

75. Структура кэш-памяти с прямым распределением
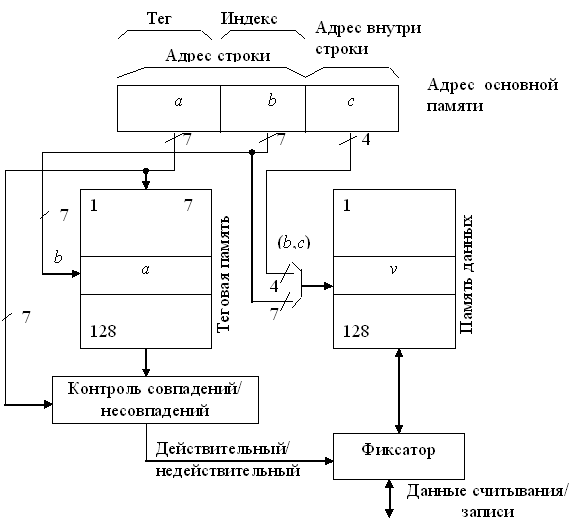
При прямом распределении место хранения строк в кэш-памяти однозначно определяется по адресу строки. Адрес строки подразделяется на тег (старшие 7 бит) и индекс (младшие 7 бит).
Для того, чтобы поместить в кэш-память строку из основной памяти с адресом bn, выбирается область внутри кэш-памяти с адресом bm, который равен 7 младшим битам адреса строки bn. Преобразование из bn в bm сводится только к выборке младших 7 бит адреса строки. По адресу bm в кэш-памяти может быть помещена любая из 128 строк основной памяти, имеющих адрес, 7 младших битов которого равны адресу bm. Для того чтобы определить, какая именно строка хранится в данное время в кэш-памяти, используется память ёмкостью 7 бит x 128 слов, в которую помещается по соответствующему адресу в качестве тега 7 старших битов адреса строки, хранящейся в данное время по адресу bm кэш-памяти. Это специальная память, называемая теговой памятью. Память, в которой хранятся строки, помещенные в кэш, называются памятью данных. В качестве адреса теговой памяти используются младшие 7 битов адреса строки.
76. Принцип работы кэш-памяти с полностью ассоциативным распределением
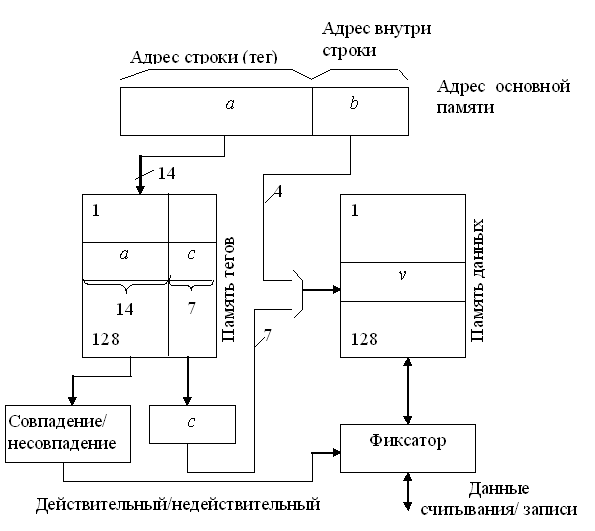
При полностью ассоциативном распределении механизм преобразования адресов должен быстро дать ответ, существует ли копия строки с произвольно указанным адресом в кэш-памяти, и если существует, то по какому адресу. Для этого необходимо, чтобы теговая память была реализована, как ассоциативная память. Входной информацией для ассоциативной памяти тегов (ключ поиска) является тег – 14-разрядный адрес строки, а выходной информацией – адрес строки внутри кэш-памяти (памяти данных). Каждое слово теговой памяти состоит из 14-разрядного тега и 7-разрядного адреса строки памяти данных кэша.
Ключ поиска параллельно сравнивается со всеми тегами ассоциативной памяти. При совпадении ключа с одним из тегов теговой памяти (кэш-попадание) происходит выборка соответствующего данному тегу адреса и обращение к памяти данных. Входной информацией для памяти данных является 11-разрядное слово (7 бит адреса строки и 4 бит адреса слова в данной строке). При выполнении операции чтения по этому адресу считывается и передается в процессор выбранная строка, а при записи – по этому же адресу в память данных записывается новая строка данных. При несовпадении ключа ни с одним из тегов теговой памяти (кэш-промах) осуществляется обращение к основной памяти и чтение необходимой строки. По этому способу при замене строк кандидатом на удаление могут быть все строки в кэш-памяти.
77. Принцип работы кэш-памяти с частично ассоциативным распределением
Адрес строки основной памяти (14 бит) разделяется на две части: b – тег (старшие 9 бит) и е – адрес группы (младшие 5 бит). Адрес строки внутри кэш-памяти, состоящий из 7 бит, разделяется на адрес группы (5 бит) и адрес строки внутри группы (2 бит).
Массивы тегов и данных состоят из четырех банков данных, доступ к каждому из которых осуществляется параллельно одинаковыми адресами. Каждый банк массива тегов имеет длину слова 9 бит для помещения значения тега, а число слов равно числу групп, т. е. 32. Каждый банк массива данных имеет длину слова такую же, как и у основной памяти, а ёмкость его определяется числом слов в одной строке, умноженным на число групп в кэш-памяти.
Для помещения в кэш-память строки, хранимой в ОП по адресу b, необходимо выбрать группу с адресом е. При этом не имеет значения, какая из четырех строк в группе может быть выбрана. Для выбора группы используется метод прямого распределения, а для выбора строки в группе используется метод полностью ассоциативного распределения.
Когда центральный процессор запрашивает доступ по i-му адресу к кэш-памяти с целью чтения или записи, то осуществляется обращение к массиву тегов по адресу е, выбирается группа из четырёх тегов (a, b, c, d), каждый из которых сравнивается со старшими 9 битами (b) адреса строки. На выходе четырёх схем сравнения формируется унитарный код совпадения (0100), который на шифраторе преобразуется в двухразрядный позиционный код, служащий адресом для выбора банка данных (01). При операции чтения (записи) одновременно осуществляется обращение к массиву данных по адресу e.f (9 бит) и считывание (запись) из банка (в банк) V2 требуемой строки или слова.
Одновременно осуществляется обращение к массиву данных по адресу e.f (9 бит) и считывание из банка V2 требуемой строки или слова. При пересылке новой строки в кэш-память удаляемая из нее строка выбирается из четырех строк соответствующего набора (группы).