

Линейная регрессия
Предполагается,
что
между
переменными
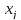 ,
j
=
1,
.
.
.
,
n
существует
линейная
зависимость:
,
j
=
1,
.
.
.
,
n
существует
линейная
зависимость:
(1.1)
 j=1
j=1
где αj , j = 1, . . . , n, β (угловые коэффициенты и свободный член) — параметры (коэффициенты) регрессии (их истинные значения), ε — случайная ошибка; или в векторной форме:
xα = β + ε, (1.2)
где x и α — соответственно вектор-строка переменных и вектор-столбец пара- метров регрессии.
Регрессия
называется
линейной,
если
ее
уравнение
линейно
относительно
параметров
регрессии,
а
не
переменных.
Поэтому
предполагается,
что
 ,
j
=
1,
.
.
.
,
n,
могут
являться
результатом
каких-либо
функциональных
преобразований
исходных
значений
переменных.
,
j
=
1,
.
.
.
,
n,
могут
являться
результатом
каких-либо
функциональных
преобразований
исходных
значений
переменных.
Для
получения
оценок
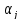 ,
j
=
1,
.
.
.
,
n,
b
,
e,
соответственно,
параметров
регрессии
,
j
=
1,
.
.
.
,
n,
b
,
e,
соответственно,
параметров
регрессии
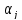 ,
j
=
1,
.
.
.
,
n,
β
и
случайных
ошибок
ε
используется
N
наблюдений
за
переменными
x,
i
=
1,
.
.
.
,
N
,
которые
образуют
матрицу
наблюдений
X
размерности
N
×
n
(столбцы
—
переменные,
строки
—
наблюдения).
Уравнение
регрессии
по
наблюдениям
записывается
следующим
образом:
,
j
=
1,
.
.
.
,
n,
β
и
случайных
ошибок
ε
используется
N
наблюдений
за
переменными
x,
i
=
1,
.
.
.
,
N
,
которые
образуют
матрицу
наблюдений
X
размерности
N
×
n
(столбцы
—
переменные,
строки
—
наблюдения).
Уравнение
регрессии
по
наблюдениям
записывается
следующим
образом:
Xα = 1N β + ε, (1.3)
где, как и прежде, 1N — вектор-столбец размерности N , состоящий из единиц, ε — вектор-столбец размерности N случайных ошибок по наблюдениям; или в оценках:
Xa = 1N b + e. (6.4)
Собственно уравнение регрессии (без случайных ошибок) xα = β или xa = b определяет, соответственно, истинную или расчетную гиперплоскость (линию, плоскость,...) регрессии.
.
.
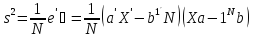
Из равенства нулю производной остаточной дисперсии по свободному члену b
следует, что
x¯a = b (1.5)
и
t
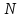 e
=
0. (1.6)
e
=
0. (1.6)
Действительно,
∂s2 2
−
1![]()
![]()
∂b N N
(Xa − 1N b) =
− 2 (x¯a − b) ,
2
N![]()
Вторая производная по b равна 2, т.е. в найденной точке достигается минимум.
Здесь и ниже используются следующие правила матричной записи результатов диф- ференцирования линейных и квадратичных форм.
Пусть x, a — вектор-столбцы, α — скаляр, а M — симметричная матрица. То- гда:
dxα
=
x, ∂xra
=
a, ∂xrM
=
M, ∂xrMx
=
2M
x.![]()
![]()
![]()
![]()
dα ∂x ∂x ∂x
2.2. Простая регрессия
Этот результат означает, что точка средних значений переменных лежит на расчетной гиперплоскости регрессии.
В результате подстановки выражения b из (1.5) через a в (1.4) получается другая форма записи уравнения регрессии:
Xˆ a = e, (1.7)
где Xˆ = X − 1N x¯ — матрица центрированных значений наблюдений.
(1.3, 1.4) — исходная, (1.7) — сокращенная запись уравнения регрессии. Минимизация остаточной дисперсии по a без дополнительных условий приве-
дет к тривиальному результату: a = 0. Чтобы получать нетривиальные решения,
на вектор параметров α и их оценок a необходимо наложить некоторые огра- ничения. В зависимости от формы этих ограничений возникает регрессия разного вида — простая или ортогональная.
1.2. Простая регрессия
В случае, когда ограничения на вектор a (α) имеют вид aj = 1 ( αj = 1), возникают простые регрессии. В таких регрессиях в левой части уравнения оста- ется одна переменная (в данном случае j-я), а остальные переменные переносятся в правую часть, и уравнение в исходной форме приобретает вид (регрессия j-й переменной по остальным, j-я регрессия):
Xj = X−j a−j + 1N bj + ej , (1.8) где Xj — вектор-столбец наблюдений за j-й переменной — объясняемой,
X−j — матрица наблюдений размерности N × (n − 1) за остальными перемен- ными — объясняющими (композиция Xj и X−j образует матрицу X ), a−j — вектор a без j-го элемента (равного 1), взятый с обратным знаком (компози- ция 1 и −a−j образует вектор a), bj и ej — соответственно свободный член и вектор-столбец остатков в j-й регрессии. В сокращенной форме:
Xˆj = Xˆ−j a−j + ej . (1.9)
В таких регрессиях ошибки eij — расстояния от гиперплоскости регрессии до точек облака наблюдения — измеряются параллельно оси xj .
Остаточная дисперсия приобретает следующую форму:
s2 1 1
ˆ
ˆ ˆ ˆ
ej = N et ej = N
Xt − at Xt
Xj − X−j a−j
. (6.10)
j j −j −j![]()
![]()
Из равенства нулю ее производных по параметрам a−j определяется, что
−j j −j
−
где M−j =
ˆ t
1
N
X![]()
−j — матрица ковариации объясняющих переменных x−j
Xˆ
−j N
Xˆj
— вектор-столбец ковариации объясняющих пе-
−j
ременных с объясняемой переменной xj ; и
cov
(X−j
,
ej
)
=
N
Xˆ
t
−j![]()
ej = 0. (1.12)
Действительно,
∂s2 2
ˆ ˆ
2
ej
![]()
∂a−j
= Xˆ r
−
Xj − X−j
a−j
=
Xˆ r
− N
−j ej .
Кроме того, очевидно, что матрица вторых производных равна 2M−j , и она, как всякая ковариационная матрица, положительно полуопределена. Следовательно, в найденной точке достигается минимум остаточной дисперсии.
Справедливость утверждения о том, что любая матрица ковариации (теоретическая или ее оценка) положительно полуопределена, а если переменные линейно незави- симы, то — положительно определена, можно доказать в общем случае.
Пусть x — случайный вектор-столбец с нулевым математическим ожиданием. Его
теоретическая матрица ковариации по определению равна E (xxr). Пусть ξ ƒ= 0 — детерминированный вектор-столбец. Квадратичная форма
(
т.е. матрица положительно полуопределена. Если не существует такого ξ ƒ= 0, что
ξrx = 0, т.е. переменные вектора x линейно не зависят друг от друга, то неравенство
выполняется строго, и соответствующая матрица положительно определена.
Пусть X — матрица N наблюдений за переменными x. Оценкой матрицы ко-
вариации этих переменных является
1
1 Xˆ rXˆ . Квадратичная форма
N![]()
1 ξrXˆ rXˆ ξ =
N![]()
= uru
“
0,
где
u
=
Xˆ
ξ,
т.е.
матрица
положительно
полуопределена.
Если
не![]()
N
существует такого ξ ƒ= 0, что Xˆ ξ = 0, т.е. переменные x линейно не зависят друг от друга, то неравенство выполняется строго, и соответствующая матрица положи- тельно определена.
Оператор МНК-оценивания образуется соотношениями (6.11) и (6.5), которые в данном случае записываются следующим образом:
bj = x¯j − x¯−j a−j (6.13)
(соотношения МНК-оценивания (4.37), данные в пункте 4.2 без доказательства, являются частным случаем этого оператора).
Уравнения
m−j = M−j a−j , (6.14)
решение которых дает первую часть оператора МНК-оценивания (6.11), называ- ется системой нормальных уравнений.
МНК-оценки остатков имеют нулевую среднюю (6.6) и не коррелированы (ор- тогональны) с объясняющими переменными уравнения (6.12).
Систему нормальных уравнений можно вывести, используя иную логику. Если
X
j
−
1
и разделить на N ,
−j![]()
ej , из которого получается искомая
система при требованиях
e¯j = 0 и cov(X−j , ej ) = 0, следующих из полученных
свойств МНК-оценок остатков.
ZˆtXˆ
1
1
ет условие
ZˆtXˆj =
N![]()
1
N −j
a−j
+![]()
Zˆtej , из которого — после отбрасывания
N![]()
второго члена правой части в силу сделанных предположений — следует система
нормальных уравнений метода инструментальных переменных:
mz
z
z
, (6.15)
j
−
−j
−j −j
= cov (z, x−j ).
Значения j-й (объясняемой) переменной, лежащие на гиперплоскости регрес- сии, называются расчетными (по модели регрессии):
Xc
Xˆ
c ˆ
Их дисперсия называется объясненной (дисперсия, объясненная регрессией) и может быть представлена в различных вариантах:
s2 1 c ˆ c (6.17)
(6.11) 1
qj = N Xˆ t X
= at
M−j a−j
= at
m−j = mt
a−j = mt (6.18)
Если раскрыть скобки в выражении остаточной дисперсии (6.10) и прове-
s2
= s2 − s2 ,
где
j — дисперсия j-й (объясняемой) переменной, или
ej j qj
s2 2 2
j = sqj + sej . (6.19)
Это — дисперсионное тождество, показывающее разложение общей диспер- сии объясняемой переменной на две части — объясненную (регрессией) и оста- точную.
Доля объясненной дисперсии в общей называется коэффициентом детерми- нации:
s
R2
s
=
j 2![]()
j
s2
ej
s![]()
j
который является показателем точности аппроксимации исходных значений объ- ясняемой переменной гиперплоскостью регрессии (объясняющими переменными). Он является квадратом коэффициента множественной корреляции между объ- ясняемой и объясняющими переменными rj,−j , который, по определению, равен
коэффициенту парной корреляции между исходными и расчетными значениями
объясняемой переменной:
cov xj , xc
Xˆ t Xˆ c
Xˆ t Xˆ a
j
1 j j (6.17) 1 j − j − j
rj,−j =
sj sqj
= =
N sj sqj N
=
sj sqj
s
=
.![]()
sj sqj
qj
![]()
sj sqj
(6.20)
j
R2.
Из (6.19) следует, что коэффициент корреляции по абсолютной величине не пре- вышает единицы.
Эти утверждения, начиная с (6.16), обобщают положения, представленные в конце пункта 4.2.
Композиция 1 и −aj обозначается a(j) и является одной из оценок вектора α. Всего таких оценок имеется n — по числу простых регрессий, в левой части уравнения которых по очереди остаются переменные xj , j = 1, . . . , n. Эти вектор- столбцы образуют матрицу A. По построению ее диагональные элементы равны единице ( ajj = 1 вслед за aj (j) = 1).
Все эти оценки в общем случае различны, т.е. одну из другой нельзя получить алгебраическим преобразованием соответствующих уравнений регрессии:
Это утверждение доказывалось в пункте 4.2 при n = 2. В данном случае спра- ведливо утверждение, что соотношение (6.21) может (при некоторых j, jt ) вы- полняться как равенство в том и только том случае, если среди переменных xj , j = 1, . . . , n существуют линейно зависимые.
Достаточность этого утверждения очевидна. Действительно, пусть переменные неко- торого подмножества J линейно зависимы, т.е. существует такой вектор ξ, в кото-
ром
ξj
ƒ=
0 при
j
∈
J
и
ξj
=
0 при
j
∈/
J
,
и
Xˆ ξ = 0. Тогда для любого j ∈ J
ξj![]()
соотношения (6.21) выполняются как равенства.
Для доказательства необходимости утверждения предполагается, что существует такой ξ ƒ= 0, что
Aξ = 0 (6.22)
(т.е., в частности, некоторые соотношения из (6.21) выполняются как равенства).
N![]()
ej
e
где S2 — диагональная матрица .s2 ..
e ej
e
ej
= 0, т.е. переменные xj линейно
зависят друг от друга.
Что и требовалось доказать.
Все возможные геометрические иллюстрации простых регрессий в простран- стве наблюдений и переменных даны в пункте 4.2.