

1.3 Приклад статистичного аналізу випадкової величини
В таблиці 1.4 наведені зібрані за два місяці статистичні дані обсягу поставок металопрокату з центральної бази постачання споживачам.
Таблиця 1.4 – Вихідні статистичні дані
№ спостереження |
Величина щомісячної поставки Q (m) |
№ спостереження |
Величина щомісячної поставки Q (m) |
||
місяці |
місяці |
||||
1 |
2 |
1 |
2 |
||
1 2 3 4 5 6 7 8 9 10 11 12 |
11.46 6.12 16.20 0.85 2.70 6.45 2.49 3.32 0.30 4.35 0.47 0.22 |
134.60 3.01 4.76 0.58 8.71 2.65 1.49 1.60 4.88 1.35 0.03 2.76 |
13 14 15 16 17 18 19 20 21 22 23 24 |
5.30 0.05 2.38 1.64 15.58 15.08 1.38 1.72
|
1.80 0.60 1.42 2.20 0.50 2.00 13.60 4.26 18.00 0.34 2.60 2.83 |
Сукупна статистична вибірка обємом n = 44 спостереження включає дві незалежні малі вибірки обємами n1 = 20 i n2 = 24 спостереження.
Статистичний аналіз виконуємо в такій послідовності.
1.Виключення із статистичного ряду грубих похибок. Встановлення грубих (аномальних) похибок проводимо на основі критерію В.І.Романовського для малих вибірок.
Для цього розраховуємо статистичні характеристики вибірок.
-
№ вибірки


1
2
4.90
9.02
28.70
730.26
5.37
27.00
Розглянемо першу вибірку. Задаємось довірчою ймовірністю Pд = 0.95 і для n1 = 20 за таблицею додатка Д2 визначаємо коефіцієнт q1 = 2.15. Розраховуємо за формулою (1.6) граничну допустиму похибку окремого спостереження
![]() =
=
![]() q1
= 5.37
2.15
= 11.55.
q1
= 5.37
2.15
= 11.55.
Різниця
Qmax–
=
16.2
– 4.9
= 11.3
![]() = 11.5,
отже значення Qmax
із
вибірки не виключається.
= 11.5,
отже значення Qmax
із
вибірки не виключається.
Для другої вибірки маємо:
q2=1.96;
![]() =
=
![]()
![]() =
271.96
= 52.92;
=
271.96
= 52.92;
Qmax – = 134.6 – 9.02 = 125.58 = 52.92.
Тобто максимальне значення випадкової величини Qmax = 134.6 із вибірки виключається.
Для нового ряду встановлюємо нове значення Qmax = 18.00, визначаємо середньоквадратичне відхилення; обчислюємо критерій пр; порівнюємо Qmax – з пр; виключаємо при необхідності із статистичного ряду Qmax і отримуємо новий ряд із нових членів. Ці операції повторюємо до повного очищення ряду від аномальних значень випадкової величини . Результати наступних розрахунків для виключення грубих похибок наведені в таблиці.
Qmax |
Обєм вибірки n2 |
|
S2 |
|
q |
пр |
Qmax – |
Висновок |
18.0 13.6 8.71 4.88 |
23 22 21 20 |
3.56 2.91 2.63 2.08 |
19.14 9.51 4.05 1.96 |
4.38 3.10 2.00 1.40 |
1.96 1.96 1.96 2.15 |
8.58 6.08 6.92 3.08 |
14.44 10.69 6.08 2.80 |
Виключ. Виключ. Виключ. Залиш. |
Виключені значення випадкових величин в таблиці 1.4 виділені жирним шрифтом .
2. Перевірка однорідності сукупності. Для визначення істотності відмінностей двох вибірок розраховуємо за формулою для малих вибірок критерій
t
=
 =
=
=![]() =
1.92.
=
1.92.
За таблицею додатка Д4 для числа ступенів свободи к = n1+ n2 = 20 + 20 – 2 = 38 і Р = 0.95 визначаємо t = 2.02. Обчислене значення t t , отже статистична сукупність вважається однорідною.
3.
Визначаємо
статистичні характеристики скорегованої
сукупної вибірки об’ємом n=40 спостережень:
![]()
![]()
![]()
= 1.66.
= 1.66.
4. Визначення мінімальної кількості спостережень. Згідно з додатком Д3 для Р = 0.95 t = 1.96. Результати розрахунку за формулою (1.14) nmin для різних значень точності оцінки наведені в таблиці.
-
,%
1
2
3
4
5
nmin
517
129
57
32
21
За результатами розрахунків робимо висновок, що об’єм вибірки забезпечує точність розрахунків = 3.7%, яке лежить в межах припустимої , рівної 5%.
5. Встановлення емпіричного закону розподілу. Для побудови інтервального ряду розподілу досліджуваної випадкової величини визначаємо розмірність інтервалу
I
=
![]() =
=
![]() =
2.6.
=
2.6.
Приймаємо I = 3.0. Інтервальний ряд розподілу наведено в таблиці.
Інтервал випадкової величини |
Середина інтервалу xi |
Кількість значень mі |
Частість
|
Накопичена частість F(х) |
0.03 – 3.00 3.00 – 6.00 6.00 – 9.00 9.00–12.00 12.00 – 15.00 15.00 – 18.00 |
1.5 4.5 7.5 10.5 13.5 16.5 |
26 7 2 1 1 3 |
0.650 0.175 0.050 0.025 0.025 0.075 |
0.650 0.825 0.875 0.900 0.925 1.000 |
=40
За даними таблиці будуємо (рисунок 1.3) графіки емпіричного закону розподілу. По зовнішньому виду розподілу можна попередньо припустити, що досліджувана випадкова величина підпорядковується показниковому закону розподілу.

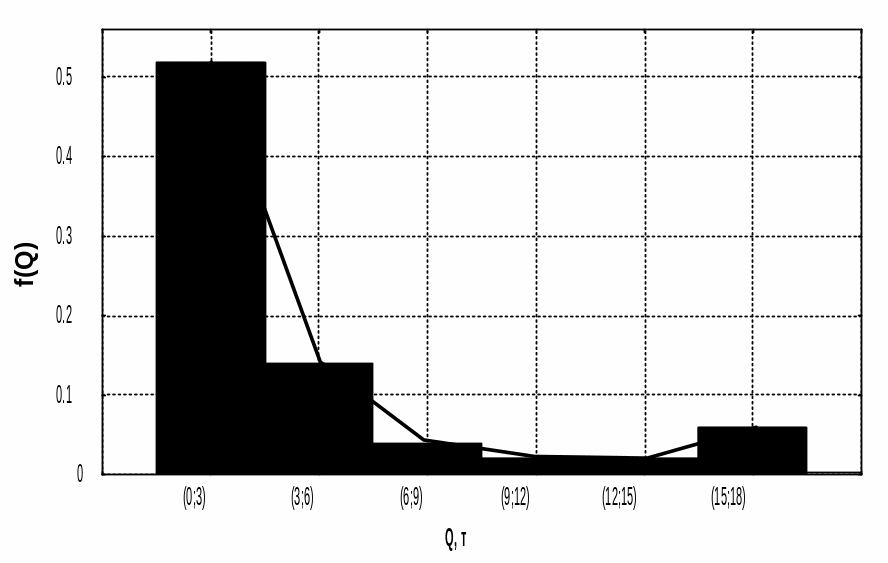
а) б)
Рисунок 1.3 – Графіки розподілу величини щомісячної поставки вантажів: а - гістограма і полігон; б – кумулята.