

8. Классификация вычислительных систем по Флинну
Многомашинные и многопроцессорные ВС.
Микропроцессорная система - система, которая работает под управлением единой ОС.
Многомашинная система - различные ОС, где между машинами осуществляется только обмен информацией.
Повышение производительности ВТ достигается за счет:
1)Совершенствование технологии и элементов системы. Следовательно, рост такт част, освоение новых принципов (оптические процессоры, процессоры на арсениде галлия)
2)Создание коллектива вычислителей и рас||-ние вычисления – создание многомашинных и многопроцессорных систем).
Многопроцессорные ВС классифицируются по способу обработки информации
(Классификация по Флинну):
1. ОКОД (1 поток команд – 1 поток данных):
![]()
2. МКОД:
![]()
Пр.- конвейерная система, системы типа Cray, Ciber (быстродействие максимальное). Пр.- мультимедийные приложения, обработка изображений и звуков с максимальной производительностью.
3.ОКМД:
![]()
к/д – команда/данные.
Если ЭМ заменить ОЭВМ, то эта система – транспьютер.
Матричные процессоры – системы типа Solomon (каждый процессор работает со своим потоком данных, затем данные соединяются).
4. МКМД (система произвольной структуры):
![]()
Пр.- всевозможные нерегулярные структуры, где каждая машина работает по своим алгоритмам и образует свой поток данных.
9. Машины, управляемые потоком данных (df-машины)
Осн. особенность таких машин отсутствие в них счетчика команд.
Машина Массачуссетского технолог ун-та

Команда выполняется тогда, когда готова командная ячейка.
УУ- ч/з схему селекции отправляет в процессорный блок те командные ячейки для которых определены операнды. Предпола-гается что все команды выполняются за 1 такт.(1 инт времени)
Использование микропроцессорной машины с применением командных ячеек позволяет распараллеливать исходный алгоритм где команды выполняются по мере готовности операндов (не нужен счетчик команд).
Пример: x1,2=(-b±(b2-4*a*c))/2*a

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
1 такт Я0 Я1 Я2 Я3
2 такт Я4
3 такт Я5
4 такт Я6
5 такт Я7,Я8
6 такт Я9,Я10
Коэфф распараллеливания Кр=11/6=1,8.
Машина управляемая по запросу - выполняет команды по мере необходимости .
![]()
Главная машина анализирует исходный алгоритм, разбивает его на командные составляющие и поставляет запросы подчиненным машинам на формирование требуемых фрагментов алгоритма. Так же происх. распараллеливание, но фрагменты алгоритма по мере выполнения возвращаются в главную машину.
10.Общие принципы построения risc-процессоров. Особенности Берклинской архитектуры.
В ВТ сущ. правило 80/20: 80% времени уходит на выполн. 20% команд от полного набора инструкций процессора. Появилась задача изобретения ориентированного процессора. Перед разработчиками RISC-проц ставятся следующие задачи:
1)Выделяется область применения и класс решаемых задач, в этих задачах выделяются наиболее часто встречающиеся команды. Выделенные команды реализуются аппаратно с max возм быстродействием, обычно одна команда выполн за 1 такт. При этом использ простые способы адресации и простые инструкции.
2)Если введение новых команд не требует существ аппаратных затрат, то они вводятся. Разр RISC-процессоров ориентируется на поддержку ЯВУ и на конвейерный тип выполнения команд. Условно выполнение любой команды можно разбить на фазы:
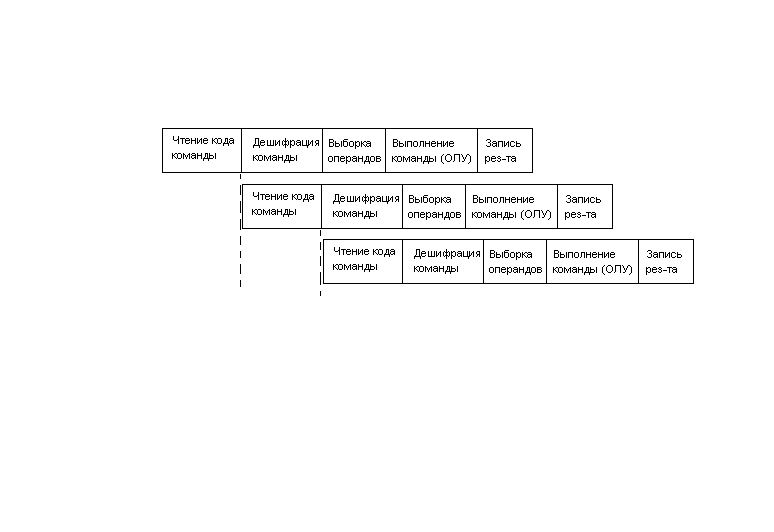
1 команда выполн 5 тактов, однако каждый след такт мы получаем рез-т. Все этапы выполн команды условно занимают одинаковый интервал времени. После заполнения конвейера за каждый такт на выходе имеем резкльтат=> высокая производительность.
Минус:команды должны быть одинаковы по времени.
Выполнение всех команд за одинаковое инт времени позволяет достигнуть высокой степени конвейеризации выполения процесса. Т.е. команды ктр не м/б выполнены за 1 такт реализуются на программном уровне с использованием стандартных библиотек. Основоположниками RISC архитектур явились ученые Берклинского и Старнфордского университетов.
Берклинская архитектура.
Анализ работы ЭВМ показывает что основные затраты времени приходятся на обращение проц к памяти и ВУ. Разработчики Берк. арх для уменьшения числа обращений к внешн памяти решили хранить всю инф в кристалле, для этого они увеличили число РОНов.
RISC II – 138 РОНов.
При выполнении программы около 70% результатов полученных от выполн предыдущей команды использ при выполн сдлед ком-ды.
138 РОНов разбили на 8 виртуальных логических окон в каждый момент времени каждая подпрогр работает с одним Вирт окном, каждое окно содержит 32 РОНа.
|
31 Верхние регистры 6 |
|
Локальные регистры 10 |
|
Нижние регистры 6 |
|
0 Глобальные регистры 10 |

Нижн рг – результаты выполнен предыдущей команды и они явл верхн для след процедуры.
Глоб переменные доступные для всех процедур.
Все память РОНов поделена на пересекающиеся виртуальные регистровые окна, результат проц А нах-ся в нижн рег окна А которые одновр явл верхн рег окна В и служат исходной инф для процедуры В такая орг.перекр окон позволяет сократить число команд пересылок физ инф м/у РОНами.

Глобальные регистры доступны из любого виртуального окна. Дальнейшее увеличение числа РОНов приводит к увеличению паразитных емкостей внутренне системной магистрали (внутри кристалла). Это приводит к снижению тактовой частоты процессора.