

7 .1 Загальні принципи моделювання
Неперервна випадкова величина X має розподіл
![]() , (7.1)
, (7.1)
де (х) – щільність ймовірностей.
Для
отримання неперервних випадкових
величин з заданим законом розподілу
можна скористуватись методом оберненої
функції. Взаємно одиночна монотонна
функція
![]() (рисунок 7.1), отримана розв’язком відносно
Х рівняння Fx(x)=ξ,
перетворює рівномірно розподілену на
інтервалі [0,1] величину ξ в Х
з потрібною щільністю х(х).
(рисунок 7.1), отримана розв’язком відносно
Х рівняння Fx(x)=ξ,
перетворює рівномірно розподілену на
інтервалі [0,1] величину ξ в Х
з потрібною щільністю х(х).
ξ1
ξ2
ξ |
Рисунок 7.1 – Графік інтегральної функції розподілу F(x) |

Дійсно, якщо випадкова величина Х має щільність розподілу х(х), то розподіл випадкової величини
![]() (7.2)
(7.2)
є рівномірним в інтервалі [0,1].
Це ствердження дає смогу сформувати правило імітації випадкових чисел {хі}, котрі мають функцію щільності f (x):
1) генерується
випадкове число ξі
![]() РВП[0,1];
РВП[0,1];
2) випадкове число хі з розподілом f (x) є розв’язком рівняння
![]() (7.3)
(7.3)
Таким чином, послідовність ξ1, ξ2, ξ3, … , що належить до РВП [0,1], перетворюється на послідовність х1, х2, х3, … , яка має щільність розподілу f (x).
Розглянемо основні способи імітації методом оберненої функції випадкових величин за загальним законом розподілу на основі випадкових чисел, рівномірно розподілених на інтервалі [0, 1].
7.2 Імітація за відомим теоретичним законом розподілу
Моделювання неперервних випадкових величин здійснюється за формулами, наведеними в таблиці 7.1.
Імітацію неперервних величин за теоретичними законами розподілу можливо застосовувати лише в разі виконання таких умов:
інтеграл (7.3) можна взяти (подати в квадратурах);
2) здобуте після інтегрування рівняння розв’язується відносно невідомого хі.
Таблиця 7.1 – Формули для моделювання неперервних випадкових величин.
Закон розподілу |
Щільність ймовірності |
Формули для моделювання |
|
Рівномірної щільності |
а, b – мінімальне і максимальне значення випадкової величини |
|
(7.4) |
Нормальний |
х – середнє квадратичне відхилення |
|
(7.5) |
Логарифмічно-нормальний |
v=lg x |
|
(7.6) |
Експоненційний (показниковий) |
|
|
(7.7) |
Релея |
|
|
(7.8)
(7.9) |
Гамма-розподіл |
|
|
(7.10) |



7.3 Наближені способи імітації
7.3.1 Імітація методом кускової апроксимації
Цей спосіб відноситься до універсальних і передбачає моделювання випадкових величин з будь-яким законом розподілу. Він заснований на кусковій апроксимації функції щільності, можливі значення якої лежать на інтервалі (а, b).Для цього f(x) показують у вигляді кусочно-постійної функції, тобто інтервал відрізку (а, b) розбивають на n часткових інтервалів (рисунок 7.2) таких, що
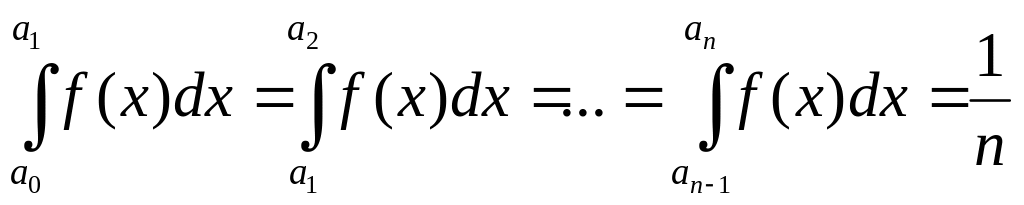 ,
,
де аі – координати точки розбиття.
|
|
Рисунок 7.2 – Графік кускової апроксимації функції щільності. |

Для моделювання f(x) достатньо розбити відрізок (а,b) на часткові інтервали так, щоб імовірність попадання випадкової величини Х в будь-який інтервал (ак , ак+1) була однаковою
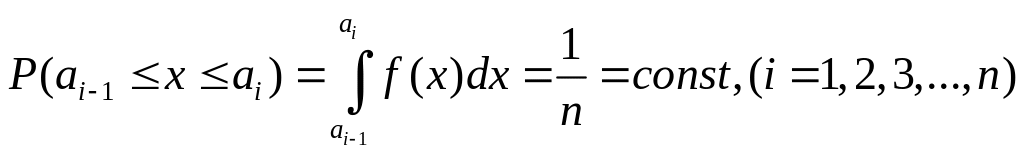
У цьому випадку випадкова величина Х не залежить від номера i-го інтервалу і може потрапити на будь-який відрізок з однаковою ймовірністю.
Функцію щільності f (x) апроксимуємо східчастою функцією так, щоб значення f (х) у кожному інтервалі було сталою величиною.
Координату точки М, котра потрапила на і-й інтервал, можна подати у вигляді
![]() (7.11)
(7.11)
де r – відстань точки М від лівого кінця інтервалу.
Застосовуючи лінійну апроксимацію, величину r можна подати як рівномірно розподілену випадкову величину на відрізку [0, (ai–ai-1 )]. Цю величину можна визначити за формулою
![]()
де ξ РВП [0,1].
Номер і-го інтервалу, в якому міститься точка М (шукана випадкова величина Х), можна визначити, скориставшись описаною раніше процедурою випробувань за “жеребкуванням” для рівноімовірних подій, що утворюють повну групу.
Алгоритм моделювання випадкової величини включає такі операції.
1. Генеруємо випадкове число 1 РВП [0, 1].
2. Визначається і-й інтервал з можливими значеннями випадкової величини
![]()
де […] означає, що треба взяти цілу частину.
3. Генерується випадкове число 2 РВП [0, 1].
4.
Розраховується
![]() .
.
5. Відшукується значення випадкової величини
![]() .
.
Процедуру моделювання розглянемо на прикладі.
Приклад 1. В таблиці наведені статистичні данні обсягу вантажних перевезень на п’яти маршрутах транспортної системи.
Маршрути |
Поквартальний обсяг перевезень, т |
|||
І |
ІІ |
ІІІ |
ІV |
|
М 1 |
341 |
222 |
309 |
194 |
М 2 |
352 |
366 |
202 |
323 |
М 3 |
404 |
158 |
496 |
456 |
М 4 |
543 |
308 |
187 |
400 |
М 5 |
454 |
181 |
418 |
452 |
Методом імітаційного моделювання визначити можливі значення обсягів перевезень за п’ять реалізацій.
Розв’язок.
1. Формуємо рівноймовірнісну таблицю розподілу. Для цього загальне число значень випадкової величини (N = 20) розбиваємо на п’ять (n = 5) рівних інтервалів, з ймовірністю події Pi = 1/n = 1/5 = 0.2 кожний.
Визначаємо число значень випадкової величини в кожному інтервалі mi = N/n = 20/5 = 4.
Будуємо варіаційний ряд випадкової величини і розбиваємо його на п’ять груп з чотирма значеннями випадкової величини в кожній групі 158, 181, 187, 194, 202, 222, 308,309, 323, 341, 352, 366, 400, 404, 418, 452, 454, 456, 496, 543.
В кожній
групі визначаємо мінімальне
![]() і максимальне
і максимальне
![]() значення обсягу перевезень і заносимо
в таблицю.
значення обсягу перевезень і заносимо
в таблицю.
Інтервальна ймовірність Рі |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
Інтегральний закон F(x) |
0.0–0.2 |
0.2–0.4 |
0.4–0.6 |
0.6–0.8 |
0.8–0.9 |
Інтервальне значення обсягів перевезень
|
158-194 |
202-309 |
323-366 |
400-452 |
454-543 |
2. Імітація розподілу обсягів перевезень.
№ реалізації |
і |
Номер інтервалу |
2 |
|
|
1 |
0.7460 |
4 |
0.4420 |
23 |
423 |
2 |
0.7124 |
4 |
0.5544 |
28.8 |
428.8 |
3 |
0.1012 |
1 |
0.2633 |
9.5 |
167.5 |
4 |
0.6368 |
4 |
0.2672 |
13.9 |
413.9 |
5 |
0.0438 |
1 |
0.2644 |
9.5 |
167.5 |