

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfМультипроцессорная когерентность кэш-памяти 5 0 5
тупккэш-памяти. Тем неменееобщаязадержкаобращениякпамятивцелом уменьшается.
Некэшируемые данные. Проблемакогерентности имеет отношение к тем данным, которые в ходе выполнения программы могут быть изменены. Одно из вероятных решений — это запрет кэширования таких данных. Технически запрет на кэширование отдельных байтов и слов достаточно трудно реализуем. Несколько проще сделать некэшируемым определенный блок данных. При обращении процессора к такому блоку складывается ситуация кэш-промаха, производится доступ косновной памяти, но копияблока в кэш незаносится. Для реализации подобного приема каждому блоку в основной памяти должен быть придан признак, указывающий, является ли блок кэшируемым или нет.
Если кэш-система состоит из раздельных кэшей команд и данных, сказанное относится главным образом к кэш-памяти данных, поскольку современные подходы к программированию не рекомендуют модификацию команд программы. Следовательно, по отношению к информации в кэше команд применяется только операция чтения, что не влечет проблемы когерентности.
Вотношении того, какие данные не должны кэшироваться, имеется несколько подходов.
Впервом варианте запрещается занесение в кэш лишь той части совместно используемых данных, которая служит для управления критическими секциями программы, то есть теми частями программы, где процессоры могут изменять разделяемые ими данные. Принятие решения о том, какие данные могут кэшироваться,
акакие — нет, возлагается на программиста, что делает этот способ непрозрачным для пользователя.
Во втором случае накладывается запрет на кэширование всех совместно используемыхданных, которые в процессе выполнения программы могут быть изменены. Естественно, что для доступа к таким данным приходится обращаться к медленной основной памяти и производительность процессора падает. На первый взгляд, в варианте, гдезапрещается кэширование толькоуправляющей информации, производительность процессора будет выше, однако, прежде чем сделать такой вывод, нужно учесть одно обстоятельство. Дело в том, чтодля сохранения согласованности данных, модифицируемых процессором в ходе выполнения критической секции программы, строки с копиями этих данных в кэш-памяти при выходе из критической секции нужно аннулировать. Данная операция носит название очистки кэшпамяти (cache flush). Очистка необходима для того, чтобы к моменту очередного входа в критическую секцию в кэш-памяти не осталось "устаревших"- данных. Регулярная очистка кэша при каждом выходе из критической секции снижает производительность процессора за счет увеличения времени, нужного для восстановления копий в кэш-памяти. Ситуацию, можно несколько улучшить, если вместо очистки всей кэш-памяти помечать те блоки, к которым при выполнении критической секции было обращение, тогда при покидании критической секции достаточно очищать только эти помеченные блоки.
Широковещательная запись. При широковещательной записи каждый запрос на запись в конкретную кэш-память направляется также и всем остальным кэшам системы. Это заставляет контроллеры кэшей проверить, нетли там копии изменяе-

5 0 6 Глава 11. Организация памяти вычислительных систем
мого блока. Если такая копия найдена, то она аннулируется или обновляется,
в зависимости от применяемой схемы. Метод широковещательной записи связан
сдополнительными групповымиоперациями с памятью (транзакциями), поэтому он реализован лишь в больших вычислительных системах.
На двух последних возможностях поддержания когерентности в мультипроцессорных системах остановимся более подробно.
Протоколынаблюдения
В протоколахнаблюдения (snoopy protocols или просто snooping) ответственность за поддержание когерентности всех кэшей многопроцессорной системы возлагается на контроллеры кэшей. В системах, где реализованы протоколы наблюдения, контроллер каждой локальной кэш-памяти содержит блок слежения за шиной (рис. 11.8), который следит за всеми транзакциями на общей шине и, в частности, контролирует все операции записи. Процессоры должны широковещательно передавать на шину любые запросы на доступ к памяти, потенциально способные изменить состояние когерентности совместно используемых блоков данных. Локальный контроллер кэш-памяти каждого процессора затем определяет, присутствует ли в его кэш-памяти копия модифицируемого блока, и если это так, то такой блок аннулируется или обновляется.
Протоколы наблюдения характерны для мультипроцессорных систем на базе шины, поскольку общая шина достаточно просто обеспечивает как наблюдение, так и широковещательную передачу сообщений. Однако здесь необходимо приниматьмеры,чтобы повышенная нагрузка на шину,связанная с наблюдением итрансляцией сообщений, не «съела» преимуществ локальных кэшей.
Рис. 11.8. Кэш-память с контроллером наблюдения за шиной
Ниже рассматриваются некоторые из наиболее распространенных протоколов наблюдения. Большинство из них описываются упрощенно, а их детальное изложение можно найти по ссылкам на литературные источники.
В большинстве протоколов стратегия обеспечения когерентности кэш-памяти расценивается каксмена состояний в конечном автомате. При таком подходепредполагается, что любой блок в локальной кэш-памяти может находиться в одном из фиксированных состояний. Обычно число таких состояний не превышает четырех, поэтому для каждой строки кэш-памяти в ее теге имеются два бита, называе-

Мультипроцессорная когерентность кэш-памяти 5 0 7
мыебитамисостояния (SB, Status Bit). Следуеттакжеучитывать, что некоторым идентичным по смыслу состояниям строки кэша разработчиками различных протоколов присвоены разные наименования. Например, состояние строки, в которой были произведены локальные изменения, в одних протоколах называют Dirty («грязный»), а в других — Modified («модифицированный» или «измененный»).
Протокол сквозной записи. Этот протокол представляет собой расширение стандартной процедуры сквозной записи, известной по однопроцессорным системам. В нем запись в локальную кэш-память любого процессора сопровождается записью в основную память. В дополнение, все остальные кэши, содержащие копиюизмененного блока,должны объявить свою копию недействительной. Протокол считается наиболее простым, но при большом числе процессоров приводит к значительному трафику шины, поскольку требует повторной перезагрузки измененного блока в те кэши, где этот блок ранее был объявлен недействительным [211]. Кроме того, производительность процессоров при записи в совместно используемые переменные может упасть из-за того, что для продолжения вычислений процессоры должны ожидать, пока завершатся все операции записи [141].
Протокол обратной записи. В основе протокола лежит стандартная схема обратной записи, за исключением того, что расширено условие перезаписи блока в основную память. Так, если копия блока данных в одном из локальных кэшей подверглась модификации, этот блок будет переписан в основную память при выполнении одного из двух условий:
-блок удаляется из той кэш-памяти, где он был изменен;
-другой процессор обратился к своей копии измененного блока.
Если содержимое строки в локальном кэше не модифицировалось, перезапись в основную память не производится. Доказано, что такой протокол по эффективности превосходит схему сквозной записи, поскольку необходимо переписывать только измененные блоки [211].
Несмотря на более высокую производительность, протокол обратной записи также не идеален, так как решает проблему когерентности лишь частично. Когда процессор обновляет информацию в своей кэш-памяти, внесенные изменения не наблюдаемы со стороны других процессоров до момента перезаписи измененного блока в основную память, то есть другие процессоры не знают, что содержимое по данному адресу было изменено, до тех пор пока соответствующая строка не будет переписана в основную память. Эта проблема часто решается путем наложения условия, что кэши, которые собираются изменить содержимое совместно используемого блока, должны получить эксклюзивные права на этот блок, как это делается в рассматриваемом позже протоколе Berkeley [141].
В работе [110] приводятся результаты сравнения среднего трафика шины для протоколовобратнойисквознойзаписи.Обнаружено,чтокогдакоэффициенткэшпопаданий приближается к 100%, протокол обратной записи вообще не требует трафика шины, так как все необходимые строки находятся в кэш-памяти. В свою очередь, протоколусквознойзаписи необходим,покрайнеймере,один цикл шины на каждую операцию чтения, поскольку предыдущая операция записи могла аннулировать копию данных в локальном кэше. В работе также доказано, что применение протокола обратной записи взамен протокола сквозной записи способно

5 0 8 Глава 11. Организация памяти вычислительных систем
снизить трафик шины на 50%, однако обратная запись по сравнению со сквозной влечет более серьезные проблемы когерентности. Это связано с тем, что даже основная память не всегда содержит последнее значение элемента данных.
Протокол однократной записи. Протокол однократной записи (write-once), предложенный Гудменом.[110], — первый из упоминающихся в публикациях протоколов обеспечения когерентности кэш-памяти. Он относится к схемам на основе наблюдения, действующим на принципе записи с аннулированием. Протокол предполагает, что первая запись в любую строку кэш-памяти производится по схеме сквозной записи, при этом контроллеры других кэшей объявляют свои копии измененного блока недействительными. С этого момента только процессор, произведший запись, обладает достоверной копией данных [141]. Последующие операции записи в рассматриваемую строку выполняются в соответствии с протоколом обратной записи [51].
Основной недостаток протокола в том, что он требует первоначальной записи в основную память, даже если эта строка не используется другими процессорами.
Диаграмма состояний протокола показана на рис. 11.9.
Рис. 11.9. Протокол однократной записи
Для реализации протокола однократной записи каждой строке кэш-памяти приданы два бита. Это позволяет представить четыре состояния, в которых может находиться строка: «недействительная» (I, Invalid), «достоверная» (V, Valid), «резервированная» (R, Reserved) и «измененная» (D, Dirty). В состоянии I строка кэшпамяти не содержит достоверных данных. В состоянии V строка кэша содержит данные, считанные из основной памяти и к данному моменту еще не измененные, то есть строка кэша и блок основной памяти согласованы. Состояние R означает, что с момента считывания из основной памяти в блоке локальной кэш-памяти было

Мультипроцессорная когерентность кэш-памяти 5 0 9
произведено только одно изменение, причем оно учтено и в основной памяти. В состоянии R содержимое строки кэша и основной памяти также является согласованным. Наконец, статус D показывает, что строка кэш-памяти модифицировалась более чем один раз и последние изменения еще не переписаны в основную намять.
Вэтом случае строка кэша и содержимое основной памяти не согласованы.
Впроцессе выполнения программ блоки слежения за шиной каждой кэш-па- мяти проверяют, не совпадает ли адрес ячейки, изменяемой в какой-либо локальной кэш-памяти, с одним из адресов в собственном кэше. Если такое совпадение произошло при выполнении операции записи, контроллер кэша изменяет статус соответствующей строки в своей кэш-памяти на I. Если совпадение обнаружено при выполнении операции чтения, состояние строки не изменяется, за исключением случая, когдастрока, проверяемая на совпадение, помечена как R или D. Если строка имеет состояние R, оно изменяется на V. Когда строка кэша отмечена как измененная (D), локальная система запрещает считывание элемента данных из основной памяти и данные берутся непосредственно из локальной кэш-памяти, как из источника наиболее «свежей» информации. Во время того же доступа к шипе или непосредственно после него обновленное значение должно быть переписано
восновную память, а состояние строки скорректировано на V.
Впротоколе однократной записи когерентность сохраняется благодаря тому, что когда выполняется запись, копии изменяемой строки во всех остальных локальных кэшах объявляются недействительными. Таким образом, кэш, выполняющий операцию записи, становится обладателем единственной достоверной копии (при первой записи в строку такая же копия будет и в основной памяти) [ 110]. При первой записи строка переводится в состояние R, и если впоследствии такая строка удаляется из кэш-памяти, ее перезапись в основную память не требуется. При последующих изменениях строки она помечается как D и работает протокол обратной записи.
Вранее упоминавшейся работе [110] приводятся результаты сравнения протоколов сквозной и обратной записи также и с протоколом однократной записи. Согласно Гудмену, мультипроцессорная система, состоящая из трех компьютеров PDP-11, каждый из которых имеет множественно-ассоциативную четырехканальную кэш-память емкостью 2048 байт при длине строки в 32 байта, показывает следующие показатели трафика шины: 30,76%, 17,55% и 17,38% для протоколов сквозной, обратной и однократной записи соответственно. Таким образом, показатели протокола однократной записи по сравнению с протоколами сквозной и обратной записи несколько лучше.
Протокол Synapse. Данный протокол, реализованный в отказоустойчивой мультипроцессорной системе Synapse N + 1, представляет собой версию протокола однократной записи, где вместо статуса R используется статус D. Кроме того, переход . из состояния 0 в состояние V при промахе, возникшем в ходе чтения данных другим процессором, заменен достаточно громоздкой последовательностью. Связано это с тем, что при первом кэш-промахе чтения запросивший процессор не может получить достоверную копию непосредственно из той локальной кэш-памяти, где произошло изменение данных, и вынужден обратиться напрямую к основной памяти[51,138].

5 1 0 Глава 11. Организация памяти вычислительных систем
Протокол Berkeley. Протокол Berkeley [141] был применен в мультипроцессорной системе Berkeley, построенной на базе RISC-процессоров.
Снижение издержек, возникающих в результате кэш-промахов, обеспечивается благодаря реализованной в этом протоколе идее прав владения на строку кэша. Обычно владельцем прав на все блоки данных считается основная память. Прежде чем модифицировать содержимое строки в своей кэш-памяти, процессор должен получить права владения на данную строку. Эти права приобретаются с помощью специальных операций чтения и записи. Если при доступе к блоку, собственником которого в данный момент не является основная память, происходит кэш-про- мах, процессор, являющийся владельцем строки, предотвращает чтение из основной памяти и сам снабжает запросивший процессор данными из своей локальной кэш-памяти.
Другое улучшение — введение состояния совместного использования (shared). Когда процессор производит запись в одну из строк своей локальной кэш-памяти, он обычно формирует сигнал аннулирования копий изменяемого блока в других кэшах. В протоколе Berkeley сигнал аннулирования формируется только при условии, что в прочих кэшах имеются такие копии. Это позволяет существенно снизить непроизводительный трафик шины. Возможны следующие сценарии.
Прежде всего, каждый раз, когда какой-либо процессор производит запись в свою кэш-память, изменяемая строка переводится в состояние «измененная, частная» (PD, Private Dirty). Далее, если строка является совместно используемой, на шину посылается сигнал аннулирования, и во всех локальных кэшах, где есть копия данного блока данных, эти копии переводятся в состояние «недействительная» (I, Invalid). Если при записи имел место промах, процессор получает копию блока из кэша текущего хозяина запрошенного блока. Лишь после этих действий процессор производит запись в свой кэш.
При кэш-промахе чтения процессор посылает запрос владельцу блока, с тем чтобы получить наиболее свежую версию последнего, и переводит свою новую копию в состояние «только для чтения» (R0, Read Only). Если владельцем строки был другой процессор, он помечает свою копию блока как «разделяемую измененную» (SD, Shared Dirty).
Диаграмма состояний протокола Berkeley показана на рис. 11.10.
Сравнивая протоколы однократной записи и Berkeley, можно отметить следующее. Оба протокола используют стратегию обратной записи, при которой измененные блоки удерживаются в кэш-памяти как можно дольше. Основная память обновляется только при .удалении строки из кэша. Верхняя граница общего количества транзакций записи на шине определяется той частью протокола однократной записи, где реализуется сквозная запись, так как последняя стратегия порождает на шине операцию записи при каждом изменении, инициированном процессором [141]. Поскольку первая операция записи в протоколе однократной записи является сквозной, она производится даже если данные не являются совместно используемыми. Это влечет дополнительный трафик шины, который возрастает с увеличением емкости кэш-памяти. Доказано, что протокол однократной записи приводит к большему трафику шины по сравнению с протоколом Berkeley [141].

Мультипроцессорная когерентностькэш-памяти 5 1 1
Рис.11.10.ПротоколBerkeley
Для постоянно читаемой и обновляемой строки в протоколе однократной записи необходимы считываниеэтой строки в кэш, еелокальная модификация в кэше и обратная запись в память. Вся процедуратребуетдвух операций на шине: чтения из основной памяти (ОП) и обратной записи в ОП. С другой стороны, протокол Berkeley исходит из получения прав на строку. Далее блок модифицируется в кэше. Если до удаления из кэша к строке не производилось обращение, число циклов шины будет таким же, как и в протоколе однократной записи. Однако более вероятно, что строка будет запрошена опять, тогда с позиций одиночной кэш-памяти обновление строки кэша нуждается только в одной операции чтения на шине. Таким образом, протокол Berkeley пересылает строки непосредственно между кэшами, в то время как протокол однократной записи передает блок из исходного кэша в основную память, а затем из ОП в запросившие кэши, что имеет следствием общую задержку системы памяти [141],
Протокол Illinois. Протокол Illinois, предложенный Марком Папамаркосом [175], также направлен на снижение трафика шины и, соответственно, времени ожидания процессором доступа к шине. Здесь, как и в протоколе Berkeley, главенствует идея прав владения блоком, но несколько измененная. В протоколе Illinois правом владения обладает любой кэш, где есть достоверная копия блока данных. В этом случае у одного и того же блока может быть несколько владельцев. Когда такое происходит, каждому процессору назначается определенный приоритет и источником информации становится владелец с более высоким приоритетом.
Как и в предыдущем случае, сигнал аннулирования формируется, лишь когда копии данного блока имеются и в других кэшах. Возможные сценарии для протокола Illinois представлены на рис. 11.11,
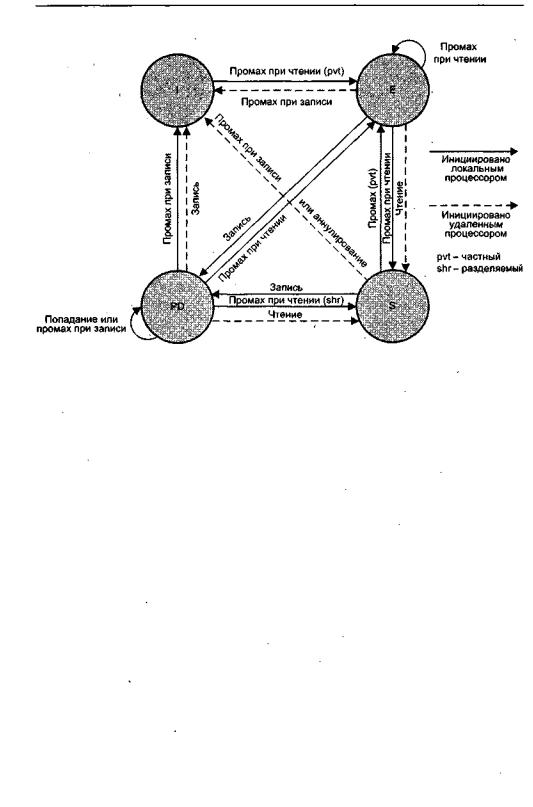
5 1 2 Глава 11. Организация памяти вычислительных систем
Рис. 11 . 11 . Протокол Illinois
Каждый раз когда какой-либо процессор производит запись в свою кэш-память, изменяемая строка переводится в состояние «измененная частная» (PD, Private Dirty). Если блок данных является совместно используемым, на шину посылается сигнал аннулирования и во всех локальных кэшах, где есть копия данного блока, эти копии переводятся в состояние «недействительная» (I, Invalid). Если при записи случился промах, процессор получает копию из кэша текущего владельца запрошенного блока. Лишь после означенных действий процессор производит запись в свой кэш. Как видно, в этой части имеет место полное совпадение с протоколом Berkeley,
При кэш-промахе чтения процессор посылает запрос владельцу блока, с тем чтобы получить наиболее свежую версию последнего, и переводит свою новую копию в состояние «эксклюзивная»- (Е, Exclusive) при условии, что он является единственным владельцем строки. Б противном случае статус меняется на «разделяемая» (S, Shared).
Существенно, что протокол расширяем и тесно привязан как к коэффициенту кэш-промахов, так и к объему данных, которые являются общим достоянием мультипроцессорной системы.
Протокол Firefly. Протокол был предложен Такером и др. [211] и реализован
вмультипроцессорной системе Firefly Multiprocessor Workstation, разработанной
висследовательском центре Digital Equipment Corporation.
Впротоколе Firefly используется запись с обновлением. Возможные состояния строки кэша совпадают с состояниями протокола Illinois (рис. 11,12). Отличие состоит в том, что стратегия обратной записи применяется только к тем строкам, которые находятся в состоянии PD илиЕ,в то время как применительно к строкам


5 1 4 Глава 11. Организация памяти вычислительных систем
В протоколе реализована процедура записи с обновлением. Строка кэша может иметь одно из пяти состояний [162,212]:
-Invalid (I) — копия, хранящаяся в кэше, недействительна;
-ReadPrivate (RP) — существует лишь одна копия блока, и она совпадает с содержимым основной памяти;
-Private Dirty (PD) — существует лишь одна копия блока, и она не совпадает с содержимым основной памяти;
-Shared Clean (SC) — имеется несколько копий блока, и все они идентичны содержимому основной памяти;
-Shared Dirty (SO) — имеется несколько копий блока, не совпадающих с содержимым основной памяти.
Дополнительное состояние SO предназначено для предотвращения записи в основную память. Диаграмма состояний для данного протокола приведена на рис. 11.13.
Рис. 11.13. Протокол Dragon
Протокол MESI. Безусловно, среди известных протоколов наблюдения самым популярным является протокол MESI (Modified/Exclusive/Shared/Invalid). Протокол MESI широко распространен в коммерческих микропроцессорных системах, например на базе микропроцессоров Pentium и PowerPC. Так, его можно обнаружить во внутреннем кэше и контроллере внешнего кэша i82490 микропроцессора Pentium, в процессоре i860 и контроллере кэш-памяти МС88200 фирмы Motorola,
Протокол был разработан для кэш-памяти с обратной записью. Одной из основных задач протокола MESI является откладывание на максимально возмож-