

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfМетрики параллельных вычислений 4 8 5
значенное как T(Ai), существенно различается в зависимости от того, является ли результат истинным или ложным.
Пусть
Таким образом, параллельные вычисления на двух процессорах ведут к среднему ускорению:
Отметим, что суперлинейное ускорение вызвано жесткостью последовательной обработки, так как после вычисления еще нужно проверить А2.
Кфакторам, ограничивающим ускорение, следует отнести:
-Программные издержки. Даже если последовательные и параллельные алгоритмы выполняют одни и те же вычисления, параллельным алгоритмам присущи добавочные программные издержки — дополнительные индексные вычисления, неизбежно возникающие из-за декомпозиции данных и распределения их по процессорам; различные виды учетных операций, требуемые в параллельных алгоритмах, но отсутствующие в алгоритмах последовательных.
-Издержки из-за дисбаланса загрузки процессоров. Между точками синхронизации каждый из процессоров должен быть загружен одинаковым объемом работы, иначе часть процессоров будет ожидать, пока остальные завершат свои операции. Эта ситуация известна как дисбаланс загрузки. Таким образом, ускорение ограничивается наиболее медленным из процессоров.
-Коммуникационные издержки. Если принять, что обмен информацией и вычисления могут перекрываться, то любые коммуникации между процессорами снижают ускорение. В плане коммуникационных затрат важен уровень гранулярности, определяющий объем вычислительной работы, выполняемой между коммуникационными фазами алгоритма. Для уменьшения коммуникационных издержек выгоднее, чтобы вычислительные гранулы были достаточно крупными и доля коммуникаций была меньше.
Еще одним показателем параллельных вычислений служит качество параллельного выполнения программ — характеристика, объединяющая ускорение, эффективность и избыточность. Качество определяется следующим образом:

4 8 6 Глава 10. Параллелизм как основавысокопроизводительных вычислений
Поскольку как эффективность, так и величина, обратная избыточности, представляютсобойдроби, то Q(n) <=S(n).ПосколькуЕ(п) —этовсегдадробь, a R(n) - число между 1 и и, качество Q(n) при любых условиях ограничено сверху величиной ускорения S(n).
Закон Амдала
Приобретая для решения своей задачи параллельную вычислительную систему, пользователь рассчитывает на значительное повышение скорости вычислений за счет распределения вычислительной нагрузки по множеству параллельно работающих процессоров. В идеальном случае система из и процессоров могла бы ускорить вычисления в п раз, В реальности достичь такого показателя по ряду причин не удается. Главная из этих причин заключается в невозможности полного распараллеливания ни одной из задач. Как правило, в каждой программе имеется фрагменткода, который принципиальнодолженвыполняться последовательно итолько одним из процессоров. Это может быть часть программы, отвечающая за запуск задачи и распределение распараллеленного кода по процессорам, либо фрагмент программы, обеспечивающий операции ввода/вывода. Можно привести и другие примеры, но главное состоит в том, что о полном распараллеливании задачи говорить не приходится. Известные проблемы возникают и с той частью задачи, которая поддается распараллеливанию. Здесь идеальным был бы вариант, когда параллельные ветви программы постоянно загружали бы все процессоры системы, причем так, чтобы нагрузка на каждый процессор была одинакова. К сожалению, оба этих условия на практике трудно реализуемы. Таким образом, ориентируясь на параллельную ВС, необходимочеткосознавать,чтодобиться прямопропорционального числу процессоров увеличения производительности не удастся, и, естественно, встает вопрос о том, на какое реальное ускорение можно рассчитывать. Ответ на этот вопрос в какой-то мере дает закон Амдала.
Джин Амдал (Gene Amdahl) — один из разработчиков всемирно известной Системы IBM 360, в своей работе [48], опубликованной в 1967 году, предложил формулу, отражающую зависимость ускорения вычислений, достигаемого на многопроцессорной ВС, от числа процессоров и соотношения между последовательной и параллельной частями программы. Показателем сокращения времени вычислений служит такая метрика, как "ускорение". Напомним, что ускорение 5 — этоотношение времени Ts, затрачиваемого на проведение вычислений на однопроцессорной ВС (в варианте наилучшего последовательного алгоритма), ко времени T, решения той же задачи на параллельной системе (при использовании наилучшего параллельного алгоритма):
Оговорки относительно алгоритмов решения задачи сделаны, чтобы подчеркнуть тот факт, что для последовательного и параллельного решения лучшими мо-

Закон Амдала 4 8 7
гут оказаться разные реализации, а при оценке ускорения необходимо исходить именно из наилучших алгоритмов.
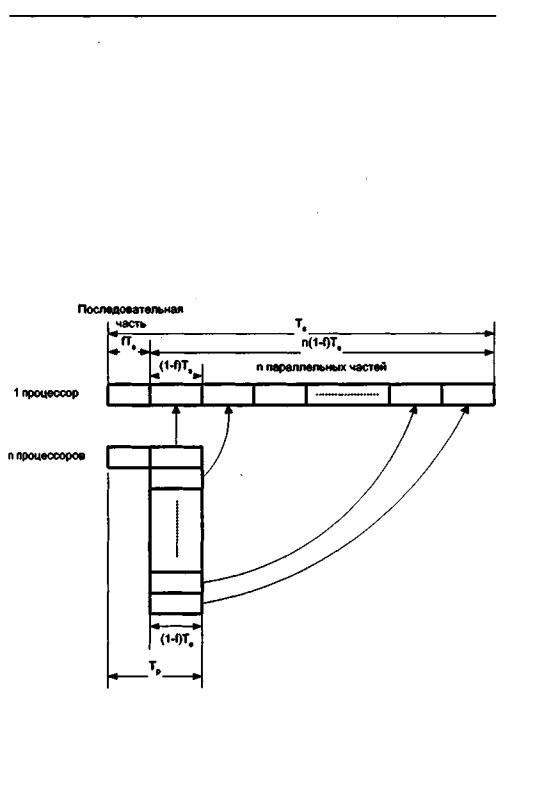
Проблема рассматривалась Амдалом в следующей постановке (рис. 10.2). Прежде всего, объем решаемой задачи с изменением числа процессоров, участвующих в ее решении-, остается неизменным. Программный код решаемой задачи состоит из двух частей: последовательной и распараллеливаемой. Обозначим долю операций, которыедолжны выполняться последовательно одним из процессоров, через f, где 0 <=f<= 1 (здесь доля понимается не по числу строк кода, а по числу реально выполняемых операций). Отсюда доля, приходящаяся на распараллеливаемую часть программы, составит 1 -f. Крайние случаи в значениях/соответствуют полностью параллельным (f= 0) и полностью последовательным (f- 1) программам. Распараллеливаемая часть программы равномерно распределяется по всем процессорам. ,
Рис. 10.2. КпостановкезадачивзаконеАмдала
С учетом приведенной формулировки имеем;
В результате получаем формулу Амдала, выражающую ускорение, которое может быть достигнуто на системе из п процессоров:

4 8 8 Глава 10. Параллелизм как основа высокопроизводительных вычислений
Формула выражает простую и обладающую большой общностью зависимость. Характер зависимости ускорения от числа процессоров и доли последовательной части программы показан на рис. 10.3.
Рис. 10.3. Графики зависимости ускорения от: а — доли последовательных вычислений; б — числа процессоров
Если устремить число процессоров к бесконечности, то в пределе получаем:
Это означает, что если в программе 10% последовательных операций (то есть /-0,1), то, сколько бы процессоров ни использовалось, убыстрения работы программы более чем в десять раз никак ни получить, да и то, 10 — это теоретическая верхняя оценка самого лучшего случая, когда никаких других отрицательных факторов нет. Следует отметить, что распараллеливание ведет к определенным издержкам, которых нет при последовательном выполнении программы. В качестве примера таких издержек можно упомянуть дополнительные операции, связанные с распределением программ по процессорам, обмен информацией между процессорами и т. д.
Закон Густафсона
Известную долю оптимизма в оценку, даваемую законом Амдала, вносят исследования, проведенные уже упоминавшимся Джоном Густафсоном из NASA Ames Research [115]. Решая на вычислительной системе из 1024 процессоров три больших задачи, для которых доля последовательного кода/лежала в пределах от 0,4 до 0,8%, он получил значения ускорения по сравнению с однопроцессорным вариантом, равные соответственно 1021,1020 и 1016. Согласно закону Амдала для данного числа процессоров и диапазона f, ускорение недолжно было превысить вели-
Закон Густафсона |
4 8 9 |
чины порядка 201. Пытаясь объяснить это явление, Густафсон пришел к выводу, что причина кроется в ИСХОДНОЙ предпосылке, лежащей в основе закона Амдала: увеличение числа процессоров не сопровождается увеличением объема решаемой задачи. Реальное же поведение пользователей существенно отличается от такого представления. Обычно, получая в свое распоряжение более мощную систему, пользователь не стремится сократить время вычислений, а, сохраняя его практически неизменным, старается пропорционально мощности ВС увеличить объем решаемой задачи. И тут оказывается, что наращивание общего объема программы касается главным образом распараллеливаемой части программы. Это ведет к сокрашению значения f. Примером может служить решение дифференциального уравнения в частных производных. Если доля последовательного кода составляет 10% для 1000 узловых точек, то для 100 000 точек доля последовательного кода снизится до 0,1%. Сказанное иллюстрирует рис. 10.4, который отражает тот факт, что, оставаясь практически неизменной, последовательная часть в общем объеме увеличенной программы имеет уже меньший удельный вес.
Рис. 10.4. К постановке задачи взаконе Густафсона
Было отмечено, что в первом приближении объем работы, которая может быть произведена параллельно, возрастает линейно с ростом числа процессоров в системе. Для того чтобы оценить возможность ускорения вычислений, когда объем

4 9 0 Глава 10. Параллелизм какоснова высокопроизводительных вычислений
последних увеличивается с ростом количества процессоров в системе (при постоянстве общего времени вычислений), Густафсон рекомендует использовать выражение, предложенное Е. Барсисом (Е. Barsis):
Данное выражение известно как закон масштабируемого ускорения или закон Густафсона (иногда его называют также законом Густафсона-Барсиса), В заключение отметим, что закон Густафсона не противоречит закону Амдала. Различие состоит лишь в форме утилизации дополнительной мощности ВС, возникающей при увеличении числа процессоров.
Классификация параллельных вычислительных систем
Даже краткое перечисление типов современных параллельных вычислительных систем (ВС) дает понять, что для ориентирования в этом многообразии необходима четкая система классификации. От ответа на главный вопрос — что заложить восновуклассификации —зависит,насколькоконкретнаясистемаклассификации помогает разобраться с тем, что представляет собой архитектура ВС и насколько успешно данная архитектура позволяет решать определенный круг задач. Попытки систематизировать все множество архитектур параллельных вычислительных систем предпринимались достаточно давно и длятся по сей день, но к однозначным выводам пока не привели. Исчерпывающий обзор существующих систем классификации ВС приведен в [5].
Классификация Флинна
Среди всех рассматриваемых систем классификации ВС наибольшее признание получила классификация, предложенная в 1966 году М. Флинном [99, 100]. В ее основу положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. В зависимости от количества потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD,SIMD, MIMD.
SISD
SISD (Single Instruction Stream/Single Data Stream) — одиночный поток команд и одиночный поток данных (рис. 10.5, а). Представителями этого класса являются, прежде всего, классические фон-неймановские ВМ, где имеется только один поток команд, команды обрабатываются последовательно и каждая команда инициирует одну операцию с одним потоком данных. То, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка, не имеетзначения, поэтому в класс SISD одновременно попадают как ВМ CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными. Некоторые специалисты считают, что к SISD-системам можно причислить и векторно-конвейерные ВС, если рассматривать вектор как неделимый элемент данных для соответствующей команды.

Классификация параллельных вычислительных систем 4 9 1
MISD
MISD (Multiple Instruction Stream/Single Data Stream) — множественный поток команд и одиночный потокданных (рис. 10.5, б). Из определения следует, что в архитектуре ВС присутствует множество процессоров, обрабатывающих один и тот же поток данных. Примером могла бы служить ВС, на процессоры которой подается искаженный сигнал, а каждый из процессоров обрабатывает этот сигнал с помощью своего алгоритма фильтрации. Тем не менее ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не сумели представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей [117,121,213] относят к данному классу конвейерные системы, однако это не нашло окончательного признания. Отсюда принято считать, что пока данный класс пуст. Наличие пустого класса не следует считать недостатком классификации Флинна. Такие классы, по мнению некоторых исследователей [84,192], могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
Рис. 10.5. Архитектура вычислительных систем по Флинну: а — SISD; б — MISD; в —SIMD;г —MIMD
SIMD
SIMD (Single Instruction Stream/Multiple Data Stream) — одиночный поток команд и множественный поток данных (рис. 10.5, в). ВМ данной архитектуры позволяют выполнять одну арифметическую операцию сразу над многими данными — элементами вектора. Бесспорными представителями класса SIMD считаются матрицы

4 9 2 Глава 10. Параллелизм как основа высокопроизводительных вычислений
процессоров, где единое управляющее устройство контролирует множество процессорных элементов. Все процессорные элементы получают от устройства управления одинаковую команду и выполняют ее над своими локальными данными. В принципе в этот класс можно включить и векторно-конвейерные ВС, если каждый элемент вектора рассматривать как отдельный элемент потока данных.
MIMD
MIMD (Multiple Instruction Stream/Multiple Data Stream) — множественный поток команд и множественный поток данных (рис. 10.5, г). Класс предполагает наличие в вычислительной системе множества устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы. Кроме того, приобщение к классу MIMD зависит от трактовки. Так, ранее упоминавшиеся векторно-конвейерные ВС можно вполне отнести и к классу MIMD, если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) над множественным скалярным потоком.
Схема классификации Флинна вплотьдо настоящего времениявляется наиболее распространенной при первоначальной оценке той или иной ВС, поскольку позволяет сразу оценить базовый принцип работы системы, чего часто бывает достаточно. Однако у классификации Флинна имеются и очевидные недостатки, например неспособность однозначно отнести некоторые архитектуры к тому или иному классу. Другая слабость — это чрезмерная насыщенность класса MIMD. Все это породило множественные попытки либо модифицировать классификацию Флинна, либо предложить иную систему классификации.
Контрольные вопросы
1.Сравните схемы классификации параллелизма по уровню и гранулярности. Каковы, на ваш взгляд, достоинства, недостатки и области применения этих схем классификации?
2.Для заданной программы и конфигурации параллельной вычислительной системы рассчитайте значения метрик параллельных вычислений.
3.ПояснитесутьзаконаАмдала,приведитепримеры,поясняющиеегоограничения.
4.Какую проблему закона Амдала решает закон Густафсона? Как он это делает? Сформулируйте области применения этих двух законов.
5.Укажите достоинства и недостатки схемы классификации Флинна.

Глава 11
Организация памяти вычислительных систем
В вычислительных системах, объединяющих множество параллельно работающих процессоров или машин, задача правильной организации памяти является одной из важнейших. Различие между быстродействием процессора и памяти всегда было камнем преткновения в однопроцессорных ВМ. Многопроцессорность ВС приводит еще к одной проблеме — проблеме одновременного доступа к памяти со сторонынесколькихпроцессоров.
Взависимости от того, каким образом организована память многопроцессорных (многомашинных) систем, различают вычислительные системы с общей памятью (shared memory) и ВС с распределенной памятью (distributed memory). В системах с общей памятью (ее часто называют также совместно используемой или разделяемой памятью) память ВС рассматривается как общий ресурс, и каждый из процессоров имеет полный доступ ко всему адресному пространству. Системы
собщей памятью называют сильно связанными (closely coupled systems). Подобное построение вычислительных систем имеет место как в классе SIMD, так и в массе MIMD. Иногда, чтобы подчеркнуть это обстоятельство, вводят специальные подклассы, используя для их обозначения аббревиатуры SM-SIMD (Shared Memory SIMD) и SM-MIMD (Shared Memory MIMD).
Вварианте с распределенной памятью каждому из процессоров придается собственная память. Процессоры объединяются в сеть и могут при необходимости обмениваться данными, хранящимися в их памяти, передавая другдругу так называемые сообщения. Такой вид ВС называют слабо связанными (loosely coupled systems). Слабо связанные системы также встречаются как в классе SIMD, так и в классе MIMD, и иной раз, чтобы подчеркнуть данную особенность, вводят подклассы DM-SIMD (Distributed MemorySIMD) и DM-MIMD (Distributed Memory MIMD).
Внекоторых случаях вычислительные системы с общей памятью называют
мультипроцессорами, а системы с распределенной памятью — мулътикомпьютерами.

4 9 4 Глава 11. Организация памяти вычислительныхсистем
Различие между общей и распределенной памятью — это разница в структуре виртуальной памяти, то есть в том, как память выгладит со стороны процессора. Физически почти каждая система памяти разделена на автономные компоненты, доступ к которым может производиться независимо. Общую память от распределенной отличает то, какимобразом подсистема памяти интерпретирует поступивший от процессора адрес ячейки. Для примера положим, что процессор выполняет команду Load RO,i,означающую "Загрузить регистр R0содержимымячейки i". В случае общей памяти i — это глобальный адрес, и для любого процессора указывает на одну и ту же ячейку. В распределенной системе памяти i — это локальный адрес. Если два процессора выполняют команду load RO, i, то каждый из них обращается к i-й ячейке в своей локальной памяти, то есть к разным ячейкам, и в регистры R0 могут быть загружены неодинаковые значения.
Различие между двумя системами памяти должно учитываться программистом, поскольку оно определяет способ взаимодействия частей распараллеленной программы. В варианте с общей памятью достаточно создать в памяти структуру данных и передавать в параллельно используемые подпрограммы ссылки на эту структуру. В системе с распределенной памятью необходимо в каждой локальной памяти иметь копию совместно используемых данных. Эти копии создаются путем вкладывания разделяемых данных в сообщения, посылаемые другим процессорам.
Памятьс чередованием адресов
Физически память вычислительной системы состоит из нескольких модулей (банков), при этом существенным вопросом является то, как в этом случае распределено адресное пространство (набор всех адресов, которые может сформировать процессор). Один из способов распределения виртуальных адресов по модулям памяти состоит в разбиении адресного пространства на последовательные блоки. Если память состоит из п банков, то ячейка с адресом i при поблочном разбиении будет находиться в банке с номером i/п. В системе памяти с чередованием адресов (interleaved memory) последовательные адреса располагаются в различных банках: ячейка с адресом i находится в банке с номером i mod п. Пусть, например, память состоит из четырех банков, по 256 байт в каждом. В схеме, ориентированной на блочную адресацию, первому банку будут выделены виртуальные адреса 0-255, второму - 256-511 и т. д. В схеме с чередованием адресов последовательные ячейки в первом банке будут иметь виртуальные адреса 0, 4, 8, ..„ во втором банке — 1, 5, 9 и т. д. (рис. 11.1, а).
Распределение адресного пространства по модулям дает возможность одновременной обработки запросов на доступ к памяти, если соответствующие адреса относятся к разным банкам. Процессор может в одном из циклов затребовать доступ к ячейке i, а в следующем цикле — к ячейке j Если i и j находятся в разных банках, информация будет передана в последовательных циклах..Здесь под циклом понимается цикл процессора, в то время как полный цикл памяти занимает несколько циклов процессора. Таким образом, в данном случае процессор не должен ждать, пока будет завершен полный цикл обращения к ячейке i. Рассмотренный прием позволяет повысить пропускную способность: если система памяти состоит из