

3.4. Система естественно-языкового интерфейса (сеяи)
В настоящее время проблема общения с компьютером на естественном языке весьма далека от своего решения. Современные средства естественно-языкового интерфейса далеки от универсальных возможностей человеческой коммуникации.
Большинство СЕЯИ обеспечивает только доступ к базе данных, но их возможности недостаточны для сложных баз знаний. В идеале СЕЯИ должно удовлетворять следующим требованиям:
обеспечивать вход и выход системы в виде естественного языка;
обеспечивать обработку входных данных и генерацию выходных, основываясь на знании относительно синтаксических, семантических и прагматических аспектов естественного языка.
База знаний для СЕЯИ должна интегрировать следующие виды знаний.
Лингвистические знания — касаются широкого круга аспектов, начиная от обработки эллипсиса до понимания речевого акта для кооперативного дискурса.
Концептуальное знание означает, что существует фрагмент реальности, релевантный диалогу Одна из причин, почему СЯЕИ для доступа к базе данных были сравнительно успешными, заключается в том, что концептуальные знания предметной области базы данных являются ясными и хорошо определенным.
Инференциальное знание — относится к правилам базы знаний, подобным экспертной системе, основанной на правилах, которая работает на фактуальных и концептуальных знаниях, чтобы вывести имплицитные факты или правила из хранимых данных.
Модель пользователя описывает знание системы относительно стереотипов различных категорий пользователей, которые могут использовать СЕЯИ, включая аспекты образования, опыта, истории диалога или целей. Структура программного комплекса СЕЯИ очень сложная; она представлена на рис. 3.7.
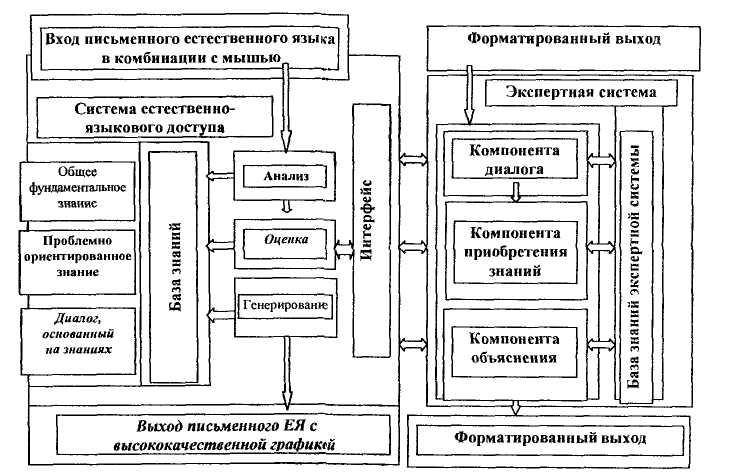
Рис. 3.7. Место СЕЯИ в инпеллектуалъной информационной системе
3.5. Технология работы интеллектуальных информационных систем (иис)
В первых экспертных системах отыскание, подготовка, извлечение и ввод знаний, специфических для предметной области, осуществлялись инженером по знаниям. Производилось интервьюирование соответствующих экспертов по специальной методике. Однако этот процесс был чрезвычайно трудоемким, кроме того, не все эксперты охотно делились своими знаниями. В связи с этим получили распространение методы интеллектуального анализа данных (knowledge discovery and data mining). Эти методы подробно рассматриваются в следующей главе В данном разделе приведены примеры автоматического формирования знаний.
По мере того как корпорации накапливают огромные массивы данных об их ежедневных операциях, использование этих данных становится наиболее важным направлением их деятельности. Чтобы удовлетворить клиентов и одержать победу в бизнесе на повседневно изменяющемся рынке, необходимо понимать данные и извлекать из них ценную информацию для последующего использования на всех стадиях деятельности корпорации — от генерации идей до планирования производства и проектирования целевого маркетинга и рекламного дела. Однако извлечение информации из данных усложняется по мере роста числа переменных и увеличения числа связей между переменными. Например, для каждого из 90 000 000 клиентов American Telephone and Telegraph Company (AT&T) существуют несвязанные записи в сотнях баз данных компании AT&T. Наверху этой пирамиды каждую секунду генерируется новая информация по мере того, как потоки информации закачиваются в сеть AT&T пользователями. Это означает, что свыше 200 000 000 новых элементов данных генерируется ежедневно в операциях AT&T. При таком экстраординарно огромном количестве данных и их сложных взаимосвязях проблема понимания поведения клиентов на уровне соответствующего сегмента рынка является чрезвычайно сложной, не говоря уже об уровне отдельного клиента. Техника открытия знаний в базах данных привлекает значительное внимание с позиций статистики, информационной технологии, обучения машин, систем баз знаний, СУБД.
Открытие знаний в базах данных (ОЗБД) — это процесс открытия первоначально неизвестных зависимостей в больших базах данных. ОЗБД включает в себя следующие элементы:
отбор, очистку, преобразование и проекцию данных;
анализ данных для извлечения зависимостей;
оценка зависимостей для отбора из них наиболее значимых, т.е. «знаний»;
консолидация знания;
разрешение конфликтов с ранее извлеченными знаниями;
обеспечение доступности знаний для системы ОЗБД.
Несмотря на то, что системы ОЗБД разработаны в области финансов, страхования, маркетинга, только немногие из них увязывают добытые знания непосредственно с процессами принятия решений. В данном разделе сделана попытка увязать процесс открытия знаний (используя модель обучения байесовской сети) и процесс принятия решений. Использована диаграмма влияния в качестве машины решений или системы обработки проблем, чтобы рекомендовать оптимальный вариант решения.
Рассмотрим в качестве примера эффективного применения этой технологии AT&T. Служба работы с клиентами AT&T осуществляет несколько миллионов контактов с пользователями ежедневно. В процессе таких контактов:
заполняются вопросники, анкеты;
осуществляется подписка на новые услуги;
фиксируются комментарии;
предлагаются специальные услуги, которых не было у клиента, но в которых он может быть заинтересован.
Телефонный дисконтный план (ТДП) — одна из таких услуг. Дополнительные услуги: радиотелефон, локальное обслуживание, услуги развлечений, ИНТЕРНЕТ-услуги. ТДП — это план, в котором оплата за телекоммуникации дисконтирована на определенную долю в зависимости от вида телефонных обращений и интенсивности использования. Рекламная компания по продвижению новой услуги стоит довольно дорого, так как требует много времени на объяснение преимуществ ТДП.
Интеллектуальная система поддержки решений, рекомендующая наилучший способ действий, полезна именно в такой ситуации. Цель этой системы — максимизировать эффективность телемаркетинга путем минимизации времени, затрачиваемого на безуспешную рекламную компанию. Теоретически это можно было бы сделать при помощи предсказания и проведения рекламной компании только с теми клиентам, которые подпишутся на него. Для предсказания вероятности отказа от подписки на ТДП разработана модель обучения байесовской сети на предварительно проклассифицированных множествах данных. Обучающий набор данных содержит реакцию клиентов на предварительно отобранные данные ТДП.
Интеллектуальная система поддержки решений должна предсказывать реакцию пользователя на предложение ТДП.
Подход состоит в том, чтобы предсказать (прогнозировать) реакцию пользователя на предложение ТП, основываясь на знаниях, полученных из предварительных реакций пользователя при контакте с базой данных. Чтобы получить хорошие предсказания реакции пользователя, используется система обучения машин, называемая ARPI (Advanced Pattern Recognition and Identification), извлекающая знание из базы данных и представляющая в байесовской сети.