

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdfВычислительные системы с неоднородным доступом к памяти 6 0 5
Рис. 14.15. Организация систем типа CC-NUMA
держит справочник, где хранится информация о местоположении в системе каждой составляющей глобальной памяти, а также о состоянии кэш-памяти.
Чтобы проанализировать, как работает такая схема, воспользуемся примером, приведенным в [182]. Пусть процессор 3 узла 2 (Р2.3) запрашивает ячейку с адресом 798, расположенную в узле 1. Будет наблюдаться такая последовательность действий:
1.Р2.3 выдает на шину наблюдения узла 2 запрос чтения ячейки 798.
2.Справочник узла 2 видит запрос и распознает, что нужная ячейка находится в узле 1.
3.Справочник узла 2 посылает запрос узлу 1, который принимается справочником узла 1.
4.Справочник основной памяти 1, действуя как заменитель процессора Р2.3, запрашивает ячейку 798, так как будто он сам является процессором.
5.Основная память узла 1 реагирует тем, что помещает затребованные данные на локальную шину узла 1.
6.Справочник узла 1 перехватывает данные с шины.
7.Считанное значение через сеть соединений передается обратно в справочник узла 2.
8.Справочник узла 2 помещает полученные данные на локальную шину узла 2, действуя при этом как заместитель той части памяти, где эти данные фактически хранятся.

6 0 6 Глава 14. Вычислительные системы класса MIMD
9.Данные перехватываются и передаются в кэш-память процессора Р2.3 и уже оттуда попадают в процессор Р2.3.
Из описания видно, как данные считываются из удаленной памяти с помощью аппаратных механизмов, делающих транзакции прозрачными для процессора. В основеэтих механизмов лежит какая-либо форма протокола когерентности кэшпамяти. Большинство реализаций отличаются именно тем, какой именно протокол когерентности используется.
Вычислительные системы на базе транспьютеров
Появление транспьютеров связано с идеей создания различных по производительности ВС (от небольших до мощных массивно-параллельных) посредством прямого соединения однотипных процессорных чипов. Сам термин объединяет два понятия — «транзистор» и «компьютер».
Транспьютер — это сверхбольшая интегральная микросхема (СБИС), заключающая в себе центральный процессор, блок операций с плавающей запятой (за исключением транспьютеров первого поколения Т212 и Т414), статическое оперативное запоминающее устройство, интерфейс с внешней памятью и несколько каналов связи. Первый транспьютер был разработан в 1986 году фирмой Inmos.
Канал связи состоит из двух последовательных линий для двухстороннего обмена. Он позволяет объединить транспьютеры между собой и обеспечить взаимныекоммуникации.Данныемогут пересылаться поэлементноили каквектор. Одна из последовательных линий используется для пересылки пакета данных, а вторая — для возврата пакета подтверждения, который формируется как только пакет данных достигнет пункта назначения.
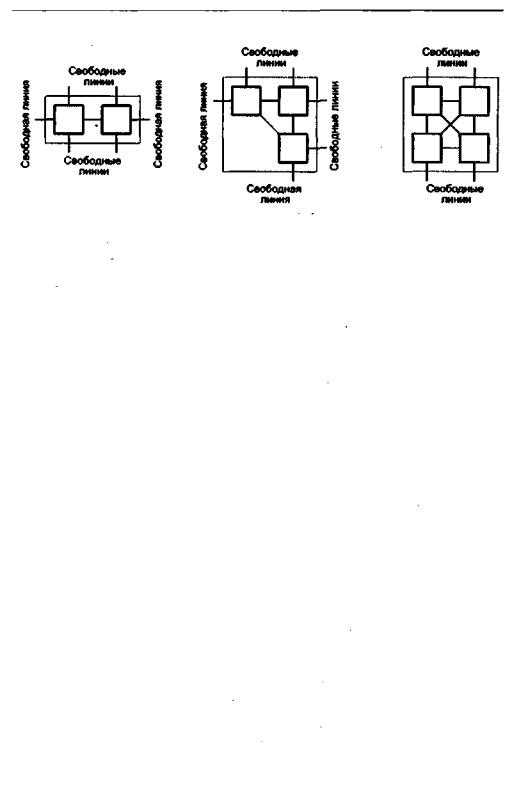
На базе транспьютеров легко могут быть построены различные виды ВС. Так, четыре канала связи обеспечивают построение двухмерного массива, где каждый транспьютер связан с четырьмя ближайшими соседями. Возможны и другие конфигурации, например объединение транспьютеров в группы с последующим соединением групп между собой. Если группа состоит из двух транспьютеров, для подключения ее к другим группам свободными остаются шесть каналов связи (рис. 14.16, а). Комплекс из трехтранспьютеров также оставляет свободными шесть каналов (рис. 14.16,6 ), адля связи с «квартетом» транспьютеров остаются еще четыре канала связи (рис. 14.16, в). Группа из пяти транспьютеров может иметь полный набор взаимосвязей, но за счет потери возможности подключения к другим группам.
Особенности транспьютеров потребовали разработки для них специального языка программирования Occam. Название языкасвязаносименем философа-схо- ласта четырнадцатого века Оккама — автора концепции «бритвы Оккамак «entia praeter necessitatem non sunt multiplicanda» — «понятия не должны умножаться без необходимости». Язык обеспечивает описание простых операций пересылки данных между двумя точками, а также позволяет явно указать на параллелизм при выполнении программы несколькими транспьютерами. Основным понятием программы на языке Occam является процесс, состоящий из одного или более опера-
Вычислительные системы на базетранспьютеров 6 0 7
а |
6 |
в |
Рис. 14.16. Группы из полностью взаимосвязанных транспьютеров: а — два транспьютера; б—тритранспьютера;в—четыретранспьютера
торов программы, которые могутбыть выполнены последовательноили параллельно. Процессы могут быть распределены по транспьютерам вычислительной системы, при этом оборудование транспьютера поддерживает совместное использование транспьютера одним или несколькими процессами.
Принято говорить о двух поколениях транспьютеров и языка Occam. Первое поколение отражаеттребованиятех приложений,для которыхтранспьютеры и разрабатывались: цифровой обработки сигналов и систем реального времени. Для подобных задач нужны сравнительно небольшие ВС со скоростными каналами связи (главным образом, между соседними процессорами) и быстрым переключением контекста. Под контекстом понимается содержимое регистров, которое при переходе к новой задаче в ходе многозадачной обработки может быть изменено и поэтому должно быть сохранено, а при возврате к старой задаче — восстановлено. Многомашинные ВС, построенные на транспьютерах первого поколения (Т212, Т414 и Т805), по своей производительности были сравнимы с другими типами ВС того времени.
С появлением вычислительных систем второго итретьего поколений сталоясно, что ВС натранспьютерах ранней организации ужестали неконкурентоспособными, чтои побудило к созданию их второго поколения (Т9000). В последних существенно повышена производительность и улучшены каналы связи. Главная особенность транспьютеров второго поколения — развитые коммуникационные возможности, хотя в вычислительном плане, даже несмотря на наличие в них блоков для операций с плавающей запятой, они сильно уступают универсальным микропроцессорам, таким как PowerPC и Pentium.
Архитектура транспьютера
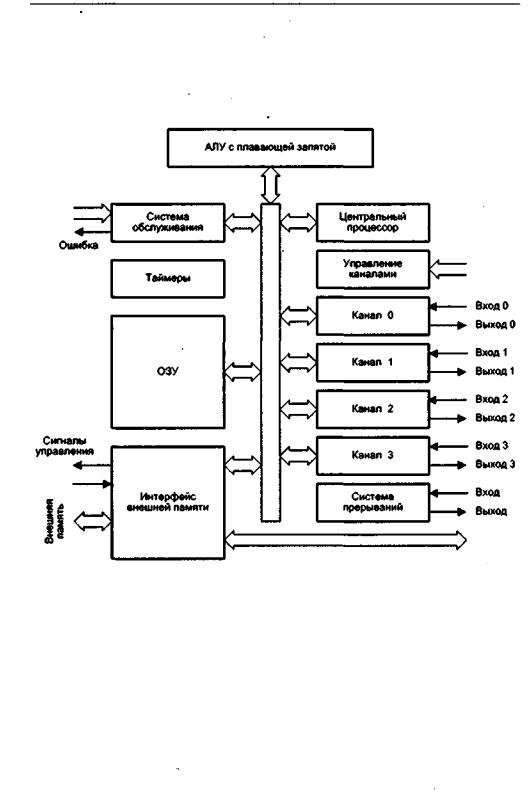
Обобщенная структура транспьютера, показанная на рис. 14.17, включает в себя:
-центральный процессор;
-АЛУ для операций с плавающей запятой;
-каналы связи;
-- внутреннюю память (ОЗУ);
6 0 8 Глава 14. Вычислительные системы класса MIMD
-интерфейс для подключения внешней памяти;
-интерфейс событий (систему прерываний);
-логику системного сервиса (систему обслуживания);
-таймеры.
Рис.14.17.Базоваявнутренняяархитектуратранспьютера
Первый транспьютер Т212 содержал 16-разрядный арифметический процессор. Последующие транспьютеры были оснащены 32-разрядным целочисленным процессором (Т414,1985) и процессором с плавающей запятой (Т800, Т9000), дающим существенное повышение скорости вычислений (до 100 MIPS). Версии, поддерживающие процессор с ПЗ, организованы так, что этот процессор и целочисленный процессор могут работать одновременно. В дополнение, в Т9000 добавлена внутренняя кэш-память и процессор виртуального канала. Сам по себе процессор транспьютера построен по архитектуре RISC, имеет микропрограммное УУ, а команды в нем выполняются за минимальное число циклов процессора. Простые операции, такие как сложение или вычитание, занимают один цикл, в то время как более сложные операции требуют нескольких циклов. Команды состоят
Вычислительные системы с обработкой попринципуволновогофронта 6 0 9
из одного или нескольких байтов. Большинство версий транспьютеров имеют по четыре последовательных какала связи со скоростью передачи по каналу порядка 10 Мбит/с. По мере развития транспьютеров повысилась скорость передачи по каналам связи. Емкость внутренней памяти (вначале 2 Кбайт) также возросла. Появилась возможность подключения внешней памяти через интерфейс памяти. Схема этого интерфейса программируется и способна формировать различные сигналы для удовлетворения различных требований самых разнообразных микросхем внешней памяти.
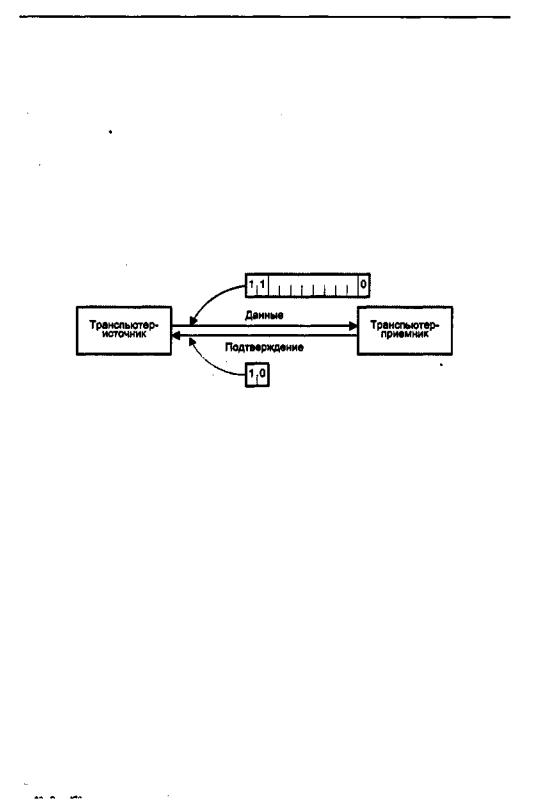
Передача информации производится синхронно под воздействием либо общего генератора тактовых импульсов (ГТИ), либо локальных ГТИ с одинаковой частотой следования импульсов. Информация передается в виде пакетов. Каждый раз, когда пересылается пакет данных, приемник отвечает пакетом подтверждения (рис.14.18).
Рис. 14.18. Организация ввода/вывода в транспьютерной системе
Пакет данных состоит из двух битов-единиц, за которыми следуют 8-битовые данные и ноль (всего 11 бит). Пакет подтверждения — это простая комбинация 10 (всего два бита), она может быть передана, как только пакет данных будет идентифицирован интерфейсом входного канала. Каналы обеспечивают аппаратную поддержку операторов ввода и выводаязыка Occam и функционируют словно каналы ПДП, то есть пакеты могут пересылаться один за другим как векторы. Для коммуникаций между процессами внутри транспьютера вместо внешних каналов операторы ввода/вывода используют внутренние каналы транспьютера.
Интерфейс событий дает возможность внешнему устройству привлечь внимание и получить подтверждение. Этот интерфейс функционирует как входной канал и аналогично программируется.
Вычислительные системы с обработкой попринципуволновогофронта
Интересной разновидностью систолических структур являются матричные процессоры волнового фронта (wavefront array processor), иногда называемые также
волновымиилифронтальными.
Как уже отмечалось, в основе построения систолических ВС лежит глобальная синхронизация массива процессоров, предусматривающая наличие сети распределения синхронизирующих сигналов по всей структуре. Б системах с очень большим числом ПЭ начинает сказываться запаздывание тактовых сигналов. Послед-

Контрольные вопросы |
6 1 1 |
массива завершает свои вычисления и готов передатьданные соседу, он может это сделать, лишь когда последний будет готов к их приему. Для проверки готовности соседа передающий процессор сначала направляет ему запрос, а данные посылает только после получения подтверждения о готовности их принять. Такой механизм обеспечивает соблюдение заданной последовательности вычислений и делает прохождение фронта вычислений через массив плавным, причем задача соблюдения последовательности вычислений решается непосредственно, в то время как в систолических ВС для этого требуется строгая синхронизация.
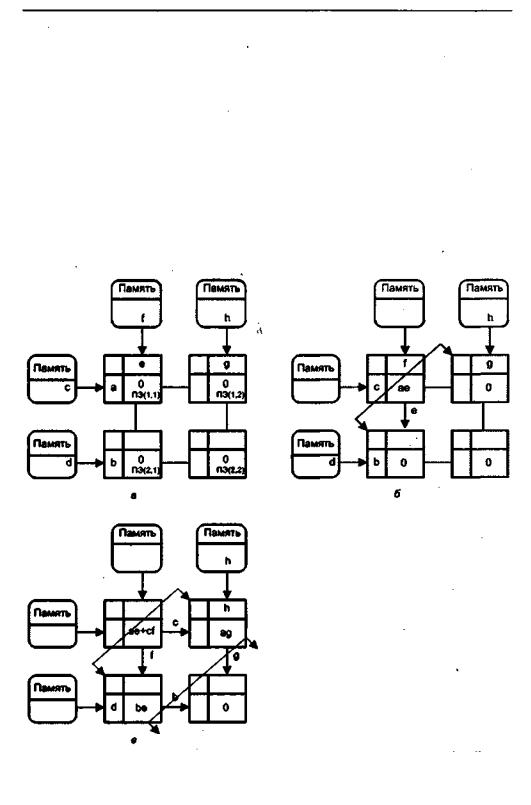
Концепцию массива процессоров волнового фронта проиллюстрируем на примере матричного умножения (рис. 14.19).
Вычислительная система в примере состоит из процессорных элементов, имеющих на каждом входе данных буфер на один операнд. Всякий раз, когда буфер пуст, а в памяти, являющейся источником данных, содержится очередной операнд, производится немедленное его считывание в буфер соответствующего процессора. Операнды из других ПЭ принимаются на основе протокола связи с подтверждением.
Рисунок 14.19, а фиксирует ситуацию после первоначального заполнения входных буферов. Здесь ПЭ(1,1) суммирует произведение а х е с содержимым своего аккумулятора и транслирует операнды а и е своим соседям. Таким образом, первый волновой фронт вычислений (см. рис. 14.19,6) перемещается в направлении от ПЭ(1,1) к ПЭ(1,2) иПЭ(2,1).Рисунок 14.19, в иллюстрирует продолжение распространения первого фронта и исход от ПЭ(1,1) второго фронта вычислений.
По сравнению с систолическими ВС массивы волнового фронта обладают лучшей масштабируемостью, проще в программировании и характеризуются более высокой отказоустойчивостью.
Контрольные вопросы
1.По какому признаку вычислительную систему можно отнести к сильно связанным или слабо связанным ВС?
2.Какие уровни параллелизма реализуют симметричные мультипроцессорные системы?
3.Какими средствами поддерживается когерентность кэш-памяти в SMP-систе- мах?
4.Оцените достоинства и недостатки различных SMP-архитектур.
5.В чем состоит принципиальное различие между матричными и симметричными мультипроцессорными вычислительными системами?
6.Какие две проблемы призвана решить кластерная организация вычислительной системы?
7.Существуют ли ограничения на число узлов в кластерной ВС? И если существуют, то чем они обусловлены?
8.Какие задачи в кластерной вычислительной системе возлагаются на специализированное (кластерное) программное обеспечение?

6 1 2 Глава 14. Вычислительные системы класса MIMD
9.Каким образом может быть организовано взаимодействие между узлами кластерной ВС?
10.При каком количестве процессоров ВС можно отнести к системам с массовой параллельной обработкой?
11.Как организуется координация процессоров и распределение между ними заданий в МРР-системах?
12.Какие топологии можно считать наиболее подходящимидля МРР-систем и почему?
13.Поясните назначениесправочникав вычислительныхсистемах типа CC-NUMA.
14.Какие протоколы когерентности, на ваш взгляд, наиболее подходят для ВС, построенных на технологии CC-NUMA?
15.Какие черты транспьютера отличают его от стандартной однокристальной ВМ?
16.Какими аппаратными и программными средствами поддерживается взаимодействие соседних транспьютеров в вычислительной системе?
17.Сколько линий поддерживает канал связи транспьютера, какони используются и в каком режиме осуществляется ввод/вывод?
18.Какие особенности транспьютеров облегчает реализовать язык Occam?
19.Опишите структуру пакета данных и пакета подтверждения, передаваемых в транспьютерных ВС.
20.Какие из рассмотренных типов вычислительных систем могут быть построены на базе транспьютеров и в каких случаях это наиболее целесообразно?
21.В чем состоят сходство и различие между систолическими ВС и вычислительными системами с обработкой по принципу волнового фронта?
22.Как организуется межпроцессорный обмен в массивах волнового фронта?

Глава15
Потоковые и редукционные вычислительные системы
В традиционных ВМ команды в основном выполняются в естественной последовательности, то есть в том порядке, в котором они хранятся в памяти. То же самое можно сказать и о традиционных многопроцессорных системах, где одновременно могут выполняться несколько командных последовательностей, но также в порядке размещения каждой из них в памяти. Это обеспечивается наличием в каждом процессоре счетчика команд. Выполнение команд в каждом процессоре — поочередное и потому достаточно медленное. Для получения выигрыша программист или компилятор должны определить независимые команды, которые могут быть поданы на отдельные процессоры, причем так, чтобы коммуникационные издержки были не слишком велики.
Традиционные (фон-неймановские) вычислительные системы, управляемые с помощью программного счетчика, иногда называют вычислительными системами,управляемымипоследовательностью команд(control flowcomputer).Данный термин особенно часто применяется, когда нужно выделить этот тип ВС из альтернативных типов, где последовательность выполнения команд определяется не центральным устройством управления со счетчиком команд, а каким-либо иным способом. Если программа, состоящая из команд, хранится в памяти, возможны следующие альтернативные механизмы ее исполнения:
-команда выполняется, после того как выполнена предшествующая ей команда последовательности;
-команда выполняется, когда становятся доступными ее операнды;
-команда выполняется, когда другим командам требуется результат ее выполнения.
Первый метод соответствует традиционному механизму с управлением последовательностью команд; второй механизм известен какуправляемый данными (data driven) илипотоковый (dataflow);третий метод называютмеханизмомуправления по запросу (demand driven).
6 1 4 Глава 15. Потоковые и редукционные вычислительные системы
Общие идеи нетрадиционных подходов к организации вычислительного процесса показаны на рис. 15.1, а их более детальному изложению посвящен текущий раздел-
Рис.15.1.Возможныевычислительныемодели:а—фон-неймановская;б—потоковая; в — макропотоковая; г—редукционная
Вычислительныесистемысуправлением вычислениямиотпотокаданных
Идеология вычислений, управляемых потоком данных (потоковой обработки), была разработана в 60-х гадах Карпом и Миллером. В начале 70-х годов Деннис, а позже и другие начали разрабатывать компьютерные архитектуры, основанные на вычислительной модели с потоком данных.
Вычислительная модель потоковой обработки
В потоковой вычислительной модели для описания вычислений используется ориентированный граф, иногда называемый графом потоков данных (dataflow graph). Этот граф состоит из узлов или вершин, отображающих операции, и ребер или дуг, показывающихпотокиданныхмеждутеми вершинами графа, которыеонисоединяют.
Узловые операции выполняются, когда по дугам в узел поступила вся необходимая информация. Обычно узловая операция требует одного или двух операндов, а для условных операции необходимо наличие входного логического значения. По выполнении операции формируются один или два результата. Таким образом, у каждой вершины может быть от одной до трех входящих дуг и одна или две выходящих. После активации вершины и выполнения узловой операции (это иногда называют инициированием вершины) результаты передаются по ребрам к ожидающим вершинам. Процесс повторяется, пока не будут инициированы все вершины и получен окончательный результат. Одновременно может быть инициировано несколько узлов, при этом параллелизм в вычислительной модели выявляется автоматически.