

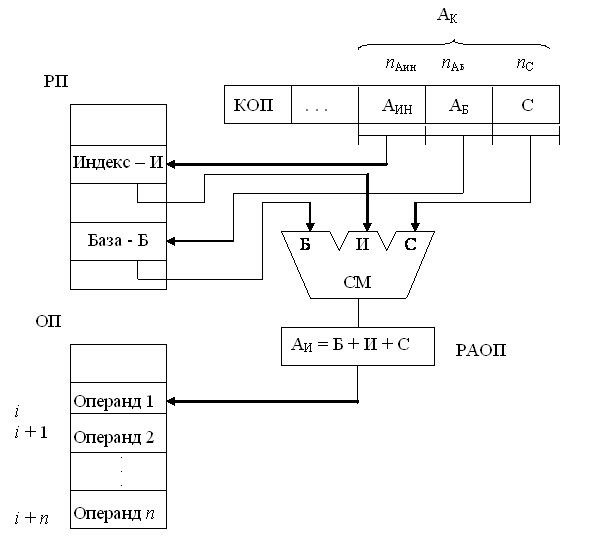
38. Реализация индексной адресации операндов
Для работы программ с массивами, требующими однотипных операций над элементами массива, удобно использовать индексную адресацию. В этом случае адрес i-го операнда в массиве определяется как сумма начального адреса массива (задаваемого полем смещения С) и индекса И, записанного в одном из регистров регистровой памяти, называемом теперь индексным регистром. Адрес индексного регистра задается в команде полем адреса индекса – АИН (аналогично АБ). Исполнительный адрес ОП = Адрес базы + адрес индекса + адрес смещения.
40. Развитие cisc-системы команд x86 (по годам)
Год появления набора команд |
Тип процессора, где впервые реализован |
Общее число команд |
Смысл расширения |
1979 |
i8086 |
170 |
Исходный набор команд |
1985 |
i386 |
220 |
50 новых команд для перехода к IA-32 |
1997 |
Pentium/MMX |
277 |
57 MMX команд |
1999 |
Pentium3 |
347 |
70 команд SSE расширения |
2000 |
Pentium4 Northwood |
491 |
144 команды SSE2 |
2004 |
Pentium4 Prescott |
504 |
13 команд SSE3 |
|
|
514 |
10 команд Intel VT-x |
2006 |
Core2 Duo(65нм) |
546 |
32 команды SSSE3 |
2007 |
Penryn(45) |
593 |
47 команд SSE4.1 |
2008 |
Core i7(45) |
600 |
7 команд SSE4.2 |
2009 |
Core i5(32) |
606 |
6 команд AES-NI |
41. Новые возможности процессора с введением sse2 и sse3
SSE2 значительно расширяет возможности обработки нескольких операндов по принципу SIMD. Используется 144 новых команды, обеспечивающих одновременное выполнение операций над несколькими операндами, которые располагаются в памяти и в 128-разрядных регистрах ХММ. В регистрах могут храниться и одновременно обрабатываться два числа с плавающей запятой в формате двойной точности (64 разряда) или 4 числа в формате одинарной точности (32 разряда), любые целочисленные типы данных, способные разместиться в 128-разрядных регистрах. Команды SSE2 существенно повышают эффективность процессора при реализации трехмерной графики и Интернет - приложений, обеспечение сжатия и кодирования аудио- и видеоданных и в ряде других приложений.
SSE3 включает 5 новых операций с комплексными числами, 5 потоковых операций над числами с плавающей запятой, 2 команды для синхронизации потоков и одну специальную инструкцию для применения при кодировании видео.
42. Расширения aes-ni и avx
AES-NI – набор из 6 новых SIMD-инструкций, ускоряющий процесс шифрования и дешифрования информации по стандарту AES. Стандарт AES является стандартом шифрования США, принятым в 2000-ом году. Он специфицирует алгоритм Rijndael, который представляет собой симметричный блочный шифр, работающий с блоками длиной 128 бит, и использует ключи длиной 128, 192 и 256 бит.
AVX – расширение системы команд х86 для микропроцессоров с новой микроархитектурой Intel Sandy Bridge и процессоров AMD Bulldozer. Представляет различные улучшения, новые инструкции и новую схему кодирования машинных кодов. Размер векторных регистров SIMD увеличивается с 128-ми до 256 бит. Существующие 128-битные инструкции будут использовать только младшую половину новых YMM-регистров. Набор инструкций AVX позволяет использовать любую двухоперандную инструкцию ХММ в трехоперандном виде без модификации 2-х регистров-источников, с отдельным регистром для результата. Добавлены инструкции с количеством операндов, более трех. Новая система кодирования машинных кодов VEX предоставляет новый набор префиксов кода, которые расширяют пространство возможных машинных кодов.