

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfВычислительные системы с управлением вычислениями от потокаданных 6 2 5
результата поступает на ключ, обеспечивающий либо ввод данных от внешнего источника, либо вывод на внешний объект (периферийное устройство). Учитывая, что токен результата должен быть передан на другую вершину потокового графа, он направляется в очередь токенов, а оттуда — в блок согласования токенов. Здесь производится поиск других токенов, необходимых для инициирования вершины (если для этого нужны два токена). Поиск ведется аппаратно, посредством сравнения пункта назначения и тега входного токена с аналогичными параметрами всех хранящихся в памяти токенов. Если совпадение произошло, из пары токенов формируется пакет, в противном случае входной токен запоминается в блоке согласования токенов до момента, когда поступит согласующийся с ним токен. Пары токенов и токены с одним операндом передаются в память программ, содержащую узловые команды, и формируется полный выполняемый пакет. Выполняемые пакеты по возможности направляются в свободный процессор в массиве из
15процессоров!
Вкачестве других примеров динамических потоковых вычислительных систем следует упомянуть: SIGMA-1 [ 123,124], PATTSY Processor Array Tagged-Token System [171], NTT's Dataflow Processor Array System [206], DDDP Distributed Data Driven Processor [143], SDFA Stateless Data-Flow Architecture [198].
Основное преимущество динамических потоковых систем — это более высокая производительность, достигаемая за счет допуска присутствия на дуге множества токенов. При этом, однако, основной проблемой становится эффективная реализация блока, который собираеттокены с совпадающим цветом (токены с одинаковыми тегами). В плане производительности этой цели наилучшим образом отвечает ассоциативная память. К сожалению, такое решение является слишком дорогостоящим, поскольку число токенов, ожидающих совпадения тегов, как правило, достаточно велико. По этой причине в большинстве вычислительных систем вместо ассоциативных запоминающих устройств (ЗУ) используются обычные адресные ЗУ. В частности, сравнение тегов в рассмотренной манчестерской системе производится с привлечением хэширования, что несколько снижает быстродействие.
В последнее время все более популярной становится другая организация динамической потоковой ВС,позволяющаяосвободиться отассоциативной памятии известная как архитектура с явно адресуемыми токенами.
Архитектура потоковых систем с явно адресуемыми токенами
Значительным шагом в архитектуре потоковых ВС стало изобретение механизма явной адресации токенов (explicit token-store), имеющего и другое название — непосредственное согласование (direct matching). В основе этого механизма лежит то, что все токены в одной и той же итерации цикла и в одном и том же вхождении в реентерабельную процедуру имеют идентичный тег (цвет). При инициализации очередной итерации цикла или очередном обращении к процедуре формируется так называемый кадр токенов, содержащий токены, относящиеся к данной итерации или данному обращению, то есть с одинаковыми тегами, Использование конкретных ячеек внутри кадра задается на этапе компиляции. Каждому кадру вы-
626 Глава 15. Потоковые и редукционные вычислительные системы
деляется отдельная область в специальной памяти кадров (frame memory), причем раздача памяти под каждый кадр происходит уже на этапе выполнения программы.
Б схеме с явной адресацией токенов любое вычисление полностью описывает-
ся указателем команды,(IP, Instruction Pointer) и указателем кадра (FP, Frame Pointer). Этот кортеж <FP, IP> входит в тег токена, а сам токен выглядит следую-
щимобразом:Значение•FP.IP.
Команды, реализующие потоковый граф, хранятся в памяти команд и имеют формат: Кодоперации • Индекс в памяти кадров • Адресат.
Здесь ««Индекс в памяти кадров» определяет положение ячейки с нужным то-
кеном внутри кадра, то есть какое число нужно добавить к FP, чтобы получить адрес интересующего токена. Поле -«Адресат» указывает на местоположение ко-
манды, которой должен быть передан результат обработки данного токена. Адрес в этом поле также задан в виде смещения — числа, которое следует прибавить к текущему значению IP, чтобы получить исполнительный адрес команды назначе- ния в памяти команд. Если потребителей токена несколько, в поле «Адресат» за-
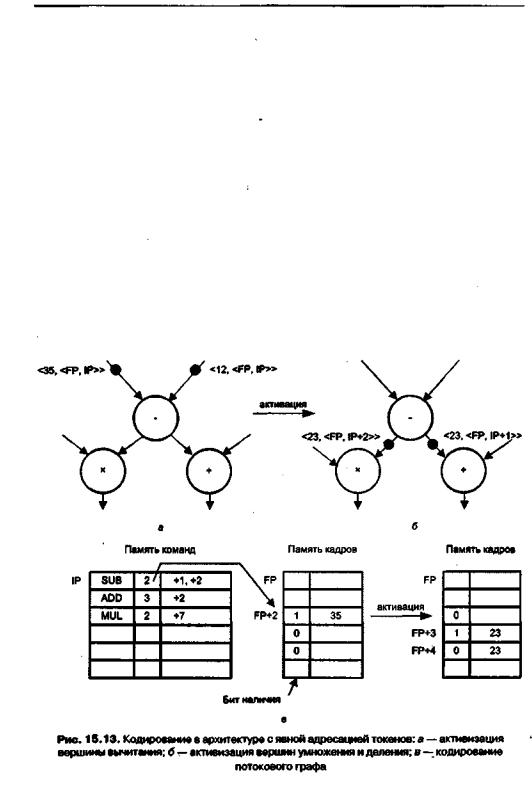
носится несколько значений смещения. Простой пример кодирования потокового графа и токенов на его дугах показан на рис. 15.13.
Каждому слову в памяти кадров придан бит наличия, единичное значение ко-
торого удостоверяет, что в ячейке находится токен, ждущий согласования, то есть что одно из искомых значений операндов уже имеется. Как и в архитектуре с окра-
Вычислительные системы с управлением вычислениями от потокаданных 6 2 7
шенными токенами, определено, что вершины могут иметь максимум две входные дуга. Когда на входную дугу вершины поступает токен <vl, <FP, IP», в ячейке памяти кадров с адресом FP + (IP.I) проверяется бит наличия (здесь IP.I означает содержимое поля I в команде, хранящейся по адресу, указанному в IP). Если бит наличия сброшен (ни один из пары токенов еще не поступал), поле значения пришедшего токена (vl) заносится в анализируемую ячейку памяти кадров, а бит наличия в этой ячейке устанавливается в единицу, фиксируя факт, что первый токен из пары уже доступен:
(FP + (IP.I).значение := vl (FP + (IP.I).наличие :=1
Этот случай отражен на рис. 15.13, а, когда на вершину SUB по левой входной дуге поступил токен <35, <FP, IP».
Если токен <v2,<FP,IP>>приходит на узел, для которого уже хранится значение vl, команда, представляющая данную вершину, может быть активирована и выполнена с операндами vl и v2. В этот момент значение vl извлекается из памяти кадров, бит наличия сбрасывается, и на функциональный блок, предназначенный для выполнения операции, передается пакет команды <vl, v2, FP, IP, IP.OP, IP.0>, содержащий операнды (vl и v2), код операции (IP.OP) и адресат ее результата (IP.D). Входящие в этот пакет значения FP и IP нужны, чтобы вместе с IP.D вычислить исполнительный адрес адресата. После выполнения операции функциональный
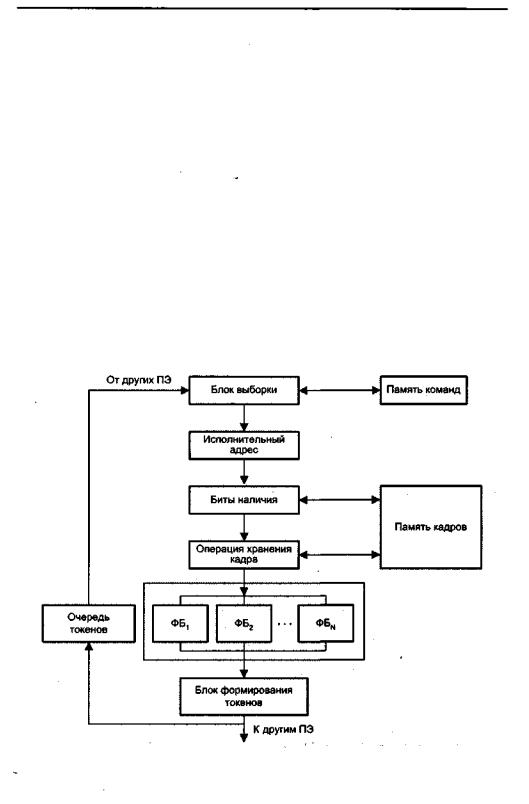
Рис. 15.14. Структура процессорного элемента типовой потоковой системы с явной адресацией токенов

6 2 8 Глава 15. Потоковые и редукционные вычислительныесистемы
блок пересылает результат вблокформирования токенов. Рисунок 15.13, бдемонстрирует ситуацию, когда токен уже пришел и на второй вход вершины SUB. Операция становится активируемой, и после ее выполнения результат передается на вершины ADD и MUL, которыеожидают входныхтокеноввячейкахFP+3 и FP+4 соответственно.
Типовая архитектура системы с явной адресацией токенов показана на рис. 15.14. Отметим, что функция согласования токенов стала достаточно короткой операцией, что позволяет внедрить ее в виде нескольких ступеней процессорного конвейера.
Макропотоковые вычислительные системы
Рассмотренный ранее механизм обработки с управлением от потокаданных функционируетнауровнекомандиегоотносяткпотоковой обработкенизкогоуровня (fine-grain dataflow). Данному подходу сопутствуют большие издержки при пересылке операндов. Для уменьшения коммуникационных издержек необходимо применять потоковую обработку на процедурном уровне, так называемую укрупненную потоковую или макропотоковую обработку (multithreading). Буквальный перевод английского термина означает потоковую обработку множества нитей.
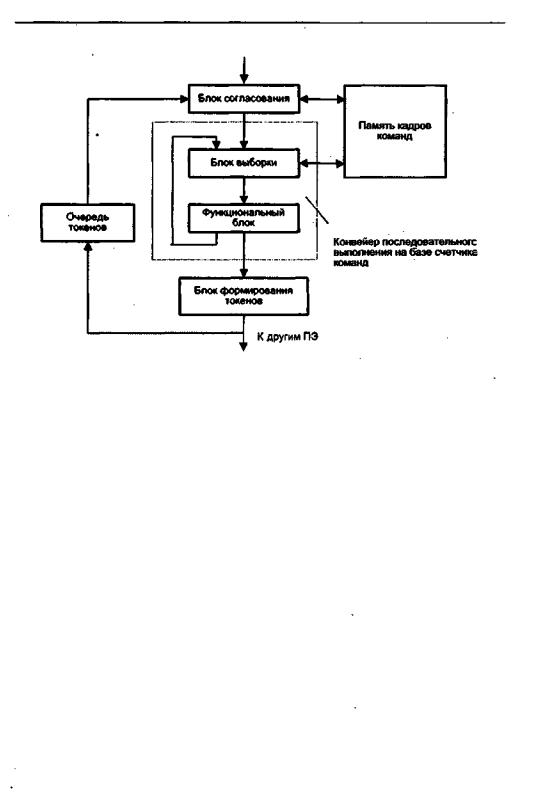
Макропотоковая модель совмещает локальность программы, характерную для фон-неймановской модели, с толерантностью к задержкам на переключение задач, свойственной потоковой архитектуре. Это достигается за счет того, что вершина графа представляет собой не одну команду, а последовательность из нескольких команд, называемых нитью (thread). По этой причине макропотоковуюорганизациючастоименуюткрупнозернистойпотоковойобработкой(coarsegrained dataflow). Макропотоковая обработка сводится к потоковому выполнению нитей, в то время как внутри отдельной нити характер выполнения фон-нейма- новский. Порядок обработки нитей меняется динамически в процессе вычислений, а последовательность команд в пределах нити определена при компиляции статически. Структура макропотоковой ВС представлена на рис. 15.15.
Существенное отличие макропотоковой системы от обычной потоковой ВС состоит в организации внутреннего управляющего конвейера, где последовательность выполнения команд задается счетчиком команд, как в фон-неймановских машинах. Иными словами, этот конвейер идентичен обычному конвейеру команд.
Вернемся к иллюстрации возможных вычислительных моделей (см. рис.15.1). В макропотоковой архитектуре (см. рис. 15.1, в) каждый узел графа представляет команду, а каждая закрашенная область — одну из нитей. Если команда приостанавливается, останавливается и соответствующая нить, в то время как выполнение других нитей может продолжаться.
Существуют две формы макропотоковой обработки: без блокирования и с блокированием, В модели без блокирования выполнение нити не может быть начато, покане получены все необходимые данные. Будучизапущенной, нить выполняется до конца без приостановки. В варианте с блокированием запуск нити может быть произведен до получения всех операндов. Когда требуется отсутствующий операнд, нить приостанавливается (блокируется), а возобновление выполнения откладывается на некоторое время. Процессор запоминает всю необходимую информацию о состоянии и загружает на выполнение другую готовую нить. Модель с блокированием обеспечивает более мягкий подход к формированию нитей (часто это выражается в возможности использования более длинных нитей) за счет дополнительной аппаратуры для хранения блокированных нитей.
Вычислительныесистемы с управлением вычислениями от потокаданных 6 2 9
Рис. 15.15. Структура процессорного элемента типовой макропотоковой системы
Возможна также и потоковая обработка переменного уровня, когда узлы соответствуют как простым операциям, так и сложным последовательным процедурам. Последний случай иногда называют комбинированной обработкой с потоками данных и потоками управления (combined dataflow/control flow).
Гиперпотоковая обработка
Восновегиперпотоковой технологии (hyperthreading), разработанной фирмойIntel и впервые реализованной в микропроцессоре Pentium 4, лежит то, что современные процессоры в большинстве своем являются суперскалярными и многоконвейерными, то есть выполнение команд в них идет параллельно, по этапам и на нескольких конвейерах сразу. Гиперпотоковая обработка призвана раскрыть этот потенциал таким образом, чтобы функциональные блоки процессора были бы максимально загружены. Поставленная цель достигается за счет сочетания соответствующих аппаратных и программных средств.
Выполняемая программа разбивается на два параллельных потока (threads). Задача компилятора (на стадии подготовки программы) и операционной системы (на этапе выполнения программы) заключается в формировании таких последовательностей независимых команд, которые процессор мог бы обрабатывать параллельно, по возможности заполняя функциональные блоки, не занятые одним из потоков, подходящими командами из другого, независимого потока.
Операционная система, поддерживающая гиперпотоковую технологию, воспринимает физический суперскалярный процессор как два логических процессора и организует поступление на эти два процессора двух независимых потоков команд.
Процессор с поддержкой технологии hyperthreading эмулирует работу двух одинаковых логических процессоров, принимая команды, направленные для каж-

6 3 0 Глава 15. Потоковые и редукционныевычислительныесистемы
дого из них. Это неозначает, что в процессореимеются два вычислительных ядра — оба логических процессора конкурируют за ресурсы единственного вычислительного ядра,' Следствием конкуренции является более эффективная загрузка всех ресурсов процессора,
В процессе вычислений физический процессор рассматривает оба потока команд и по очереди запускает на выполнение команды то из одного, то из другого, или сразу их двух, если есть свободные вычислительные ресурсы. Ни один из потоков не считается приоритетным. При остановке одного из потоков (в ожидании какого-либо события или в результате зацикливания) процессор полностью переключается на второй поток. Возможность чередования команд из разных потоков составляет принципиальное отличие между гиперпотоковой и макропотоковой обработкой.
Наличие только одного вычислительного ядра не позволяет достичь удвоенной производительности, однако за счет большей отдачи от всех внутренних ресурсов общая скорость вычислений существенно возрастает. Это особенно ощущается, когдапотоки содержат команды разных типов, тогда замедлениеобработки в одном из них компенсируется большим объемом работ, выполненных в другом потоке.
Следует учитывать, что эффективность технологии hyperthreading зависит от работы операционной системы, поскольку разделение команд на потоки осуществляет именно она.
Для иллюстрации рассмотрим некоторые особенности реализации гиперпотоковой технологии в процессоре Pentium 4 Хеоп. Процессор способен параллельно обрабатывать два потока в двух логических процессорах. Чтобы выглядеть для операционной системы и пользователякакдвалогическихпроцессора,физический процессор должен поддерживать информацию одновременно для двух отдельных и независимых потоков, распределяя между ними свои ресурсы. В зависимости от вида ресурса применяются три подхода: дублирование, разделение и совместное использование.
Дублированныересурсы.Дляподдержаниядвухполностьюнезависимыхконтекстов на каждом из логических процессоров некоторые ресурсы процессора необходимо дублировать. Прежде всего, это относится к счетчику команд (IP, Instruction Pointer), позволяющему каждому излогических процессоров отслеживать адрес очередной команды потока. Для параллельного выполнения нескольких процессов необходимо столько IP, сколько потоков команд необходимо отслеживать одновременно. Иными словами, у каждогологического процессорадолжен быть свой счетчик команд. В процессоре Хеоп максимальное количество потоков команд равно двум и поэтому требуется два счетчика команд. Кроме того, в процессоре имеются две таблицы распределения регистров (RAT, Register Allocation Table), каждая из которых обеспечивает отображение восьми регистров общего назначения (РОН) и восьми регистров с плавающей запятой (РПЗ), относящихся к одному логическому процессору, на совместно используемый регистровый файл из 128 РОН и 128 РПЗ. Таким образом, RAT — это дублированный ресурс, управляющий совместно используемым ресурсом (регистровым файлом).
Разделенныересурсы- Вкачествеодногоизвидов разделенныхресурсовв Хеоп выступают очереди (буферная память, организованная по принципу FIFO), рас-

Вычислительныесистемысуправлением вычислениями отпотокаданных 6 3 1
положенные между основными ступенями конвейера. Применяемое здесь разделение ресурсов можно условно назватьстатическим: каждая буферная память (очедедь) разбивается пополам, и за каждым логическим процессором закрепляется своя половина очереди.
Применительно к другому виду очередей — очередям диспетчеризации команд (их в процессоре три) — можно говорить о динамическом разделении. Вместо того чтобы из предусмотренных в каждой очереди двенадцати входов фиксировано назначить входы 0-5 логическому процессору (ЛП) 0, а входы 6-11 — логическому процессору 1, каждому ЛП разрешается использовать любые входы очереди, лишь бы их общее число не превысило шести.
С позиций логического процессора и потока между статическим и динамическим разделением нет никакой разницы — в обоих случаях каждому ЛП выделяется своя половина ресурса. Различие становится существенным, если в качестве отправнойточки взятьфизический процессор. Отсутствиепривязкипотоков к конкретным входам очереди позволяет не принимать во внимание, что имеются два потока, и расценивать обе половины как единую очередь. Очередь диспетчеризации команд просто просматривает каждую команду в общей очереди, оценивает зависимости между командами, проверяет доступность ресурсов, необходимых для выполнения команды, и планирует команду к исполнению. Таким образом, выдача команд на исполнение не зависит от того, какому потоку они принадлежат. Динамическое разделение очередей диспетчеризации команд предотвращает монополизацию очередей каким-либо одним из логических процессоров.
Завершая обсуждение разделяемых ресурсов, отметим, что если процессор Хеоп обрабатывает только один поток, то для обеспечения максимальной производительности этому потоку предоставляются все ресурсы процессора. В динамически разделяемых очередях снимаются ограничения на количество входов, доступных одному потоку, а в статических разделяемых очередях отменяется их разбиение на две половины.
Совместно используемые ресурсы. Этот вид ресурсов в гиперпотоковой технологии считается определяющим. Чем больше ресурсов могут совместно использовать логические процессоры, тем большую вычислительную мощность можно «снять» с единицы площади кристалла процессора. Первую группу общих ресурсов образуют функциональные (исполнительные) блоки: целочисленные операционные устройства, блоки операций с плавающей запятой и блоки обращения (чтения/записи) к памяти. Эти ресурсы "не знают", из какого ЛП поступила команда. То же самое можно сказать и о регистровом файле — втором виде совместно используемых ресурсов.
Сила гиперпотоковой технологии — общие ресурсы — одновременно является и ее слабостью. Проблема возникает, когда один поток монополизирует ключевой ресурс (такой, например, как блок операций с плавающейзапятой), чем блокирует другой поток, вызывая его остановку. Задача предотвращения таких ситуаций возлагается на компилятор и операционную систему, которые должны образовать потоки,состоящиеиз командсмаксимальноразличающимисятребованиями к совместно используемым ресурсам. Так, один поток может содержать команды, нуждающиеся главным образом в блоке для операций с плавающей запятой, а дру-

6 3 2 Глава 15. Потоковые и редукционные вычислительные системы
гой — состоять преимущественно из команд целочисленной арифметики и обращения к памяти,
В заключение необходимо остановиться на третьем видеобщих ресурсов — кэшпамяти. Процессор Хеоп предполагает работу с кэш-памятью трех уровней (LI, L2 и L3) и так называемой кэш-памятью трассировки. Оба логических процессора совместно используют одну и ту же кэш-память и хранящиеся в ней данные. Если поток, обрабатываемый логическим процессором 0, хочет прочитать некоторые данные, кэшированные логическим процессором 1, он может взять их из общего кэша. Из-за того, что в гиперпотоковом процессоре одну и ту же кэш-память используют сразу два логических процессора, вероятность конфликтов и, следовательно, вероятность снижения производительности возрастает.
Любой вид кэш-памяти одинаково трактует все обращения для чтения или записи, вне зависимости от того, какой из логических процессоров данное обращение производит. Это позволяет любому потоку монополизировать любой из кэшей, причем никакой защитой от монополизации, как это имеет место в случае очередейдиспетчеризации команд, процессорнеобладает. Иными словами, физический процессор не в состоянии заставить логические процессоры сотрудничать при их обращении к кэшам.
В целом, среди совместно используемых ресурсов в технологии hyperthreading кэш-память оказывается наиболее критичным местом, и конфликты за обладание этим ресурсом сказываются на общей производительности процессора наиболее ощутимо.
По оценке Intel, прирост скорости вычислений в некоторых случаях может достигать 25-35%. В приложениях, ориентированных на многозадачность, программы ускоряются на 15-20%. Возможны, однако, ситуации, когда прирост в быстродействии может быть незаметен и даже быть отрицательным. Таким образом, эффективность технологии находится в прямой зависимости от характера реализуемого программного приложения. Максимальная отдачадостигается при работе серверных приложений за счет разнообразия процессорных операций.
В настоящий момент аппаратная поддержка технологии заложена в микропроцессоры Pentium 4, причем,по информации Intel, в процессоре Pentium 4 Хеопэто потребовало 5% дополнительной площади на кристалле. Программная поддержка технологии предусмотрена в операционных системах Windows 2000, Windows XP и Windows .NET Server (в предшествующих ОС Windows такая возможность отсутствует).
Вычислительные системы с управлением вычислениями по запросу
В системах с управлением от потока данных каждая команда, для которой имеются все необходимые операнды, немедленно выполняется. Однако для получения окончательного результата многие из этих вычислений оказываются ненужными. Отсюда прагматичным представляется иной подход, когда вычисления инициируются не по готовности данных, а на основе запроса на данные. Такая организациявычислительногопроцессаноситназваниеуправлениявычислениямипозапросу

Вычислительныесистемы с управлением вычислениями позапросу 6 3 3
(demand-driven control). В ее основе, как и в потоковой модели (data-driven control), лежит представление вычислительного процесса в виде графа. В потоковой модели узлы вверху графа запускаются раньше, чем нижние. Это — нисходящая обработка. Механизм управления по запросу состоит в обработке вершин потокового графа снизу вверх путем разрешения запуска узла, лишь когда требуется его результат. Данный процесс получил названиередукции графа, а ВС, оперирующая в режиме снизу вверх (см, рис. 15.1, г), называется редукционной вычислительной системой.
Математическую основу редукционных ВС составляют лямбда-исчисления [2, 57,202], адля написания программ под такие системы нужны так называемые функциональные языки программирования (FP, Haskell и др.). На функциональном языке все программы представляются в виде выражений, а процесс выполнения программы заключается в определении значений последних (это называется оценкой выражения). Оценка выражения производится посредством повторения операции выбора и упрощения тех частей выражения, которые можно свести от сложного к простому (такая часть выражения называется редексом, причем сам редекс также является отдельным выражением). Операция упрощения называетсяредукцией. Процесс редукции завершается, когда преобразованное редукцией выражение больше не содержит редекса. Выражение, не содержащее редекса, называется
нормальнойформой.
В редукционной ВС вычисления производятся по запросу на результат операции. Предположим, что вычисляется выражение а = (b +1) х с — .В случае потоковых моделей процесс начинается с самых внутренних операций, а именно с параллельного вычисления (b + 1) и d/c. Затем выполняется операция умножения (b + 1) х с и, наконец, самая внешняя операция — вычитание. Такой род вычислений частоназываютэнергичнымивычислениями (eagerevaluation).
При вычислениях, управляемых запросами, все начинается с запроса на результат а, который включает в себя запрос на вычисление выражений (b + 1) х с и d/c, а те, в свою очередь, формируют запрос на вычисление b + 1, то есть на операцию самого внутреннего уровня. Результат возвращается в порядке, обратном поступлению запросов. Отсюда название ленивые вычисления (lazy evaluation), поскольку операции выполняются только тогда, когда их результат требуется другой команде. Редукционные вычисления, естественно, согласуются сконцепциейфункционального программирования, упрощающей распараллеливание программ.
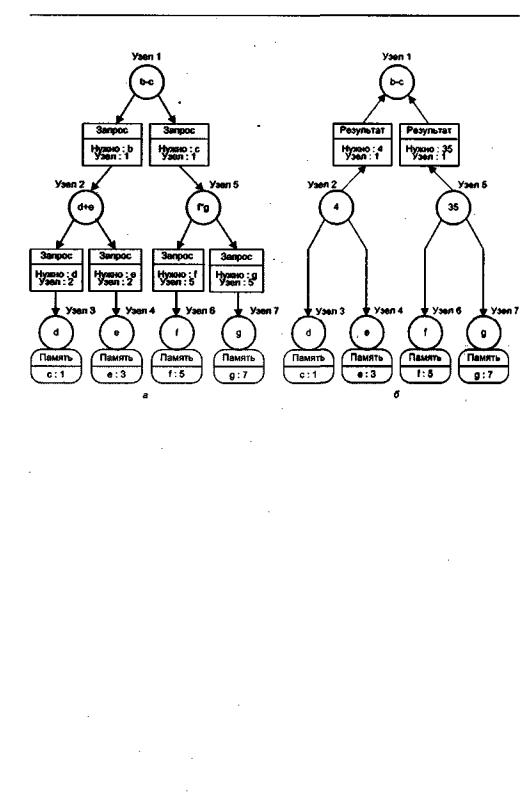
На рис. 15.16 показан процесс вычисления с помощью редукционной ВС зна-
чентвырзжешяа=b - с(b =d + е,с=fxg) для d= 1,е = 3,f=5,g=7.Программа
редукции состоит из распознавания редексов с последующей заменой их вычисленными значениями. Таким образом, вся программа в конечном итоге редуцируется до результата.
Известны два типа моделей редукционных систем: строчная и графовая, отличающиеся тем, что именно передается в функцию — скопированные значения данных или же только указатели, указывающие на места хранения данных.
В строчной редукционной модели каждый запросивший узел получает отдельную копию выражения для собственной оценки. Длинное строковое выражение
6 3 4 Глава 15. Потоковые и редукционные вычислительные системы
Рис. 15.16. Пример вычисления выражения на редукционной вычислительной системе: а — исходное положение; б — после первого шага редукции
рекурсивным образом сокращается (редуцируется) до единственного значения. Каждый шаг редукции содержит оператор, сопровождаемый ссылкой на требуемые входные операнды. Оператор приостанавливается, пока оцениваются входные параметры.
Нарис. 15.17показан процессвычисленийс помощьюстрочной редукции. Если требуется значение a=(b + с) х (b - с) (рис. 15.17, я), то копируется граф программы, определяющий вычисление а (рис. 15.17,6). При этом запускается операция умножения. Поскольку это вычисление невозможно без предварительного расчета двух параметров, то запускаются вычисления «+» и «-», в результате чего образуется редуцированный граф (с ветвями «6» и «2»), показанный на рис, 15.17, в. Результат получается путем дальнейшей редукции (рис. 15.17, г),
Вграфовойредукционноймоделивыражениепредставленокакориентированный граф. Граф сокращается по результатам оценки ветвей и подграфов. В зависимости от запросов возможно параллельное оценивание и редукция различных частей графа или подграфов. Запросившему узлу, который управляет всеми ссылками на граф, возвращается указатель на результат редукции. «Обход» графа и изменение ссылок продолжаются, пока не будет получено значение результата, копия которого возвращается запросившей команде.
Рисунок 15.18 иллюстрирует пример вычислений с помощью графовой редукции. В этой модели, когда требуется найти значение а, определение вычисления а не копируется, а передается указатель определяющей программы. При достиже-