

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfМоделиархитектуры памяти вычислительныхсистем 4 9 5
а |
б |
Рис. 11.1. Памятьс чередованием адресов:а — распределениеадресов; б — элементы, извлекаемые с шагом 9 из массива 8х8
достаточного числа банков, имеется возможность обмена информацией между процессором и памятью со скоростью одно слово за цикл процессора, независимо от длительности цикла памяти.
Решение о том, какой вариант распределения адресов выбрать (поблочный или
срасслоением), зависит от ожидаемого порядка доступа к информации. Программы компилируются так, что последовательные команды располагаются в ячейках
споследовательными адресами, поэтому высока вероятность, что после команды, извлеченной из ячейки с адресом i, будет выполняться команда из ячейки i + 1. Элементы векторов компилятор также помещает в последовательные ячейки, поэтому в операциях с векторами можно использовать преимущества метода чередования. Поэтой причине в векторныхпроцессорахобычноприменяется какой-либо вариант чередования адресов. В мультипроцессорах с совместно используемой памятью тем не менее используется поблочная адресация, поскольку схемы обращения к памяти в MIMD-системах могут сильно различаться. В таких системах целью является соединить процессор с блоком памяти и задействовать максимум находящейся в нем информации, прежде чем переключиться на другой блок памяти.
Системы памяти зачастую обеспечивают дополнительную гибкость при извлечении элементов векторов. В некоторых системах возможна одновременная загрузка каждого n-го элемента вектора, например, при извлечении элементов вектора
v1 хранящегося в последовательных ячейках памяти при и - 4, память возвратит vО,v4,v8.Интервал между элементами называют шагом по индексу или «страйЪомъ (stride). Одним из интересных применений этого свойства может служить доступ к матрицам. Если шагпо индексу на единицу больше числа строк в матрице, одиночный запрос на доступ к памяти возвратит все диагональные элементы матрицы (рис. 11.1, б). Ответственность за то, чтобы все извлекаемые элементы матрицы располагались в разных банках, ложится на программиста.
Модели архитектуры памяти вычислительных систем
В рамках как совместно используемой, так и распределенной памяти реализуется несколько моделей архитектур системы памяти.

4 9 6 Глава 11. Организация памяти вычислительных систем
Рис. 11.2. Классификация моделей архитектур памяти вычислительных систем
На рис. 11.2 приведена классификация таких моделей, применяемых в вычислительных системах класса MIMD (верна и для класса SIMD).
Модели архитектур совместно используемой памяти
В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу, но обычно практикуется второй вариант.
Вычислительныесистемысобщей памятью,гдедоступлюбогопроцессорак памяти производится единообразно и занимает одинаковое время, называют системамисоднороднымдоступомкпамятииобозначаютаббревиатуройUMA(Uniform Memory Access). Это наиболее распространенная архитектура памяти параллельных ВС с общей памятью [120].
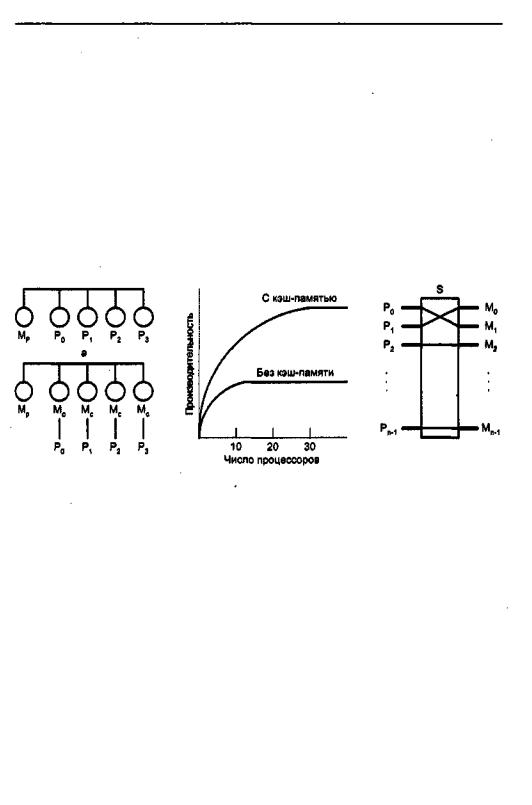
Технически UMА-системы предполагают наличие узла, соединяющего каждый из п процессоров с каждым из т модулей памяти. Простейший путь построения таких ВС — объединение нескольких процессоров (Pi) с единой памятью (Mp) посредством общей шины — показан на рис. 11.3, а. В этом случае, однако, в каждый момент времени обмен по шине может вести только один из процессоров, то есть процессоры должны соперничать за доступ к шине. Когда процессорРi,выбирает изпамятикоманду,остальныепроцессорыPj(iнеравноj)должныожидать,пока
шинаосвободится.Есливсистемувходяттолькодвапроцессора,онивсостояниир тать с производительностью, близкой к максимальной, поскольку их доступ к шине
Модели архитектуры памяти вычислительных систем 4 9 7
можно чередовать; пока один процессор декодирует и выполняет команду, другой вправе использовать шину для выборки из памяти следующей команды. Однако когда добавляется третий процессор, производительность начинает падать. При наличии на шине десяти процессоров кривая быстродействия шины (рис. 11.3, в) становится горизонтальной, так что добавление 11-го процессора уже не дает повышения производительности. Нижняя кривая на этом рисунке иллюстрирует тот факт, что память и шина обладают фиксированной пропускной способностью, определяемой комбинацией длительности цикла памяти и протоколом шины, и в многопроцессорной системе с общей шиной эта пропускная способность распределена между несколькими процессорами. Если длительность цикла процессора больше по сравнению с циклом памяти, к шине можно подключать много процессоров. Однако фактически процессор обычно намного быстрее памяти, поэтому данная схема широкого применения не находит.
б |
г |
Рис. 11.3. Общая память: а — объединение процессоров с помощью шины; б — система слокальнымикэшами;в—производительностьсистемыкакфункцияотчислапроцессоров наШине; г— многопроцессорнаяВСсобщейпамятью,состоящейизотдельныхмодулей
Альтернативный способ построения многопроцессорной ВС,с общей памятью на основе UMA показан на рис. 11.3, г. Здесь шиназаменена коммутатором, маршрутизирующим запросы процессора к одному из нескольких модулей памяти. Несмотря на то что имеется несколько модулей памяти, все они входят в единое виртуальное адресное пространство. Преимущество такого подхода в том, что коммутатор в состоянии параллельно обслуживать несколько запросов. Каждый процессор может быть соединен со своим модулем памяти и иметь доступ к нему на максимально допустимой скорости. Соперничество между процессорами может возникнуть при попытке одновременного доступа к одному и тому же модулю памяти, В этом случае доступ получает только один процессор, а прочие — блокируются.
К сожалению, архитектура UMA не очень хорошо масштабируется. Наиболее распространенные системы содержат 4-8 процессоров, значительно реже 32-64 процессора. Кроме того, подобные системы нельзя отнести к отказоустойчивым, так как отказ одного процессора или модуля памяти влечет отказ всей ВС.

4 9 8 Глава 11. Организация памяти вычислительных систем
Другим подходом к построению ВС с общей памятью является неоднородный доступ к памяти, обозначаемый как NUMA (Non-Uniform Memory Access). Здесь по-прежнему фигурирует единое адресное пространство, но каждый процессор имеет локальную память. Доступ процессора к собственной Локальной памяти производится напрямую, что намногобыстрее, чем доступ кудаленной памяти через коммутатор или сеть. Такая система может быть дополнена глобальной памятью, тогда локальные запоминающие устройства играют роль быстрой кэш-памяти для глобальной памяти. Подобная схема может улучшить производительность ВС, но не в состоянии неограниченно отсрочить выравнивание прямой производительности. При наличии у каждого процессора локальной кэш-памяти (рис. 11.3,6) существует высокая вероятность (р > 0,9) того, что нужные команда или данные уже находятся в локальной памяти. Разумная вероятность попадания в локальную память существенно уменьшает число обращений процессора к глобальной памяти и, таким образом, ведет к повышению эффективности. Место излома кривой производительности (верхняя кривая на рис. 11.3, в), соответствующее точке,
вкоторой добавление процессоров еще остается эффективным, теперь перемещается в область 20 процессоров, а точка, где кривая становится горизонтальной, -
вобласть 30 процессоров.
Врамках концепции NUMA реализуется несколько различных подходов, обо- значаемыхаббревиатурамиСОМА,CC-NUMAиNCC-NUMA.
Вархитектуре только с кэш-памятью (СОМА, Cache Only Memory Architecture) локальная память каждого процессора построена как большая кэш-память для быстрого доступа со стороны «своего» процессора [44]. Кэши всех процессоров в совокупности рассматриваются как глобальная память системы. Собственно глобальная память отсутствует. Принципиальная особенность концепции СОМА выражается в динамике. Здесь данные не привязаны статически к определенному модулю памяти и не имеют уникального адреса, остающегося неизменным в течение всего времени существования переменной. В архитектуре СОМА данные пе- реносятсявкэш-памятьтогопроцессора,который последнимихзапросил, приэтом переменная не фиксирована уникальным адресом и в каждый момент времени может размещаться в любой физической ячейке. Перенос данных из одного локального кэша в другой не требует участия в этом процессе операционной системы, но подразумевает сложную и дорогостоящую аппаратуру управления памятью. Для организации такого режима используют так называемые каталоги кэшей. Отметим также, что последняя копия элемента данных никогда из кэш-памяти не удаляется.
Поскольку в архитектуре СОМА данные перемещаются в локальную кэш-па- мять процессора-владельца, такие ВС в плане производительности обладают существенным преимуществом наддругими архитектурами NUMА. С другой стороны, если единственная переменная или две различные переменные, хранящиеся в одной строке одного и того же кэша, требуются двум процессорам, эта строка кэша должна перемещаться между процессорами туда и обратно при каждом доступе к данным. Такие эффекты могут зависеть от деталей распределения памяти и приводить к непредсказуемым ситуациям.
Моделькэш-когерентногодоступакнеоднороднойпамяти(CC-NUMA,Cache Coherent Non-Uniform Memory Architecture) принципиально отличается от модели

Модели архитектуры памяти вычислительных систем 4 9 9
СОМА. В системе CC-NUMA используется не кэш-память, а обычная физически распределенная память. Не происходит никакого копирования страниц или данных между ячейками памяти. Нет никакой программно реализованной передачи сообщений. Существует просто одна карта памяти, с частями, физически связанными медным кабелем, и «умные» аппаратные средства. Аппаратно реализованная кэш-когерентность означает, что не требуется какого-либо программного обеспечения для сохранения множества копий обновленных данных или их передачи. Со всем этим справляется аппаратный уровень. Доступ к локальным Модулям памяти в разных узлах системы может производиться одновременно и происходит быстрее, чем к удаленным модулям памяти.
Отличиемоделискэш-некогерентнымдоступомкнеоднороднойпамяти(NCC- NUMA, Non-Cache Coherent Non-Uniform Memory Architecture) от CC-NUMA очевидно из названия. Архитектура памяти предполагает единое адресное пространство, но не обеспечивает согласованности глобальныхданных на аппаратном уровне. Управление использованием таких данных полностью возлагается на программное обеспечение(приложенияиликомпиляторы).Несмотрянаэтообстоятельство,представляющееся недостатком архитектуры, она оказывается весьма полезной при повышении производительности вычислительных систем с архитектурой памяти типа DSM, рассматриваемой в разделе «Модели архитектур распределенной памяти».
В целом, ВС с общей памятью, построенные по схеме NUMA, называют архитектурами с виртуалъной общей памятью (virtual shared memory architectures). Данный вид архитектуры, в частности CC-NUMA, в последнее время рассматривается как самостоятельный и довольно перспективный вид вычислительных систем класса MIMD, поэтому такие ВС ниже будут обсуждены более подробно.
Модели архитектур распределенной памяти
В системе с распределенной памятью каждый процессор обладает собственной памятью и способен адресоваться только к ней. Некоторые авторы называют этот тип систем многомашинными ВС или мульткомпьютерами, подчеркивая тот факт, что блоки, из которых строится система, сами по себе являются небольшими вычислительными системами с процессором и памятью. Модели архитектур с распределенной памятью принято обозначать как архитектуры без прямого доступа кудаленной памяти (NORMA, No Remote Memory Access). Такое название следует из того факта, что каждый процессор имеет доступ только к своей локальной памяти. Доступ к удаленной памяти (локальной памяти другого процессора) возможен только путем обмена сообщениями с процессором, которому принадлежит адресуемая память.
Подобная организация характеризуется рядом достоинств. Во-первых, при доступе к данным не возникает конкуренции за шину или коммутаторы — каждый процессор может полностью использовать полосу пропускания тракта связи с собственной локальной памятью. Во-вторых, отсутствие общей шины означает, что нет и связанных с этим ограничений на число процессоров: размер системы ограничивает только сеть, объединяющая процессоры. В-третьих, снимается проблема когерентности кэш-памяти. Каждый процессор вправесамостоятельно менятьсвои данные, не заботясь о согласовании копий данных в собственной локальной кэшпамяти с кэшами других процессоров.

5 0 0 Глава 11. Организация памяти вычислительных систем
Основной недостаток ВС с распределенной памятью заключается в сложности обмена информацией между процессорами. Если какой-то из процессоров нуждается в данных из памяти другого процессора, он должен обменяться с этим процессором сообщениями. Это приводит к двум видам издержек:
-требуется время для того, чтобы сформировать и переслать сообщение от одного процессора к другому;
-для обеспечения реакции на сообщения от других процессоров принимающий процессор должен получить запрос прерывания и выполнить процедуру обработки этого прерывания.
Структура системы с распределенной памятью приведена на рис. 11.4. В левой части (рис. 11.4, а) показан один процессорный элемент (ПЭ). Он включает в себя собственно процессор (Р), локальную память (М) и два контроллера ввода/вывода (Ко и Ki), В правой части (рис. 11.4, б) показана четырехпроцессорная система, иллюстрирующая, каким образом сообщения пересылаются от одного процессора к другому. По отношению к каждому ПЭ все остальные процессорные элементы можно рассматривать просто как устройства ввода/вывода. Для посылки сообщения в другой ПЭ процессор формирует блок данных в своей локальной памяти и извещает свой локальный контроллер о необходимости передачи информации на внешнее устройство. По сети межсоединений это сообщение пересылается на приемный контроллер ввода/вывода принимающего ПЭ. Последний находит место для сообщения в собственной локальной памяти и уведомляет процессор-источ- ник о получении сообщения.
а |
б |
Рис, 11 .4. Вычислительная система с распределенной памятью: а — процессорный элемент; б— объединение процессорныхэлементов
Интересный вариант системы с распределенной памятью представляет собой модельраспределеннойсовместноиспользуемойпамяти(DSM,DistributeShared Memory), известной также и поддругим названиемархитектуры снеоднородным доступомкпамятиипрограммнымобеспечениемкогерентности(SC-NUMA,Soft ware-Coherent Non-Uniform Memory Architecture). Идея этой модели состоит в том, что ВС, физически будучи системой с распределенной памятью, благодаря операционной системе представляется пользователю как система с общей памятью. Это означает, что операционная система предлагает пользователю единое адресное пространство, несмотря на то что фактическое обращение к памяти "чужого" компьютера ВС по-прежнему обеспечивается путем обмена сообщениями.

Мультипроцессорная когерентность кэш-памяти |
5 0 1 |
Мультипроцессорная когерентность кэш-памяти
Мультипроцессорная система с разделяемой памятью состоит из двух или более независимых процессоров, каждый из которых выполняет либо часть большой программы, либо независимую программу. Все процессоры обращаются к командам иданным,хранящимся в общей основной памяти. Поскольку памятьявляется обобществленным ресурсом, при обращении к ней между процессорами возникает соперничество, в результате чего средняя задержка на доступ к памяти увеличивается. Для сокращения такой задержки каждому процессору придается локальная кэш-память, которая, обслуживая локальные обращения к памяти, во многих случаях предотвращает необходимость доступа к совместно используемой основной памяти. В свою очередь, оснащение каждого процессора локальной кэш-памя- тьюприводитктакназываемойпроблемекогерентностиилиобеспечениясогласованности кэш-памяти. Согласно [93, 215], система является когерентной, если каждая операция чтения по какому-либо адресу, выполненная любым из процессоров, возвращает значение, занесенное в ходе последней операции записи по этому адресу, вне зависимости от того, какой из процессоров производил запись последним.
В простейшей форме проблему когерентности кэш-памяти можно пояснить следующим образом (рис 11.5). Пусть два процессора Р1 и Р2 связаны с общей памятью посредством шины. СначалаобаCпроцессора читают переменную х. Копии блоков, содержащих эту переменную, пересылаются из основной памяти в локальные кэши обоих процессоров (рис. 11.5, а). Далее процессор Р1 выполняет операцию увеличения значения переменной x на единицу. Так как копия переменной уже находится в кэш-памяти данного процессора, произойдет кэш-попадание и значениех будет изменено только в кэш-памяти 1. Если теперь процессор Р2 вновь выполнит операцию чтения х, то также произойдет кэш-попадание и Р2 получит хранящееся в его кэш-памяти «старое» значение х (рис. 11.5,5).
Поддержание согласованности требует, чтобы при изменении элементаданных одним из процессоров соответствующие изменения были проведены в кэш-памя- ти остальных процессоров, где есть копия измененного элемента данных, а также в общей памяти. Схожая проблема возникает, кстати, и в однопроцессорных сиc- . темах, где присутствует несколько уровней кэш-памяти. Здесь требуется согласовать содержимое кэшей разных уровней.
Врешении проблемы когерентности выделяются два подхода: программный
иаппаратный. В некоторых системах применяютстратегии, совмещающие оба подхода.
Программные способы решения проблемы когерентности
Программные приемы решения проблемы когерентности позволяют обойтись без дополнительного оборудования или свести его к минимуму [72]. Задача возлагается на компилятор и операционную систему. Привлекательность такого подхода в возможности устранения некогерентности еще до этапа выполнения программы,

5 0 2 Глава 11. Организация памяти вычислительных систем
а |
б |
Рис. 11.5. Иллюстрация проблемы когерентности памяти: а — содержимое памяти до изменения значения х; б — после изменения
однако принятые компилятором решения могут в целом отрицательно сказаться наэффективностикэш-памяти.
Компилятор анализирует программный код, определяет те совместно используемые данные, которые могут стать причиной некогерентности, и помечает их. В процессе выполнения программы операционная система или соответствующая аппаратура предотвращают кэширование (занесение в кэш-память) помеченных данных, и вдальнейшемдля доступа к ним, как при чтении, так и при записи, приходится обращаться к «медленной» основной памяти. Учитывая, что некогерентность возникает только в результате операций записи, происходящих значительно реже, чем чтение, рассмотренный прием следует признать недостаточно удачным.
Более эффективными представляются способы, где в ходе анализа программы определяются безопасные периоды использования общих переменных и так называемые критические периоды, где может проявиться некогерентность. Затем компилятор вставляет в генерируемый код инструкции, позволяющие обеспечить когерентность кэш-памятей именно в такие критические периоды.
Аппаратные способы решения проблемы когерентности
Большинство из предложенных способов борьбы с некогерентностью ориентированы на динамическое (в процессе вычислений) распознавание и устранение несогласованности копий совместно используемых данных с помощью специальной аппаратуры. Аппаратные методы обеспечивают более высокую производительность, поскольку издержки, связанные с некогерентностью, имеют место только при возникновении ситуации некогерентности. Кроме того, непрограммный подход прозрачен для программиста и пользователя [215]. Аппаратные механизмы

Мультипроцессорная когерентность кэш-памяти 5 0 3
преодоления проблемы когерентности принято называть протоколами когерент- ностикэш-памяти.
Как известно, для обеспечения идентичности копийданных в кэше и основной памяти в однопроцессорных системах применяется одна из двух стратегий: сквозная запись (write through) или обратная запись (write back). При сквозной записи новая информация одновременно заносится как в кэш, так и в основную память. При обратной записи все изменения производятся только в кэш-памяти, а обновление содержимого основной памяти происходитлишь при удалении блока из кэшпамяти путем пересылки удаляемого блока в соответствующее место основной памяти. В случае мультипроцессорной системы, когда копии совместно используемых данных могут находиться сразу в нескольких кэшах, необходимо обеспечить когерентность всех копий. Ни сквозная, ни обратная запись не предусматривают такой ситуации, и для ее разрешения опираются на другие приемы, а именно: записьсаннулированием(writeinvalidate)изаписьсобновлением(writeupdate).Последняя известна также под названием записи с трансляцией (write broadcast).
В варианте записи с аннулированием, если какой-либо процессор производит изменения в одном из блоков своей кэш-памяти, все имеющиеся копии этого блока в других локальных кэшах аннулируются, то есть помечаются как недостоверные. Для этого бит достоверности измененного блока (строки) во всех прочих кэшах устанавливается в 0. Идею записи с аннулированием иллюстрирует рис. 11.6, где показано исходное состояние системы памяти, где копия переменной х имеется во всех кэшах (рис. 11.6, а), а также ее состояние после записи нового значения х в кэш с номером 2 (рис 11.6, б).
а |
б |
Рис. 11.6. Записьсаннулированием: а — исходное состояние; 6— после изменения значений х в кэш-памяти 2
Если впоследствии другой процессор попытается прочитать данные из своей копиитакогоблока,произойдеткэш-промах. Следствием кэш-промахадолжнобыть занесение влокальную кэш-памятьчитающегопроцессоракорректной копииблока. Некоторые схемы когерентности позволяют получить корректную копию непосредственно из той локальной кэш-памяти, где блок подвергся модификации. Если такая возможность отсутствует, новая копия берется из основной памяти. В слу-

5 0 4 Глава 11. Организация памяти вычислительных систем
чае сквозной записи это может быть сделано сразу же, а при использовании обратной записи модифицированный блок предварительно должен быть переписан в основную память.
Запись с обновлением предполагает, что любая запись в локальный кэш немедленно дублируется и во всех остальных кэшах, содержащих копию измененного блока (немедленное обновление блока в основной памяти не является обязательным). Этот случай иллюстрирует рис. 11.7.
а |
6 |
Рис. 11.7. Запись с обновлением: в — исходное состояние; б — после изменения значения х в кэш-памяти 2
Стратегия записи с обновлением требует широковещательной передачи новых данных по сети межсоединений, что осуществимо не при любой топологии сети.
В общем случае для поддержания когерентности в мультипроцессорных системах имеются следующие возможности:
-совместно используемая кэш-память; ^- некэшируемые данные;
-широковещательная запись;
-протоколы наблюдения;
-протоколы на основе справочника.
Совместно используемая кэш-память. Первое и наиболее простое решение - вообще отказаться от локальных кэшей и все обращения к памяти адресовать к одной общей кэш-памяти,связанной со всеми процессорами посредством какой-либо коммуникационной сети. Хотя данный прием обеспечивает когерентность копий данных и прозрачен для пользователя, количество конфликтов по доступу к памяти он неснижает, поскольку возможноодновременноеобращение несколькихпроцессоров к одним и тем жеданным в обшей кэш-памяти. Кроме того, наличие разделяемой кэш-памяти нарушает важнейшее условие высокой производительности, согласно которому процессор и кэш-памятьдолжны располагаться как можно ближе друг к другу. Положение осложняется и тем, что каждый доступ к кэшу связан с обращением к арбитру, который определяет, какой из процессоров получит дос-