

ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdf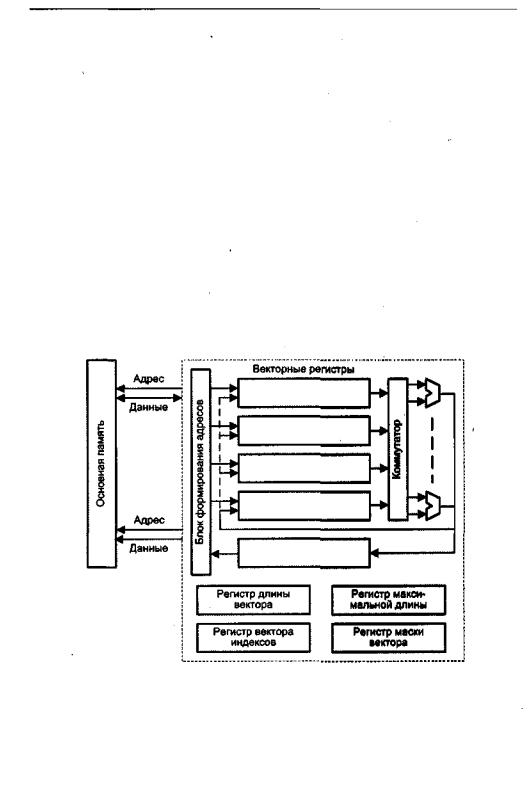
5 5 6 Глава 13. Вычислительные системы класса SIMD
сравнению порядков, сдвигу мантиссы меньшего из чисел, сложению мантисс и нормализации результата (рис. 13.5, а). Каждый этап может быть реализован с помощью отдельной ступени конвейерного АЛУ (рис. 13.5,6). Очередной элемент вектора подается на вход конвейера, как только освобождается первая ступень (рис. 13.5, в). Ясно, что такой вариант вполне годится для обработки векторов.
Одновременные операции над элементами векторов можно проводить и с помощью нескольких параллельно используемых АЛУ, каждое из которых отвечает за одну пару элементов (см. рис. 13.4,6). Такого рода обработка, когда каждое из АЛУ является конвейерным, показана на рис. 13.5, г.
Если параллельно используются конвейерные АЛУ, то возможен еще один уровень конвейеризации, что иллюстрирует рис. 13.5, д. Вычислительные системы, где реализована эта идея, называют векторно-конвейерными. Коммерческие вектор- но-конвейерные ВС, в состав которых для обеспечения универсальности включен также скалярный процессор, известны как суперЭВМ.
Структура векторного процессора
Обобщенная структура векторного процессора приведена на рис. 13.6. На схеме показаны основные узлы процессора, без детализации некоторых связей между ними.
Рис, 13.6. Упрощенная структура векторного процессора
Обработка всех п компонентов векторов-операндов задается одной векторной командой. Общепринято, что элементы векторов представляются числами в форме с плавающей запятой (ПЗ). АЛУ векторного процессора может быть реализовано в виде единого конвейерного устройства, способного выполнять все предусмотренные операции над числами с ПЗ. Более распространена, однако, иная

Векторныеи векторно-конвейерные вычислительные системы 5 5 7
структура, — в ней АЛУ состоит из отдельных блоков сложения и умножения,
аиногда и блока для вычисления обратной величины, когда операция деления
—реализуется в виде Х(1/Y). Каждый из таких блоков также конвейеризирован.
Крометого,всоставвекторнойвычислительнойсистемыобычновключаютискалярный процессор, что позволяет параллельно выполнять векторные и скалярные команды.
Для хранения векторов-операндов вместо множества скалярных регистров используют так называемые векторныерегистры, которые представляют собой совокупность скалярных регистров, объединенных в очередь типа FIFO, способную хранить 50-100 чисел с плавающей запятой. Набор векторных регистров (Va, Vb, Vc,...) имеется в любом векторным процессоре. Система команд векторного процессора поддерживает работу с векторными регистрами и обязательно включает в себя команды:
*загрузки векторного регистра содержимым последовательных ячеек памяти, указанных адресом первой ячейки этой последовательности;
-выполнения операций над всеми элементами векторов, находящихся в векторных регистрах;
-сохранения содержимого векторного регистра в последовательности ячеек памяти, указанных адресом первой ячейки этой последовательности.
Примером одной из наиболее распространенных операций, возлагаемых на векторный процессор, может служить операция перемножения матриц [161]. Рассмотрим перемножение двух матриц А и В размерности 3x3.
Элементы матрицы результата С связаны с соответствующими элементами исходных матриц А и В операцией скалярного произведения:
Так, элемент с11 вычисляется как
Это требует трех операций умножения и (после инициализации с11 нулем) трех операций сложения. Общее число умножений и сложений для рассматриваемого примера составляет 9 х 3 = 27. Если рассматривать связанные операции умножения и сложения как одну кумулятивную операцию с + а хb,тодля умножения двух матриц п х п необходимо п3 операций типа «умножение-сложением»Вся процедура сводится к получению п2 скалярных произведений, каждое из которых является итогом « операций «умножение-сложение», учитывая, что перед вычислением каждого элемента сij его необходимо обнулить. Таким образом, скалярное произведение состоит из k членов:
5 5 8 Глава 13. Вычислительные системы класса SIMD
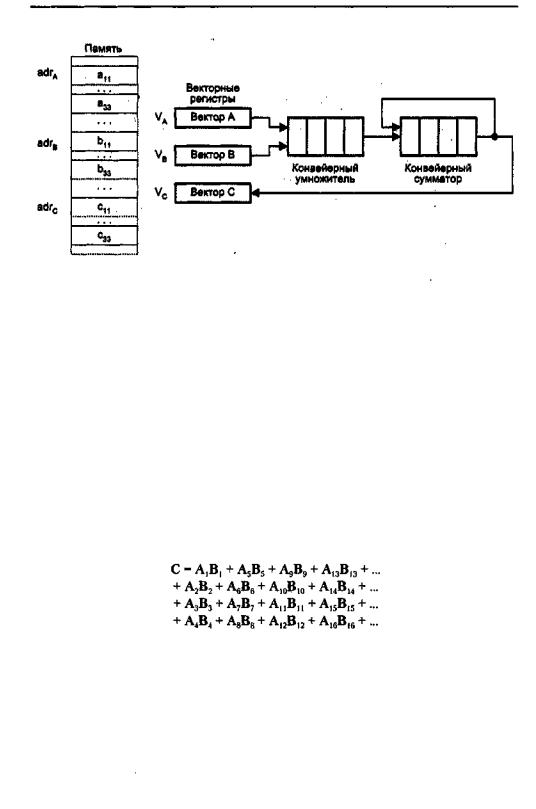
Рис. 13.7. Векторный процессор для вычисления скалярного произведения
Векторный процессор с конвейеризированнымиблокамиобработкидля вычисления скалярного произведения показан на рис. 13.7.
Векторы А и В, хранящиеся в памяти начиная с адресов adrA u adrB, загружаются в векторные регистры VA и VB соответственно. Предполагается, что конвейерные умножитель и сумматор состоят из четырех сегментов, которые вначале инициализируются нулем, поэтому в течение первых восьми циклов, пока оба конвейера не заполнятся, на выходе сумматора будет 0. Пары (Аi, Вi) подаются на вход умножителя и перемножаются в темпе одна пара за цикл. После первых четырех циклов произведения начинают суммироваться с данными, поступающими с выхода сумматора. В течение следующих четырех циклов на вход сумматора поступают суммы произведений из умножителя с нулем. К концу восьмого цикла в сегментах сумматора находятся четыре первых произведения A1B1, ..., А4В4, а в сегментах умножителя — следующие четыре произведения: А5В5,..., A8B8. К началу девятого цикла на выходе сумматора будет А1В1, а на выходе умножителя — А5В5. Таким образом, девятый цикл начнется со сложения в сумматоре А1В1 и А5В5. Десятый цикл начнется со сложения А2В2 + A6B6 и т. д. Процесс суммирования в четырех секциях выглядит так:
Когда больше не остается членов для сложения, система заносит в умножитель четыре нуля. Конвейер сумматора в своих четырех сегментах при этом будет содержать четыре скалярных произведения, соответствующие четырем суммам, приведенным в четырех строках показанного выше уравнения. Далее четыре частичных суммы складываются для получения окончательного результата.
Программа для вычисления скалярного произведения векторов А и В, хранящихся в двух областях памяти с начальными адресами adrA и adrB, соответственно может выглядеть так:

Векторные и векторно-конвейерные вычислительныесистемы 5 5 9
Первые две векторные команды V_load загружают векторы из памяти в векторные регистры VA и VB. Векторная команда умножения V_multiply вычисляет произведение для всех пар одноименных элементов векторов и записывает полученный вектор в векторный регистр Vc.
Важнымэлементомлюбоговекторногопроцессора(ВП)являетсярегистрдлины вектора. Этот регистр определяет, сколько элементов фактически содержит обрабатываемый в данный момент вектор, то есть сколько индивидуальных операций с элементами нужно сделать. В некоторых ВП присутствует также регистр максимальной длины вектора, определяющий максимальное число элементов вектора, которое может быть одновременно обработано аппаратурой процессора. Этот регистр используется при разделении очень длинных векторов на сегменты, длина которых соответствует максимальному числу элементов, обрабатываемых аппаратурой за один прием.
Достаточно часто приходится выполнять такие операции, в которых должны участвовать не все элементы векторов. Векторный процессор обеспечивает данный режим с помощьюрегистре маски вектора. В этом регистре каждому элементу вектора соответствует один бит. Установка бита в единицу разрешает запись соответствующего элемента вектора результата в выходной векторный регистр, а сброс в ноль — запрещает.
Как уже упоминалось, элементы векторов в памяти расположены регулярно, и при выполнении векторных операций достаточно указать значение шага по индексу. Существуют, однако, случаи, когда необходимо обрабатывать только ненулевые элементы векторов. Для поддержки подобных операций в системе команд ВПпредусмотреныоперацииупаковки/распаковки(gather/scatter). Операция упаковки формирует вектор, содержащий только ненулевые элементы исходного вектора, а операция распаковки производитобратное преобразование. Обе этих задачи векторный процессор решает с помощью вектора индексов, для хранения которого используетсярегистрвектораиндексов,поструктуреаналогичныйрегиструмаски. В векторе индексов каждому элементу исходного вектора соответствует один бит. Нулевое значение бита свидетельствует, что соответствующий элемент исходного вектора равен нулю.
Использование векторных команд окупается благодаря двум качествам. Вопервых, вместо многократной выборки одних и тех же команд достаточно произвести выборку только одной векторной команды, что позволяет сократить издержки за счет устройства управления и уменьшить требования к пропускной способности памяти. Во-вторых, векторная командаобеспечивает процессор упорядоченными данными. Когда инициируется векторная команда, ВС знает, что ей нужно извлечь п пар операндов, расположенных в памяти регулярным образом. Таким образом, процессор может указать памяти на необходимость начать извлечение таких пар. Если используется память с чередованием адресов, эти пары могут быть получены со скоростью одной пары за цикл процессора и направлены для обработки в конвейеризированный функциональный блок. При отсутствии чередова-

5 6 0 Глава 13. Вычислительные системы класса SIMD
ния адресов или других средств извлечения операндов с высокой скоростью преимущества обработки векторов существенно снижаются.
Структуры типа «память-память» и «регистр-регистр»
Принципиальное различие архитектур векторных процессоров проявляется в том, каким образом осуществляется доступ к операндам. При организации «памятьпамять* элементы векторов поочередно извлекаются из памяти и сразу же направляются в функциональный блок. По мере обработки получающиеся элементы вектора результата сразу же заносятся в память. В архитектуре типа «регистр-ре- гистр»операндысначалазагружаютсяввекторныерегистры,каждыйизкоторых может хранить сегмент вектора, например 64 элемента. Векторная операция реализуется путем извлечения операндов из векторных регистров и занесения результата в векторные регистры.
Преимущество ВП с режимом -«память-память» состоит в возможности обработки длинных векторов, в то время как в процессорах типа -«регистр-регистр» приходится разбиватьдлинныевекторынасегментыфиксированнойдлины. К сожалению, за гибкость режима «память-память» приходится расплачиваться относительно большими издержками, известными как время запуска, представляющее собой временной интервал между инициализацией команды и моментом, когда первый результат появится на выходе конвейера. Большое время запуска в процессорах типа -«память-память» обусловлено скоростью доступа к памяти, которая намного больше скорости доступа к внутреннему регистру. Однако когда конвейер заполнен, результат формируется в каждом цикле. Модель времени работы векторного процессора имеет вид:
где s — времязапуска, — константа, зависящая от команды (обычно 1/2,1 или 2) и N— длина вектора.
— константа, зависящая от команды (обычно 1/2,1 или 2) и N— длина вектора.
Архитектура типа «память-память» реализована в векторно-конвейерных вычислительных системах Advanced Scientific Computer фирмы Texas Instruments Inc., семействе вычислительных систем фирмы Control Data Corporation, прежде все го, Star 100, серии Cyber 200 и ВС типа ЕТА-10. Все эти вычислительные системы появились в середине 70-х прошлого века последлительного цикла разработки, но к середине 80-х годов от них отказались. Причиной послужило слишком большое время запуска — порядка 100 циклов процессора. Этоозначает, что операции с короткими векторами выполняются очень неэффективно, и даже при длине векторов в 100 элементов процессор достигал только половины потенциальной производительности.
В вычислительных системах типа «регистр-регистр» векторы имеют сравнительно небольшую длину (в ВС семейства Cray — 64), но время запуска значительно меньше чем в случае «память-память». Этот тип векторных систем гораздо более эффективен при обработке коротких векторов, но при операциях над длинными векторами векторные регистры должны загружаться сегментами несколько раз. В настоящее время ВП типа «регистр-регистр» доминируют на компьютерном рынке. Это вычислительные системы фирмы Cray Research Inc., в частности

5 6 2 Глава 13. Вычислительные системы класса SIMD
векторов из этих регистров подаются на первую ступень конвейера 1. На следующем такте на конвейер 0 подаются вторые элементы из V1 и V2 а на конвейер 2 - третьи элементы и т. д. Аналогично происходит распределение результатов в выходном векторном регистре V3. В итоге функциональный блок при максимальной загрузке в каждом такте выдает не один результат, а два. Добавим, что в скалярных операциях работает только конвейер 0.
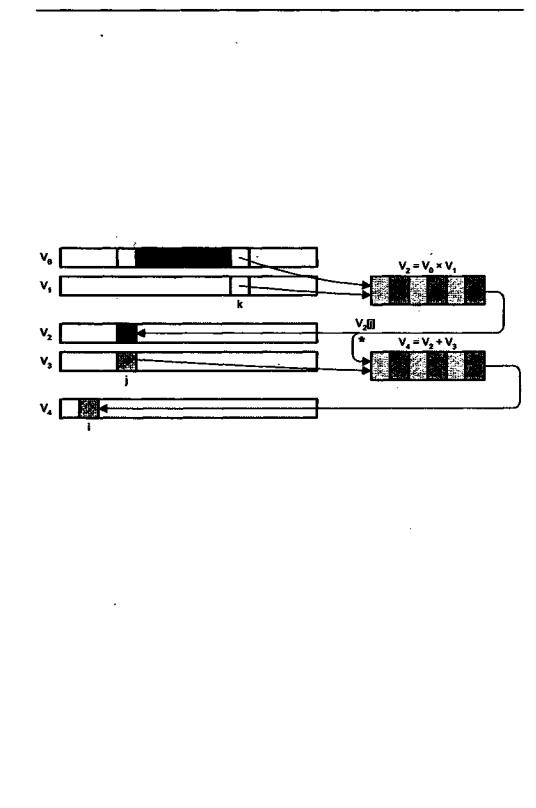
Интересной особенностью некоторых ВП типа «регистр-регистр», например ВС фирмы Cray Research Inc., является так называемое сцепление векторов (vector chaining или vector linking), когда ВР результата одной векторной операции используется в качестве входного регистра для последующей векторной операции. Для примера рассмотрим последовательностьиз двух векторных команд, предполагая, что длина векторов равна 64: V2 =Vo x V1, V4 =V2 + V3.
Рис. 13,9.Сцеплениевекторов
Результат первой команды служит операндом для второй. Напомним, что поскольку команды являются векторными, первая из них должна послать в конвейерный умножитель до 64 пар чисел. Примерно в середине выполнения команды складывается ситуация, когда несколько начальных элементов вектора V2 будут уже содержать недавно вычисленные произведения; часть элементов V2 все еще будет находиться в конвейере, а оставшиеся элементы операндов Vo и V1 еще остаются во входных векторных регистрах, ожидая загрузки в конвейер. Такая ситуация показана на рис. 13.9, где элементы векторов Vo и V1, находящиеся в конвейерном умножителе,имеют темную закраску. В этот момент система извлекает элементы V0[k] и V1[k] с тем, чтобы направить их на первую ступень конвейера, в то время как V2[j] покидает конвейер. Сцепление векторов иллюстрирует линия, обозначенная звездочкой. Одновременно с занесением V2[j] в ВР этот элемент направляется и в конвейерный сумматор, куда также подается и элемент V3[j]. Как видно из рисунка, выполнениевторойкомандыможетначатьсядозавершения первой,и поскольку одновременно выполняются две команды, процессор формирует два результата за цикл (V4[i] и V2[j]) вместо одного. Без сцепления векторов пиковая производительность Сгау-1 была бы 80 MFLOPS (один полный конвейер производит результат каждые 12,5 нc). При сцеплении трех конвейеров теоретический пик производительности — 240 MFLOPS. В принципе сцепление векторов можно

Матричные вычислительные системы 5 6 3
реализовать и в векторных процессорах типа «память-память», но для этого необходимо повысить пропускную способность памяти. Без сцепления необходимы три «канала»: два для входных потоков операндов и один — для потока результата. При использовании сцепления требуется обеспечить пять каналов: три входных и два выходных.
Завершая обсуждение векторных и векторно-конвейерных ВС, следует отметить, что с середины 90-х годов прошлого века этот вид ВС стал уступать свои позиции другим более технологичным видам систем. Тем не менее одна из последних разработок корпорации NEC (2002 год) — вычислительная система «Модель Земли» (The Earth Simulator), — являющаяся на сегодняшний момент самой производительной вычислительной системой в классе, по сути представляет собой векторно-конвейерную ВС. Система включает в себя 640 вычислительных узлов по 8 векторных процессоров в каждом. Пиковая производительность суперкомпьютера превышает 40 TFLOPS.
Матричные вычислительные системы
Назначение матричных вычислительных систем во многом схоже с назначением векторных ВС — обработка больших массивов данных. В основе матричных систем лежит матричный процессор (array processor), состоящий из регулярного массива процессорных элементов (ПЭ). Организация систем подобного типа на первый взгляд достаточно проста. Они имеют общее управляющее устройство, генерирующее поток команд, и большое число ПЭ, работающих параллельно и обрабатывающих каждый свой поток данных. Однако на практике, чтобы обеспечить достаточную эффективность системы при решении широкого круга задач, необходимо организовать связи между процессорными элементами так, чтобы наиболее полно загрузить процессоры работой. Именно характер связей между ПЭ и определяет разные свойства системы. Ранее уже отмечалось, что подобная схема применима и для векторных вычислений.
Между матричными и векторными системами есть существенная разница. Матричный процессор интегрирует множество идентичных функциональных блоков (ФБ), логически объединенных в матрицу и работающих в SIMD-стиле. Не столь существенно, как конструктивно реализована матрица процессорных элементов — наедином кристаллеили нанескольких. Важенсам принцип — ФБлогическискомпонованы в матрицу и работают синхронно, то есть присутствует только один поток команд для всех. Векторный процессор имеет встроенные команды для обработки векторов данных, что позволяет эффективно загрузить конвейер из функциональных блоков, В свою очередь, векторные процессоры проще использовать, потому что команды для обработки векторов — это более удобная для человека модель • программирования, чемSIMD.
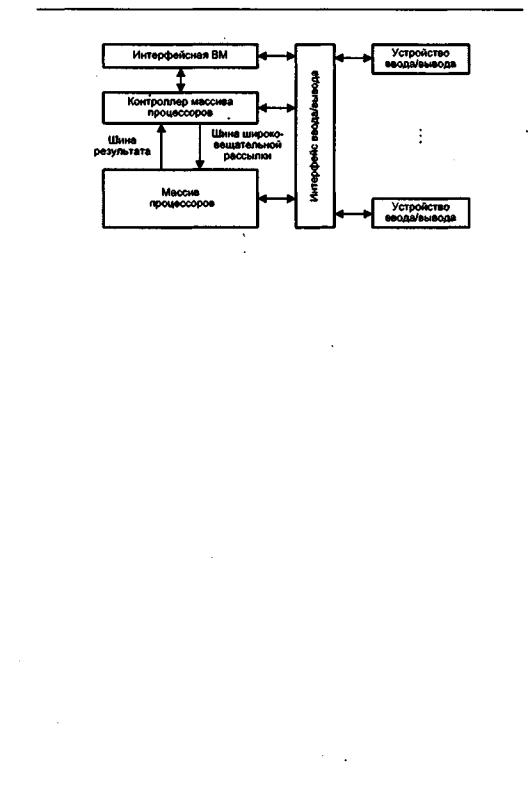
Структуру матричной вычислительной системы можно представить в виде, показанном на рис. 13.10 [234].
Собственно параллельная обработка множественных элементов данных осуществляется массивом процессоров (МПр). Единый поток команд, управляющий обработкой данных в массиве процессоров, генерируется контроллером массива
5 6 4 Глава 13. Вычислительные системы класса SIMD
Рис. 13.10. Обобщенная модель матричной SIMD-системы
процессоров (КМП). КМП выполняет последовательный программный код, реализует операции условного и безусловного переходов, транслирует в МПр команды, данные и сигналы управления. Команды обрабатываются процессорами в режиме жесткой синхронизации. Сигналы управления используются для синхронизации команд и пересылок, а также для управления процессом вычислений, в частности определяют, какие процессоры массива должны выполнять операцию, а какие — нет. Команды, данные и сигналы управления передаются из КМП в массив процессоров по шине широковещательной рассылки. Поскольку выполнение операций условного перехода зависит от результатов вычислений, результаты обработки данных в массиве процессоров транслируются в КМП, проходя по шине результата.
Для обеспечения пользователя удобным интерфейсом при создании и отладке программ в состав подобных ВС обычно включают интерфейсную ВМ (front-end computer). В роли такой ВМ выступает универсальная вычислительная машина, на которуюдополнительно возлагается задача загрузки программ и данных в КМП. Кроме того, загрузка программ и данных в КМП может производиться и напрямуюсустройствввода/вывода,напримерсмагнитныхдисков.ПослезагрузкиКМП приступает к выполнению программы, транслируя в МПр по широковещательной шине соответствующие SIMD-команды. .
Рассматривая массив процессоров, следует учитывать, что для хранения множественных наборов данных в нем, помимо множества процессоров, должно присутствовать и множество модулей памяти. Кроме того, в массиве должна быть реализована сеть взаимосвязей, как между процессорами, так и между процессорами и модулями памяти. Таким образом, под термином массив процессоров понимают блок, состоящий из процессоров, модулей памяти и сети соединений.
Дополнительную гибкость при работе с рассматриваемой системой обеспечивает механизм маскирования, позволяющий привлекать к участию в операциях лишь определенное подмножество из входящих в массив процессоров. Маскированиереализуется как настадии компиляции,таки наэтапе выполнения, приэтом процессоры, исключенные путем установки в ноль соответствующих битов маски, во время выполнения команды простаивают.