

43. Индекс на основе битовых карт. Структура листового блока. Операция добавления элемента.
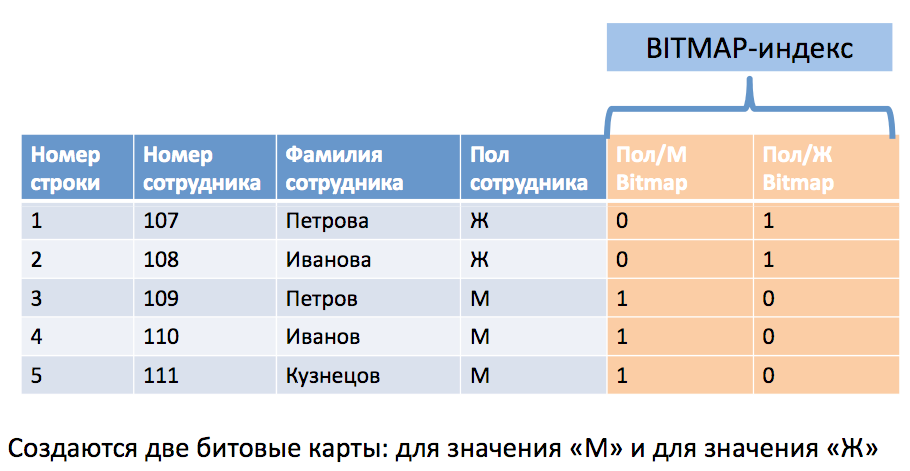
Индексы на основе битовых карт (bitmapped indexes) разработаны для ответов на запросы, которые затрагивают столбцы с небольшим числом возможных значений, каждое из которых потенциально соответствует большому числу строк. Число возможных значений для столбца называется количеством элементов (cardinality). В отличие от иерархических индексов, хранящих указатели на строки, используя идентификаторы строк (rowids), индекс на основе битовых карт хранит для каждого возможного значения столбца битовую карту. Битовая карта для каждого из возможных значений имеет столько битов, сколько строк есть в таблице. Бит устанавливается, если соответствующая строка имеет данное значение.
Индексы на основе битовых карт BITMAP индексы: Используются для колонок с небольшим количеством уникальных значений (низкая кардинальность); Чаще всего используются в хранилищах данных и системах DSS; Используются в схеме типа «звезда»; Должно быть минимальное количество DML- операций ; Хранят указатели на множество строк, соответствующих одному значению ключа индекса. Индексы на основе битовых карт по нескольким столбцам можно эффективно комбинировать, используя операторы AND OR NOT.
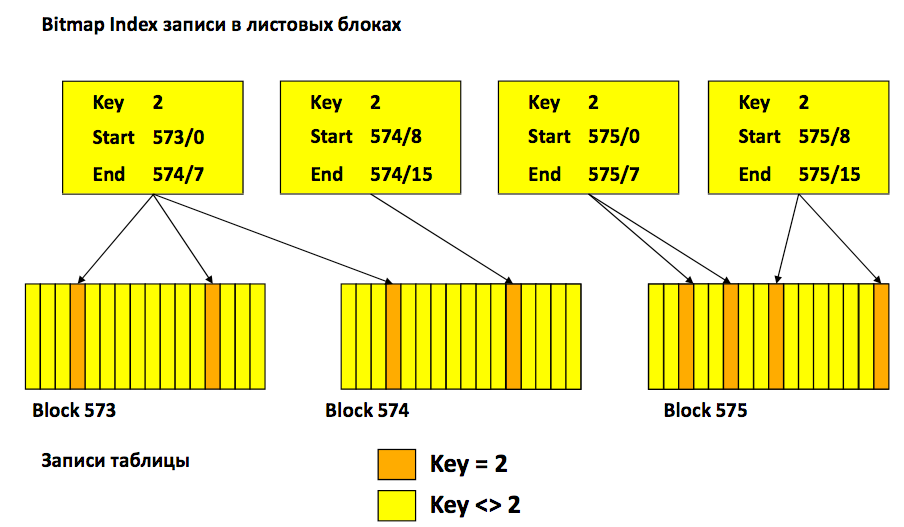
Структура листового блока: 1) Каждое значение bitmap индекса представлено одной или несколькими битовыми картами 2) Каждая битовая карта указывает на диапазон RowID 3) Каждая запись в листовом блоке имеет структуру:

4) Составной индекс будет иметь дополнительные ключевые колонки в структуре листового блока 5)Промежуточные блоки соответствуют внутренним узлам B+ дерева.



44. Индекс на основе битовых карт. Операция обновления элемента. Блокировка записей.
Раскрыто в вопросе 42 нижняя половина страницы, в инете присутствует информация узкоспециализированная по работе в Оракле, у шустовой более ничего нет
45. Методы доступа к данным. Основные операции выполнения sql-выражения.
IndexUniqueScan Метод для поиска одного ключа с помощью уникального индекса. Всегда возвращает одно значение.
IndexRangeScan Метод доступа к нескольким значениям колонки. Выполняется сканирование диапазона индекса. Применятся при использовании операторов ><<>>= <= between
IndexFullScan Метод доступа чтения всех записей индекса, исключает сортировку. Является альтернативой полного сканирования таблицы для получения отсортированных данных в соответствии с упорядоченностью индекса
IndexFastFullScan Метод доступа чтения всех записей индекса не требующих сортировку. Является альтернативой полного сканирования таблицы для получения неотсортированных данных, т.к. возможно параллельное чтение данных.
IndexSkipScan Метод доступа путем разделения составного индекса на логические части. БД определяет количество таких логических частей (subindexes) по числу неповторяющихся значений (distinct values) лидирующего столбца составного индекса. И если таких subindexes будет мало, оптимизатор предпочтет именно IndexSkipScan. Но если лидирующий столбец имеет много различных значений, то оптимизатор предпочтет TABLE FULL SCAN.
Пример: select emp_id,address from employees; План запроса:
|
Gender |
Emp_id |
|
Ж |
98 |
|
Ж |
100 |
|
М |
101 |
|
М |
102 |
|
М |
103 |
|
М |
104 |
1. INDEX SKIP SCAN BE_IX
Сканирование таблицы будет произведено для части Ж и М отдельно.