

Правила записи рамочных логических выражений
Увеличение длины идентификаторов приводит к тому, что традиционная горизонтальная запись логических выражений становится невозможной. В связи с этим применяется вертикальная запись, пример которой показан на рис. 80. Вертикальный логический текст на языкеДРАКОНпишут в соответствии со следующими правилами.
В иконе “действие” размещают один оператор присваивания.
В верхней строке пишут идентификатор логической переменной и знак присваивания.
Ниже пишут логическое выражение, причем каждая конъюнкция заключается в прямоугольную рамку.
Для операций И,ИЛИ,НЕиспользуют обозначения &,ИЛИ,┐соответственно.
Используют идентификаторы длиной до 32 символов.
Первые символы всех идентификаторов располагают на одной вертикали.
Знак отрицания ┐пишут слева от идентификатора.
Все знаки отрицания (если они есть) помещают на одной вертикали.
Знаки конъюнкции & записывают справа от идентификатора.
Все знаки конъюнкции пишут на одной вертикали.
Вертикальные линии рамок располагают на одной вертикали.
Знаки = и ИЛИпомещают на одной вертикали.
Как построить эргономичный логический текст?
Ранее мы пришли к выводу, что алгоритм на рис. 79 является эргономически неудачным. Каким образом можно его исправить? Вопрос отнюдь не простой. По-видимому, в разных ситуациях он может приводить к разным ответам. В связи с этим изложенные ниже соображения и советы имеют не обязательный, а всего лишь рекомендательный характер. Их нужно рассматривать как один из возможных способов решения проблемы.
В иконе “вопрос” не следует записывать логическое выражение, в особенности сложное. Вместо него рекомендуется поместить один-единственный идентификатор, содержащий ясную и четкую словесную формулировку главного вопроса.
В общем случае указанный идентификатор может оказаться неопределенным. Чтобы исключить эту неприятность, необходимо заблаговременно присвоить ему нужное значение. Для этого существуют два метода: рамочный и визуальный.
В рамочном методе используется рамочное логическое выражение, записанное в иконе “действие”. Производится вычисление рамочного выражения, результат присваивается идентификатору главного вопроса (рис. 80).
В визуальном методе применяется визуальное логическое выражение и два оператора “Установить признак” и “Снять признак”, записанные в иконах “полка”.
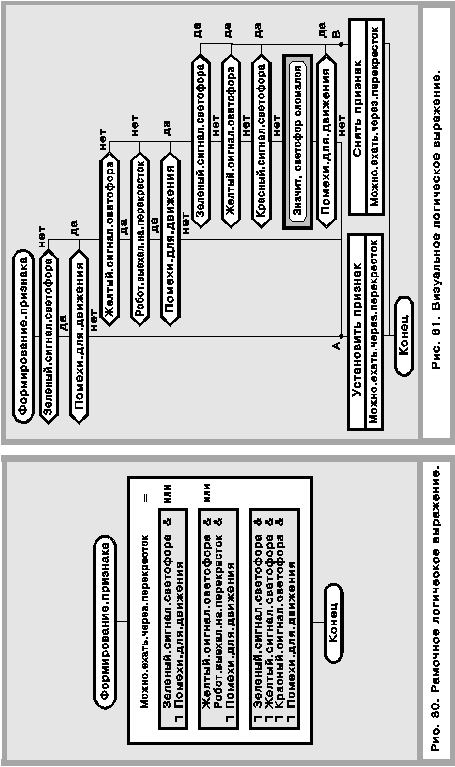
В отличие от рамочного при визуальном методе вычисление логического выражения как таковое отсутствует. Визуальное выражение разветвляет процесс и приводит его в одну из двух точек (А или В на рис. 81). В первой точке выполняется оператор “Установить признак”, во второй — “Снять признак”. Алгоритмы на рис. 80 и 81 эквивалентны.
Инструментальные программы языка ДРАКОНдолжны обеспечить автоматический перевод рамочного алгоритма (рис. 80) в визуальный(рис. 81) и наоборот. Предоставление такой услуги пользователю создает для него дополнительный интеллектуально-эргономический комфорт, позволяет сравнить две формы представления логических знаний и выбрать ту, которая ему больше по душе. Поскольку вкусы автора алгоритма и его читателей могут отличаться, каждый из них может получить листинг (чертеж) программы в том виде, который лично ему больше нравится, реализуя тем самым свое право на индивидуальное предпочтение той или иной формы представления знаний.
Оптимальная длина формального смыслового идентификатора составляет примерно 32 символа. Имеется в виду, что инструментальные программы осуществляют обработку 32-байтового поля идентификатора. Желательно, чтобы конкретные идентификаторы в зависимости от сложности понятия имели длину не менее 25 и не более 32 символов. Чтобы исключить ошибки при ручном вводе столь длинных идентификаторов в компьютер, целесообразно ввести запрет повторного ввода. Это значит, что идентификатор вводится в систему только один раз и запоминается в базе данных. При необходимости повторного ввода осуществляется копирование из базы данных. Такой способ требует наличия специальных инструментальных средств, но гарантирует идентичность всех копий одного и того же идентификатора.
Вывод об оптимальности 32-символьных идентификаторов согласуется с анализом истории развития языков программирования, который обнаруживает отчетливую тенденцию: от абстрактных кодов и имен к 8-символьным мнемоническим именам, а затем — к 32-символьным смысловым идентификаторам. Вместе с тем многие программисты, следуя устоявшимся привычкам, “застряли” на этапе 8-символьных имен, так что опыт использования новых возможностей, связанных с разрешением использовать 32 символа, пока еще относительно невелик. Междутем, эргономические перспективы, открывающиеся с увеличением длины до 32 символов, обещают существенно изменить наши прежние представления и привычки, так как благодаря этому замечательному нововведению язык формальных идентификаторов по своей доходчивости значительно приближается к естественному человеческому языку, что отчетливо видно на рис. 80 и 81. В самом деле, множество 32-символьных идентификаторов образует весьма выразительный, хотя и своеобразный язык, законы и правила оптимизации которого еще предстоит открыть, обсудить и подвергнуть экспериментальной проверке.
Специальные обозначения для значений логических переменных как принадлежность языка программирования — это анахронизм, который следует исключить из всех языков как совершенно не нужное и даже вредное “архитектурное излишество”. Чтобы оправдать этот вывод, сравним два выражения в условном операторе:
Если (Норма 1 = 1) & (Норма 2 = 1) & (Авария = 0), то... (10)
Если Норма 1 & Норма 2 & ┐Авария, то.... (11)
Формула (10) читается так:
|
|
Если признак “Норма 1” равен единице и признак “Норма 2” равен единице и признак “Авария” равен нулю, то… |
|
(10а) |
Формула (11) читается так:
|
|
Если есть признак “Норма 1” и есть признак “Норма 2” и нет признака “Авария”, то… |
|
(11а) |
Фраза (11а) по своему лексическому строю соответствует обычным речевым оборотам, которыми пользуются специалисты предметной области, не являющиеся программистами. Она точно отражает суть дела и понятна всем работникам, в то время как фраза (10а) содержит искусственные и нарочитые вкрапления “равен единице” и “равен нулю”, появление которых неоправданно удлиняет текст и разрушительно действует на процесс восприятия, делая предложение непонятным для всех, кроме программистов.
Выводы
Точкой роста современной науки являются междисциплинарные исследования, в частности на стыке логики и эргономики.
С
 егодня,
когда критической проблемой являются
не машинные, а человеческие ресурсы,
традиционные методы записи логических
выражений следует признать во
многом устаревшими, ибо они не учитывают
эргономических соображений.
егодня,
когда критической проблемой являются
не машинные, а человеческие ресурсы,
традиционные методы записи логических
выражений следует признать во
многом устаревшими, ибо они не учитывают
эргономических соображений.Предложен двухэтапный метод эргономизации логических выражений. На первом этапе производится разделение логических записей на две части, из которых одна подлежит визуализации, а другая сохраняется в текстовом виде. Второй этап — эргономизация обеих частей: визуальной и текстовой.
Эргономизация текстовой части включает, в частности, следующие приемы:
оптимизацию длины и правил записи идентификаторов;
выбор альтернативы: логическое выражение или идентификатор главного вопроса;
исключение обозначений для значений логических переменных;
сравнительный анализ визуальной и рамочной форм записи и выбор одной из них.