

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfМатричные вычислительные системы 5 6 5
Интерфейсная ВМ
Интерфейсная ВМ (ИВМ) соединяет матричную SIMD-систему с внешним миром, используя для этого какой-либо из сетевых интерфейсов, например Ethernet, как это имеет место в системе MasPar MP-1. Интерфейсная ВМ работает под управлением операционной системы, чаще всего ОС UNIX. На ИВМ пользователи подготавливают, компилируют и отлаживают свои программы. В процессе выполнения программы сначалазагружаются из интерфейсной ВМ в контроллер управления массивом процессоров, который выполняет программу и распределяет команды и данные по процессорным элементам массива. В некоторых ВС, например в Massively Parallel Computer MPP, при создании, компиляции и отладке программ КМП и интерфейсная ВМ используются совместно.
На роль ИВМ подходят различные вычислительные машины. Так, в системе СМ-2 в этом качестве выступает рабочая станция SUN-4, в системе MasPar — DECstation 3000, а в системе МРР - DEC VAX-11/780.
Контроллер массива процессоров
Контроллер массива процессоров выполняет последовательный программный код, реализует команды ветвления программы, транслирует команды и сигналы управления в процессорные элементы. Рисунок 13.11 иллюстрирует одну из возможных реализаций КМП, в частности принятую в устройстве управления системы PASM.
Рис. 13.11. Модель контроллера массива процессоров [225]
При загрузке из ИВМ программа через интерфейс ввода/вывода заносится в оперативное запоминающее устройство КМП (ОЗУ КМП). Команды для процессорныхэлементов и глобальная маска, формируемая наэтапе компиляции,также через интерфейс ввода/вывода загружаются в ОЗУ команд и глобальной маски

5 6 6 Глава 13. Вычислительные системы класса SIMD
(ОЗУ КГМ). Затем КМП начинает выполнять программу, извлекая либо однускалярную команду из ОЗУ КМП, либо множественные команды из ОЗУ КГМ. Скалярныекоманды —команды,осуществляющиеоперациинадхранящимисяв КМП скалярнымиданными, выполняются центральным процессором (ЦП) контроллера массива процессоров. В свою очередь, команды, оперирующие параллельными переменными, хранящимися в каждом ПЭ, преобразуются в блоке выборки команд в более простые единицы выполнения — нанокоманды. Нанокоманды совместно с маской пересылаются через шину команд для ПЭ на исполнение в массив процессоров. Например, команда сложения 32-разрядных слов в КМП системы МРР преобразуется в 32 нанокоманды одноразрядного сложения, которые каждым ПЭ обрабатываются последовательно,
В большинстве алгоритмов дальнейший порядок вычислений зависит от результатов и/или флагов условий предшествующих операций. Для обеспечения такого режима в матричных системах статусная информация, хранящаяся в процессорных элементах, должна быть собрана в единое слово и передана в КМП для выработки решения о ветвлении программы. Например, в предложении IFALL(условиеA)THEN DO ВоператорВбудетвыполнен,еслиусловиеАсправедливо во всех ПЭ. Для корректного включения/отключения процессорных элементов КМП должен знать результат проверки условия А во всех ПЭ. Такая информация передается в КМП по однонаправленной шине результата. В системе СМ-2 эта шина названа GLOBAL. В системе МРР для той же цели организована структура, называемая деревом SUM-OR. Каждый ПЭ помещает содержимое своего одноразрядного регистра признака на входы дерева, которое с помощью операции логического сложения комбинирует эту информацию и формирует слово результата, используемое в КМП для принятия решения.
Массив процессоров
В матричных SIMD-системах распространение получили два основных типа архитектурной организации массива процессорных элементов (рис. 13.12).
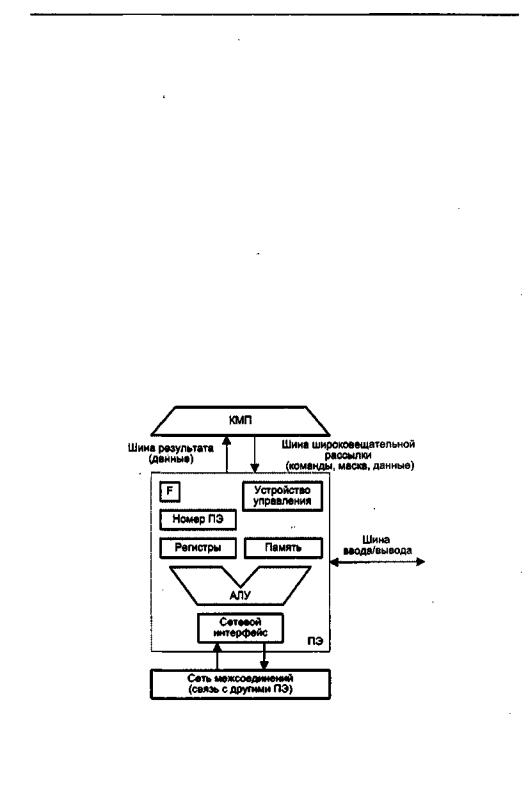
В первом варианте, известном как архитектура типа «процессорный элементпроцессорный элемент» («ПЭ-ПЭ»), N процессорных элементов (ПЭ) связаны между собой сетью соединений (рис, 13.12, а). Каждый ПЭ — это процессор с локальной памятью. Процессорные элементы выполняют команды, получаемые из КМП по шине широковещательной рассылки, и обрабатываютданные как хранящиеся в их локальной памяти, так и поступающие из КМП, Обмен данными между процессорными элементами производится по сети соединений, в то время как шина ввода/вывода служит для обмена информацией между ПЭ и устройствами ввода/вывода. Для трансляции результатов из отдельных ПЭ в контроллер массива процессоров служит шина результата. Благодаря использованию локальной памяти аппаратные средства ВС рассматриваемого типа могут быть построены весьма эффективно. Во многих алгоритмах действия по пересылке информации по большей части локальны, то есть происходят между ближайшими соседями. По этой причине архитектура, где каждый ПЭ связан только ссоседними,очень популярна. В качестве примеров вычислительных систем с рассматриваемой архитектурой можно упомянуть MasPar MP-1, Connection Machine CM-2, GF11, DAP, МРР, STARAN, PEPE, ILLIAC IV.


Матричные вычислительные системы 5 6 9
ной памяти. ПЭ могут также обрабатывать те данные, которые поступают по шине широковещательной рассылки из КМП. Кроме того, каждый процессорный элемент вправе получать данные из других ПЭ и отправлять их в другие ПЭ по сети соединений, используя для этого свой сетевой интерфейс. В некоторых матричных системах, в частности в MasPar МР-1, элемент данных из ПЭ-источника можно передавать в ПЭ-приемник непосредственно, в то время как в других, например в МРР, —данные предварительнодолжны бытьпомещены в специальный регистр пересылки данных, входящий в состав сетевого интерфейса. Пересылка данных между ПЭ и устройствами ввода/вывода осуществляется через шину ввода/вывода ВС. В ряде систем (MasPar MP-1) ПЭ подключены к шине ввода/вывода посредством сети соединений и канала ввода/вывода системы. Результаты вычислений любое ПЭ выдает в КМП через шину результата.
Каждому из N ПЭ в массиве процессоров присваивается уникальный номер, называемый также адресом ПЭ, который представляет собой целое число от 0 до N- 1. Чтобы указать, должен ли данный ПЭ участвовать в общей операции, него составе имеется регистр флага разрешения F. Состояние этого регистра определяютсигналы управления из КМП,либо результаты операций всамом ПЭ,либо ите и другие совместно.
Еще одной существенной характеристикой матричной системы является способ синхронизации работы ПЭ. Так как все ПЭ получают и выполняют команды одновременно, их работа жестко синхронизируется. Это особенно важно в операциях пересылки информации между ПЭ. В системах, где обмен производится с четырьмя соседними ПЭ, передача информации осуществляется в режиме «регистррегистр».
Подключение и отключение процессорных элементов
В процессе вычислений в ряде операций должны участвовать только определенные ПЭ, в то время как остальные ПЭ остаются бездействующими. Разрешение и запрет работы ПЭ могут исходить от контроллера массива процессоров (глобальное маскирование) и реализуются с помощью схем маскирования ПЭ. В этом случае решение о необходимости маскирования принимается на этапе компиляции кода. Решение о маскировании может также приниматься во время выполнения программы (маскирование, определяемое данными), при этом опираются на хранящийся в ПЭ флагразрешения маскирования F.
Примаскировании,определяемомданными,каждыйПЭсамостоятельнообъявляет свой статус «подключен/не подключен». В составе системы команд имеются наборы маскируемых и немаскируемых команд. Маскируемые команды выполняются в зависимости от состояния флага F, в то время как немаскируемые флаг просто игнорируют. Процедуру маскирования рассмотрим на примере предложения IF-THEN-ELSE, Пусть х — локальная переменная (хранящаяся в локальной памяти каждого ПЭ). Предположим, что процессорные элементы массива параллельно выполняют,ветвление:
и каждый ПЭ оценивает условие IF. Те ПЭ, для которых условие х > О справедливо, установят свой флаг Fв единицу,тогдакакостальные ПЭ — в ноль. Далее КМП

5 7 0 Глава 13. Вычислительные системы класса SIMD
распределяетоператорАпо всем ПЭ. Команды, реализующиеэтотоператор,должны быть маскируемыми. Оператор А будет выполнен только теми ПЭ, где флаг F установлен в единицу. Далее КМП передает во все ПЭ немаскируемую команду ELSE,котораязаставитвсеПЭинвертироватьсостояниесвоегофлага F.Затем КМП транслирует во все ПЭ оператор В, который также должен состоять из маскируемых команд. Оператор будет выполнен теми ПЭ, где флаг F после инвертирования был установлен в единицу, то есть где результат проверки условия х > О был отрицательным.
При использовании схемы глобального маскирования контроллер массивапроцессоров вместе с командами посылает во все ПЭ глобальную маску. Каждый ПЭ декодирует эту маску и по результату выясняет, должен ли он выполнять данную команду или нет.
В зависимости от способа кодирования маски существует несколько различных схем глобального маскирования. В схеме, примененной в вычислительной системе ILLIAC IV с 64 64-разрядными ПЭ, маска представляет собой N-разряд- ный вектор. Каждый бит вектора отражает состояние одного ПЭ. Если бит содержит единицу, соответствующий ПЭ будет активным, в противном случае — пассивным. Несмотря на свою универсальность, при больших значениях N схема становится неудобной. В варианте маскирования с адресом ПЭ используется 2т- разрядная маска (т = log2N), в которой каждая позиция соответствует одному разряду в двоичном представлении адреса ПЭ. Каждая позиция может содержать 0, i или X. Таким образом, маска состоит из 2т битов. Если для всех i (0 <=i< т) i-я позиция в маске и i-я позиция в адресе ПЭ совпадают или в i-й позиции маски стоит X, ПЭ будет активным. Например, маска 000Х1 представляет процессорные элементы с номерами 1 и 3, в то время как маска ХХХХО представляет все ПЭ с четными номерами (все это для массива из 32 ПЭ). Здесь можно активизировать только подмножество из всех возможных комбинаций процессорных элементов массива, что на практике не является ограничением, так как в реальных алгоритмах обычно участвуют не произвольные ПЭ, а лишь расположенные регулярным образом.
Глобальные и локальные схемы маскирования могут комбинироваться. В таком случае активность ПЭ в равной мере определяется как флагом F, так и глобальной маской.
Сети взаимосвязей процессорных элементов
Эффективность сетей взаимосвязей процессорных элементов во многом определяет возможную производительность всей матричной системы. Применение находят самые разнообразные топологии сетей.
Поскольку процессорные элементы в матричных системах функционируют синхронно, обмениваться информацией они также должны по согласованной схеме, причем необходимо обеспечить возможность синхронной передачи от нескольких ПЭ-источников к одному ПЭ-приемнику. Когда для передачи информации в сетевом интерфейсе задействуется только один регистр пересылки данных, это может привести к потере данных, поэтому в ряде ВС для предотвращения подобной ситуации предусмотрены специальные механизмы. Так, в системе СМ-2 используется оборудование, объединяющее сообщения, поступившие к одному ПЭ.

Ассоциативные вычислительные системы 5 7 1
Объединение реализуется за счет операций арифметического и логического сложения, наложения записей, нахождения меньшего и большего из двух значений. В некоторых SIMD-системах, например МР-1, имеется возможность записать одновременно пришедшие сообщения в разные ячейки локальной памяти.
Хотя пересылки данных по сети инициируются только активными ПЭ, пассивные процессорные элементы также вносят вклад в эти операции. Если активный ПЭ инициирует чтение издругого ПЭ, операция выполняется вне зависимости от статуса ПЭ, из которого считывается информация. То же самое происходит и при записи.
Наиболее распространенными топологиями в матричных системах являются решетчатые и гиперкубические. Так, в ILLIAC IV, МРР и СМ-2 каждый ПЭ соединен с четырьмя соседними. В МР-1 и МР-2 каждый ПЭ связан с восьмью смежными ПЭ. В ряде систем реализуются многоступенчатые динамические сети соединений (МР-1, МР-2, GF11).
Ввод/вывод
Хотя программа вычислений хранится в памяти интерфейсной ВМ или иногда в КМП, входные и выходные данные процессорных элементов и КМП могут храниться также на внешних ЗУ. Такие ЗУ могут подключаться к массиву процессоров и/или КМП посредством каналов ввода/вывода или процессоров ввода/вывода.
Ассоциативные вычислительные системы
К классу SIMD относятся и так называемые ассоциативные вычислительные системы. В основе подобной ВС лежит ассоциативное запоминающее устройство (см.главу5),аточнее—ассоциативныйпроцессор,построенныйнабазетакогоЗУ. Напомним, что ассоциативная память (или ассоциативная матрица) представляет собой ЗУ, где выборка информации осуществляется не по адресу операнда, а по отличительным признакам операнда. Запись в традиционное ассоциативное ЗУ также производится не по адресу, а в одну из незанятых ячеек.
Ассоциативныйпроцессор(АП)можноопределитькакассоциативнуюпамять, допускающую параллельную запись во все ячейки, для которых было зафиксировано совпадение с ассоциативным признаком. Эта особенность АП, носящая название мулътизаписи, является первым отличием ассоциативного процессора от традиционной ассоциативной памяти. Считывание и запись информации могут производиться по двум срезам запоминающего массива — либо это все разряды одного слова, либо один и тот же разряд всех слов. При необходимости выделения отдельных разрядов среза лишние позиции допустимо маскировать. Каждый разряд среза в АП снабжен собственным процессорным элементом, что позволяет между считыванием информации и ее записью производить необходимую обработку, то есть параллельно выполнять операции арифметического сложения, поиска, а также эмулировать многие черты матричных ВС, таких, например, как ILLIAC IV.
Такимобразом,ассоциативныеВСилиВСсассоциативным процессором есть не что иное, как одна из разновидностей параллельных ВС, в которых п процес-
5 7 2 Глава 13. Вычислительные системы класса SIMD
сорных элементов ПЭ (вертикальный разрядный срез памяти) представляют собой простые устройства, как правило, последовательной поразрядной обработки. При этом каждое слово (ячейка) ассоциативной памяти имеет свое собственное устройство обработки данных (сумматор). Операция осуществляется одновременно всеми п ПЭ. Все или часть элементарных последовательных ПЭ могут синхронно выполнять операции над всеми ячейками или над выбранным множеством слов ассоциативной памяти.
Время обработки Nm-разрядных слов в ассоциативной ВС определяется выражением:
где t — время цикла ассоциативной памяти; п — число ячеек ассоциативной системы; К — коэффициент сложности выполнения элементарной операции (количество последовательных шагов, каждый из которых связан с доступом к памяти).
Вычислительные системы с систолической структурой
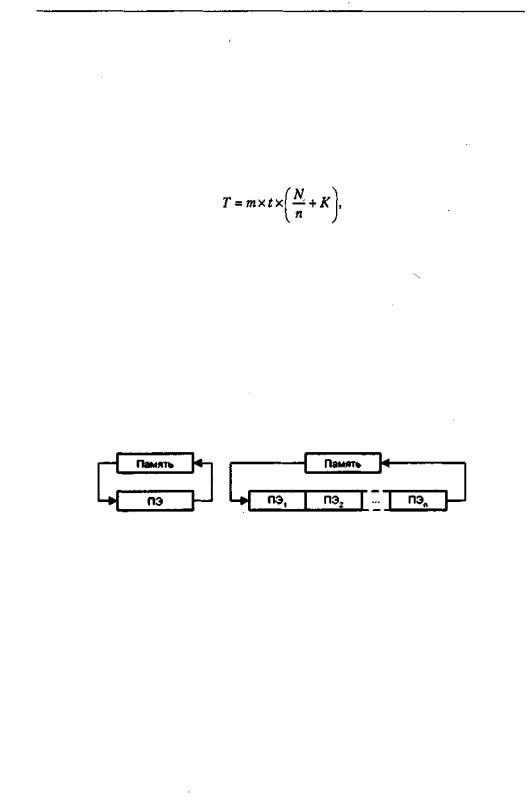
В фон-неймановских машинах данные, считанные из памяти, однократно обрабатываются в процессорном элементе, после чего снова возвращаются в память (рис. 13.14 а). Авторы идеи систолической матрицы Кунг и Лейзерсон предложили организовать вычисления так, чтобы данные на своем пути от считывания из памяти до возвращения обратно пропускались через как можно большее число ПЭ (рис. 13.14,6).
а |
6 |
Рис. 13.14. Обработка данных в ВС: а — фон-неймановского типа; б — систолической структуры
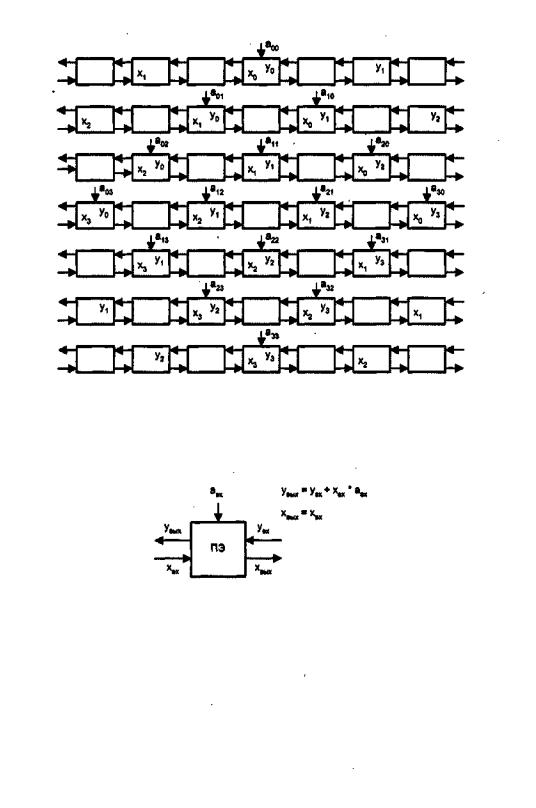
Если сравнить положение памяти в ВС со структурой живого организма, то по аналогии ей можно отвести роль сердца, множеству ПЭ — роль тканей, а поток данных рассматривать как циркулирующую кровь. Отсюда и происходит название систолическаяматрица (систола — сокращение предсердий и желудочков сердца при котором кровь нагнетается в артерии). Систолические структуры эффективны при выполнении матричных вычислений, обработке сигналов, сортировке данных и т. д. В качестве примера авторами идеи был предложен линейный массив для алгоритма матричного умножения, показанный на рис. 13.15.
В основе схемы лежит ритмическое прохождение двух потоков данных xi и уi, навстречу друг другу. Последовательные элементы каждого потока разделены одним тактовым периодом, чтобы любой из них мог встретиться с любым элементом встречного потока. Если бы они следовали в каждом периоде, то элемент xi никогда
Вычислительныесистемы с систолическойструктурой 5 7 3
Рис. 13.15. Процесс векторного умножения матриц (n = 4)
бы не встретился с элементамиy yi+l, yi+3... Вычисления выполняются параллельно в процессорных элементах, каждый из которых реализует один шаг в операции вычисления скалярного произведения (IPS, Inner Product Step) и носит название
IPS-элемента(рис.13.16).
Рис. 13.16. Функциональная схема IPS-элемента
Значение унх, поступающее на вход ПЭ, суммируется с произведением входных
значений хвх и aвх. Результат выходит из ПЭ как уВЪ1Х. Значение хвх, кроме того, для возможного последующего использования остальной частью массива транслиру-
ется через ПЭ без изменений и покидает его в виде хвых.
Таким образом, систолическая структура — это однородная вычислительная среда из процессорных элементов, совмещающая в себе свойства конвейерной и матричной обработки и обладающая следующими особенностями:
-вычислительный процесс в систолических структурах представляет собой непрерывную и регулярную передачу данных от одного ПЭ к другому без запоминания промежуточных результатов вычисления;

5 7 4 Глава 13. Вычислительные системы класса SIMD
-каждый элемент входных данных выбирается из памяти однократно и используется столько раз, сколько необходимо по алгоритму, ввод данных осуществляется в крайние ПЭ матрицы;
-образующие систолическую структуру ПЭ однотипны и каждый из них может быть менее универсальным,чем процессоры обычных многопроцессорных систем;
-потоки данных и управляющих сигналов обладают регулярностью, что позволяет объединять ПЭ локальными связями минимальной длины;
-алгоритмы функционирования позволяют совместить параллелизм с конвейерной обработкой данных;
-производительность матрицы можно улучшить за счет добавления в нее определенногочислаПЭ,причемкоэффициентповышенияпроизводительностипри этом линеен.
Внастоящее время достигнута производительность систолических процессоров порядка 1000 млрд операций/с.
Классификация систолических структур
Анализ различных типов систолических структур и тенденций их развития позволяет классифицировать эти структуры по нескольким признакам.
По степени гибкости систолические структуры могут быть сгруппированы на:
-специализированные;
-алгоритмически ориентированные;
-программируемые.
Специализированныеструктуры ориентированы на выполнение определенного алгоритма. Эта ориентация отражается не только в конкретной геометрии систолической структуры, статичности связей между ПЭ и числе ПЭ, но и в выборе типа операции, выполняемой всеми ПЭ. Примерами являются структуры, ориентированные на рекурсивную фильтрацию, быстрое преобразование Фурье для заданного количества точек, конкретные матричные преобразования.
Алгоритмически ориентированные структуры обладают возможностью программирования либо конфигурации связей в систолической матрице, либо самих ПЭ. Возможность программирования позволяет выполнять на таких структурах некоторое множество алгоритмов, сводимых к однотипным операциям над векторами, матрицами и другими числовыми множествами.
В программируемых систолических структурах имеется возможность программирования как самих ПЭ, так и конфигурации связей между ними. При этом ПЭ могут обладать локальной памятью программ, и хотя все они имеют одну и ту же организацию, в один и тот же момент времени допускается выполнение различных операций изнекоторогонабора. Команды илиуправляющиеслова, хранящиеся в памяти программ таких ПЭ, могут изменять и направление передачи операндов.
Поразрядностипроцессорныхэлементовсистолическиеструктурыделятсяна:
-одноразрядные;
-многоразрядные.