффициентготовности, однакотребуетспециального программного обеспечения для планирования распределения клиентских запросов по серверам так, чтобы добиться сбалансированной и эффективной нагрузки на каждый из них. Необходимо также создать условия, чтобы при отказе одного из узлов в процессе выполнения какого-либо приложения другой узел мог перехватить и завершить оставшееся без управления приложение. Для этого данные в кластере должны постоянно копироваться, чтобы каждый сервер имел доступ ко всем наиболее свежим данным в системе. Из-за этих издержек высокий коэффициент готовности достигается лишь за счет потери производительности.
Для сокращения коммуникационных издержек большинство кластеров в настоящее время формируют из серверов, подключенных к общим дискам, обычно представленных дисковым массивом RAID ('рис. 14.8,6).
Один из вариантов такого подхода предполагает, что совместный доступ кдискам не применяется. Общие диски разбиваются на разделы, и каждому узлу кластера выделяется свой раздел. Если один из узлов отказывает, кластер может быть реконфигурирован так, что права доступа к его части общего диска передаются другому узлу.
Во втором варианте множество серверов разделяют во времени доступ к общим дискам, так что любой узел имеет возможность обратиться к любому разделу каждого общего диска. Эта организация требует наличия каких-либо средств блокировки, гарантирующих, что в любой момент времени доступ к данным будет иметь только один из серверов.
Вычислительные машины (системы) в кластере взаимодействуют в соответствии с одним их двух транспортных протоколов. Первый из них, протокол TCP (Transmission Control Protocol), оперирует потоками байтов, гарантируя надеж-

Кластерные вычислительные системы 5 9 7
ность доставки сообщения. Второй — UDP (User Datagram Protocol) пытается посылать пакеты данных без гарантии их доставки, В последнее время применяют специальные протоколы, которые работают намного лучше. Так, возглавляемый компанией Intel консорциум (Microsoft, Compaq и др.) предложил новый протокол для внутрикластерных коммуникаций, который называется Virtual Interface Architecture (VIA) и претендует на роль стандарта.
При обмене информацией используются два программных метода: передачи сообщенийираспределеннойсовместноиспользуемойпамяти.Первыйопирается на явную передачу информационных сообщений между узлами кластера. В альтернативном варианте также происходит пересылка сообщений, но движение данных между узлами кластера скрыто от программиста.
Кластеры обеспечивают высокий уровень доступности — в них отсутствуют единая операционная система и совместно используемая память, то есть нет проблемы когерентности кэшей. Кроме того, специальное программное обеспечение в каждом узле постоянно контролирует работоспособность всех остальных узлов. Этот контроль основан на периодической рассылке каждым узлом сигнала «Пока жив» (keepalive). Если сигнал от некоторого узла не поступает, то такой узел считается вышедшим из строя; ему не дается возможность выполнять ввод/вывод, его диски и другие ресурсы (включая сетевые адреса) переназначаются другим узлам, а выполнявшиеся им программы перезапускаются в других узлах.
Кластеры хорошо масштабируются в плане производительности при добавлении узлов. В кластере может выполняться несколько отдельных приложений, но для масштабирования отдельного приложения требуется, чтобы его части согласовывали свою работу путем обмена сообщениями. Нельзя, однако, не учитывать, что взаимодействия между узлами кластера занимают гораздо больше времени, чем в традиционных ВС.
Возможность практически неограниченного наращивания числа узлов и отсутствие единой операционной системы делают кластерные архитектуры исключительно успешно масштабируемыми, и даже системы с сотнями и тысячами узлов показывают себя на практике с положительной стороны.
Топологии кластеров
При создании кластеров с большим количеством узлов могут применяться самые разнообразные топологии (см. главу 12). В данном разделе остановимся на тех, которые характерны для наиболее распространенных «малых»- кластеров, состоящих из 2-4 узлов.
Топология кластерныхпар
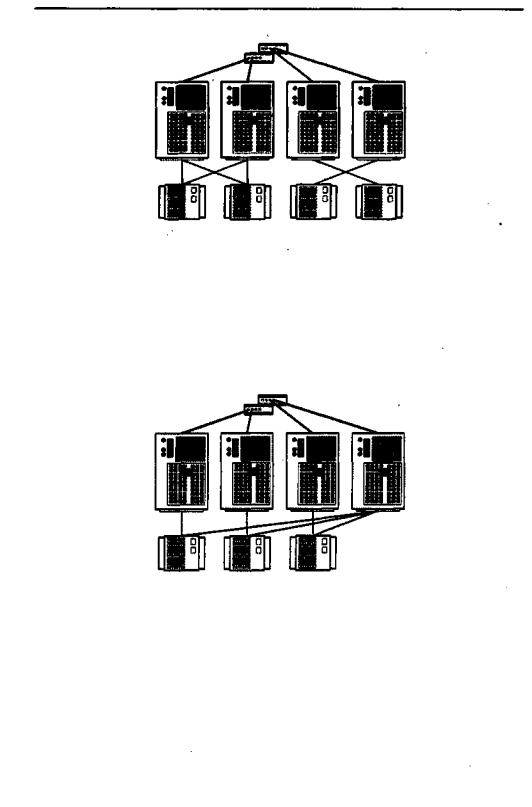
Топология кластерных пар находит применение при организации двухили четырехузловых кластеров (рис. 14.9).
Узлы группируются попарно. Дисковые массивы присоединяются к обоим узлам пары, причем каждый узел имеет доступ ко всем дисковым массивам своей пары. Один из узлов является резервным для другого.
Четырехузловая кластерная «пара»- представляет собой простое расширение двухузловой топологии. Обе кластерные пары с точки зрения администрирования и настройки рассматриваются как единое целое.
5 9 8 Глава 14. Вычислительные системы класса MIMD
Рис. 14.9.Топологиякластерныхпар
Эта топология подходит для организации кластеров с высокой готовностью данных, но отказоустойчивость реализуется только в пределах пары, так как принадлежащие ей устройства хранения информации не имеют физического соединения с другой парой.
Пример: организация параллельной работы СУБД Informix XPS.
Топология N +1
Топология N+ 1 позволяет создавать кластеры из2,3и4 узлов (рис. 14.10).
Рис. 14.10. Топология N +1
Каждый дисковый массив подключаются только к двум узлам кластера. Дисковые массивы организованы по схеме RAID 1. Один сервер имеет соединение со всеми дисковыми массивами и служит в качестве резервного для всех остальных (основных или активных) узлов. Резервный сервер может использоваться для поддержания высокой степени готовности в паре с любым из активных узлов.
Топология рекомендуется для организации кластеров высокой готовности. В тех конфигурациях, где имеется возможность выделить один узел для резервирования, эта топология способствует уменьшению нагрузки на активные узлы и гарантирует, что нагрузка вышедшего из строя узла будет воспроизведена на резервном узле без потери производительности. Отказоустойчивость обеспечивается между

6 0 0 Глава 14. Вычислительные системы класса MlМD
N x N обеспечивают поддержку приложения Oracle Parallel Server, требующего соединения всех узлов со всеми системами хранения информации. В целом топология характеризуется лучшей отказоустойчивостью и гибкостью по сравнению с другими решениями.
Топология с полностью раздельным доступом
В топологии с полностью раздельным доступом (рис. 14.12) каждый дисковый массив соединяется только с одним узлом кластера.
Топология рекомендуется только для тех приложений, для которых характерна архитектура полностью раздельного доступа, например для уже упоминавшейся СУБД Informix XPS.
Системы с массовой параллельной обработкой (МРР)
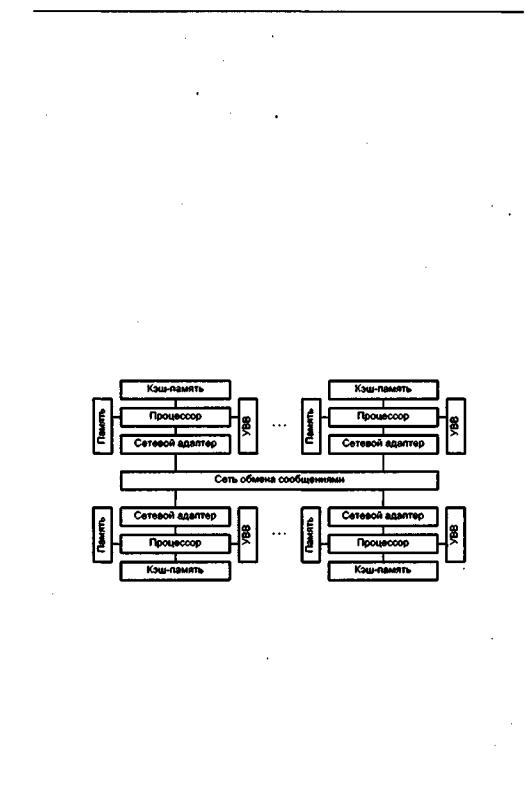
Основным признаком, по которому вычислительную систему относят к архитектуре с массовой параллельной обработкой (МРР, Massively Parallel Processing), служит количество процессоров п. Строгой границы не существует, но обычно при п>=128считается,чтоэтоужеМРР,априп<=32—ещенет.Обобщеннаяструктура МРР-системы показана на рис. 14.13.
Рис. 14.13. Структура вычислительной системы с массовой параллельной обработкой
Главные особенности, по которым вычислительную систему причисляют к классу МРР, можно сформулировать следующим образом:
-стандартные микропроцессоры;
-физически распределенная память;
-сеть соединений с высокой пропускной способностью и малыми задержками;
-хорошая масштабируемость (до тысяч процессоров);
-асинхронная MIMD-система с пересылкой сообщений;
-программа представляет собой множество процессов, имеющих отдельные адресные пространства.

Системы с массовой параллельной обработкой (МРР) 6 0 1
Основные причины появления систем с массовой параллельной обработкой — это, во-первых, необходимость построения ВС с гигантской производительностью и, во-вторых, стремление раздвинуть границы производства ВС в большом диапазоне, как производительности, так и стоимости. Для МРР-системы, в которой количество процессоров может меняться в широких пределах, всегда реально подобрать конфигурацию с заранее заданной вычислительной мощностью и финансовыми вложениями.
Если говорить о МРР как о представителе класса MIMD с распределенной памятью и отвлечься от организации ввода/вывода, то эта архитектура является естественным расширением кластерной на большое число узлов. Отсюда для МРРсистем характерны все преимущества и недостатки кластеров, причем в связи с повышенным числом процессорных узлов как плюсы, так и минусы становятся гораздо весомее.
Характерная черта МРР-систем — наличие единственного управляющего устройства (процессора), распределяющего задания между множеством подчиненных ему устройств, чаще всего одинаковых (взаимозаменяемых), принадлежащих одному или нескольким классам. Схема взаимодействия в общих чертах довольно проста:
-центральное управляющее устройство формирует очередь заданий, каждому из которых назначается некоторый уровень приоритета;
-по мере освобождения подчиненных устройств им передаются задания из очереди;
-подчиненные устройства оповещают центральный процессор о ходе выполнения задания, в частности о завершении выполнения или о потребности в дополнительных ресурсах;
-у центрального устройства имеются средства для контроля работы подчинен-
ных процессоров, в том числе для обнаружения нештатных ситуаций, прерыва- . ния выполнения задания в случае появления более приоритетной задачи и т. п.
В некотором приближении имеет смысл считать, что на центральном процессоре выполняется ядро операционной системы (планировщик заданий), а на подчиненных ему — приложения. Подчиненность между процессорами может быть реализована как на аппаратном, так и на программном уровне.
Вовсе не обязательно, чтобы МРР-система имела распределенную оперативную память, когда каждый процессорный узел владеет собственной локальной памятью. Так, например, системы SPP1000/XA и SPP1200/XA [43] являют собой пример ВС с массовым параллелизмом, память которых физически распределена между узлами, но логически она общая для всей вычислительной системы. Тем не менее большинство МРР-систем имеют как логически, так и физически распределенную память.
Благодаря свойству масштабируемости, МРР-системы являются сегодня лидерами по достигнутой производительности; наиболее яркий пример этому — Intel Paragon с 6768 процессорами. С другой стороны, распараллеливание в МРР-сис- темах по сравнению с кластерами, содержащими немного процессоров, становится еще более трудной задачей. Следует помнить, что приращение производительности с ростом числа процессоров обычно вообще довольно быстро убывает (см. закон

6 0 2 Глава 14. Вычислительные системы класса MlМD
Амдала). Кроме того, достаточно трудно найти задачи, которые сумели бы эффективно загрузить множество процессорных узлов. Сегодня нетак уж много приложениймогутэффективновыполняться наМРР-системе, Имеет местотакжепроблема переносимости программ между системами с различной архитектурой. Эффективность распараллеливания во многих, случаях сильно зависит от деталей архитектуры МРР-системы, например топологии соединения процессорных узлов.
Самой эффективной была бы топология, в которой любой узел мог бы напрямую связаться с любым другим узлом, но в ВС на основе МРР это технически трудно реализуемо. Как правило, процессорные узлы в современных МРР-компь- ютерах образуют или двухмерную решетку (например, в SNI/Pyramid RM1000) или гиперкуб (как в суперкомпьютерах nCube [8]).
Поскольку для синхронизации параллельно выполняющихся процессов необходим обмен сообщениями, которые должны доходить из любого узла системы в любой другой узел, важной характеристикой является диаметр системы D. В случае двухмерной решетки D - sqrt(n), в случае гиперкуба D - 1n(n). Таким образом, при увеличении числа узлов более выгодна архитектура гиперкуба.
Время передачи информации от узла к узлу зависит от стартовой задержки и скорости передачи. В любом случае, за время передачи процессорные узлы успевают выполнить много команд, и это соотношение быстродействия процессорных узлов и передающей системы, вероятно, будет сохраняться — прогресс в производительности процессоров гораздо весомее, чем в пропускной способности каналов связи. Поэтому инфраструктура каналов связи в МРР-системах является объектом наиболее пристального внимания разработчиков.
Слабым местом МРР было и есть центральное управляющее устройство (ЦУУ) - при выходе его из строя вся система оказывается неработоспособной. Повышение надежности ЦУУ лежит на путях упрощения аппаратуры ЦУУ и/или ее дублирования.
Несмотря на все сложности, сфера применения ВС с массовым параллелизмом постоянно расширяется. Различные системы этого класса эксплуатируются во многих ведущих суперкомпьютерных центрах мира. Следует особенно отметить компьютеры Cray T3D и Cray T3E, которые иллюстрируют тот факт, что мировой лидер производства векторных суперЭВМ, компания Cray Research, уже не ориентируется исключительно на векторные системы. Наконец, нельзя не вспомнить, что суперкомпьютерный проект министерства энергетики США основан на МРРсистеме на базе Pentium.
На рис. 14.14 показана структура МРР-системы RM1000, разработанной фирмой Pyramid.
В RM1000 используются микропроцессоры типа MIPS. Каждый узел содержит процессор R4400, сетевую карту Ethernet и два канала ввода/вывода типа SCSI. Реализованный вариант включает в себя 192 узла, но сеть соединений предусматривает масштабирование до 4096 узлов. Каждый узел имеет коммуникационный компонент для подключения к соединяющей сети, организованной по топологии двухмерной решетки. Связь с решеткой поддерживается схемами маршрутизации, с четырьмя двунаправленными линиями для связи с соседними узлами и одной линией для подключения к данному процессорному узлу. Скорость передачи информации в каждом направлении — 50 Мбит/с.
Вычислительные системы с неоднородным доступом к памяти 6 0 3
Рис. 14.14. Структура МРР-системы RM1000
Каждый узел работает под управлением своей копии операционной системы, управляет «своими»- периферийными устройствами и обменивается с другими узлами путем пересылки сообщений по сети соединений. Операционная система содержит средства для повышения надежности и коэффициента готрвности.
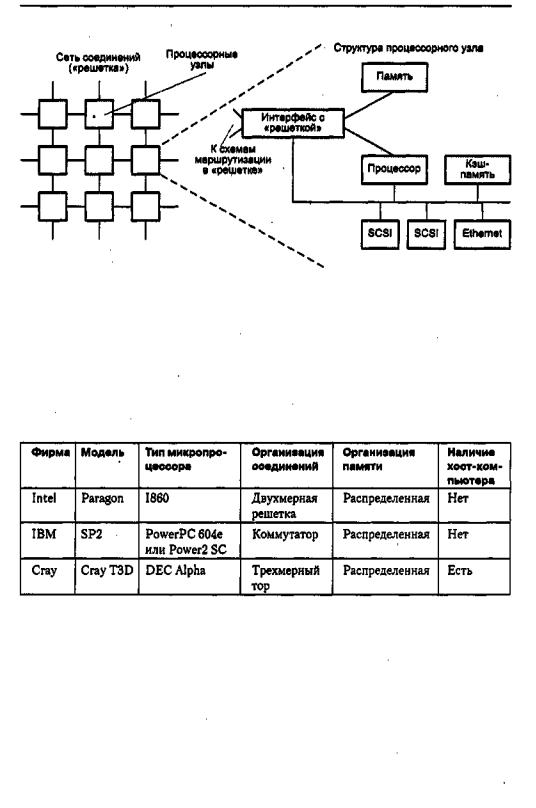
Отметим, что при создании МРР-систем разные фирмы отдают предпочтение различным микропроцессорам и топологиям сетей соединений (табл, 14.2).
Таблица 14.2. Основныехарактеристики некоторыхМРР-систем
Вычислительныесистемыснеоднородным доступом к памяти
Основные платформы, обычно применяемые при создании коммерческих мультипроцессорных систем, это SMP, МРР и кластеры. Наряду с ними в последнее время стали появляться решения, в которых акцентируется способ организации памяти. Речь идет о ВС, построенных в соответствии с технологией неоднородного доступа к памяти (NUMA, Non-Uniform Memory Access), точнее с кэш-когерент- ным доступом к неоднородной памяти (CC-NUMA).

6 0 4 Глава 14. Вычислительные системы класса MIMD
В симметричных мультипроцессорных вычислительных системах (SMP) имеет место практический предел числа составляющих их процессоров. Эффективная схема с кэш-памятью уменьшаеттрафик шины между процессором и основной памятью, но по мере увеличения числа процессоров трафик шины также возрастает. Поскольку шина используется также для передачи сигналов, обеспечивающих когерентность, ситуация с трафиком еще более напрягается. С какого-то момента в плане производительности шина превращается вузкое место. Для систем типа SMP таким пределом становится число процессоров в пределах от 16 до 64. Например, объем SMP-системы Silicon Graphics Power Challenge ограничен 64 процессорами R10000, поскольку при дальнейшем увеличении числа процессоров производительность падает.
Ограничение на число процессоров в архитектуре SMP служит побудительным мотивом для развития кластерных систем, В последних же каждый узел имеет локальную основную память, то есть приложения «не видят» глобальной основной памяти. Всущности, когерентность поддерживаетсянестолькоаппаратурой,сколько программным обеспечением, что не лучшим образом сказывается на продуктивности. Одним из путей создания крупномасштабных вычислительных систем являетсятехнология CC-NUMA. Например,NUMA-системаSilicon Graphics Origin поддерживает до 1024 процессоров R10000 [223], a Sequent NUMA-Q объединяет 252 процессора Pentium II [157].
На рис. 14.15 показана типичная организация систем типа CC-NUMA [36]. Имеется множество независимых узлов, каждый из которых может представлять собой, например, SMP-систему. Таким образом, узел содержит множествопроцессоров, у каждого из которых присутствуют локальные кэши первого (L1) и второго (L2) уровней. В узле есть и основная память, общая для всех процессоров этого узла, но рассматриваемая как часть глобальной основной памяти системы, В архитектуре CC-NUMA узел выступает основным строительным блоком. Например, каждый узел в системе Silicon Graphics Origin содержитдва микропроцессора MIPS R10000, а каждый узел системы Sequent NUMA-Q включает в себя четыре процессора Pentium II. Узлы объединяются с помощью какой-либо сети соединений, которая представлена коммутируемой матрицей, кольцом или имеет иную топологию.
Согласно технологии CC-NUMA, каждый узел в системе владеет собственной основной памятью, но с точки зрения процессоров имеет место глобальная адресуемая память, где каждая ячейка любой локальной основной памяти имеет уникальный системный адрес. Когда процессор инициирует доступ к памяти и нужная ячейка отсутствует в его локальной кэш-памяти, кэш-память второго уровня (L2) процессора организует операцию выборки. Если нужная ячейка находится в локальной основной памяти, выборка производится с использованием локальной шины. Если же требуемая ячейка хранится в удаленной секции глобальной памяти,тоавтоматическиформируетсязапрос, посылаемыйпосетисоединений нанужную локальную шину и уже по ней к подключенному к данной локальной шине кэшу. Все эти действия выполняются автоматически, прозрачны для процессора
иего кэш-памяти,
Вданной конфигурации главная забота — когерентность кэшей. Хотя отдельные реализации и отличаются в деталях, общим является то, что каждый узел со-