

3.6. Алгоритмы декодирования сверточных кодов
АЛГОРИТМ ДЕКОДИРОВАНИЯ ВИТЕРБИ
Среди различных алгоритмов декодирования сверточных кодов алгоритм максимального правдоподобия Витерби (АВ) получил наиболее широкое распространение в системах связи, в которых необходимо обеспечить экономию энергетического ресурса.
При декодировании в соответствии с критерием максимального правдоподобия выбирается то кодовое слово из множества возможных, которое ближе всего располагается к принятому кодовому слову в пространстве кодовых слов. Поскольку имеется 2K кодовых слов, то при реализации алгоритма максимального правдоподобия необходимо обеспечить запоминание всех кодовых слов и их сравнение с принятым словом. С увеличением K сложность вычислений и, следовательно, декодера возрастают.
Витерби предложил упрощенную процедуру вычислений при реализации алгоритма максимального правдоподобия. Он заметил, что каждый из четырех узлов имеет только двух предшественников, т.е. каждый из этих узлов можно достичь, минуя только два узла (см. рис. 3.7), и только один путь, который соответствует последовательности, наиболее «близкой» к принятой последовательности (путь с минимальным расстоянием), следует сохранять для каждого узла.
Обратимся к решетчатой диаграмме, изображенной на рис. 3.7. Задача состоит в том, чтобы для некоторой принятой последовательности символов найти путь на решетчатой диаграмме, соответствующий выходной последовательности символов, в максимальной степени совпадающей с принятой последовательностью.
Предположим, что первые шесть символов последовательности есть 01 00 01. Рассмотрим два пути, состоящих из трех ветвей (для шести символов) и заканчивающихся в узлах a, b, c и d. Из двух путей сохраним лишь тот, который в максимальной степени согласуется с последовательностью 01 00 01 (путь с минимальным расстоянием). Оставшийся для каждого узла такой путь будем называть «выжившим».
Имеется два пути в узел третьего уровня а: 00 00 00 и 11 10 11. Эти пути имеют расстояния от принятой последовательности 01 00 01, равные соответственно 2 и 3. Выжившим путем вычисления расстояния следует считать путь 00 00 00. Процедуру повторим для узлов b, c и d. Например, для узла с имеются два пути, соответствующих выходным последовательностям 00 11 10 и 11 01 01 и имеющих расстояния, соответственно равные 5 и 2. Выжившим следует считать путь 110101. Аналогичным образом производится отбор выживших путей для узлов c и d. В результате из восьми возможных путей сохраняются только четыре. Причина, по которой отбрасываются четыре пути, состоит в следующем. Два пути, сходящиеся, например, в узле третьего уровня а, имеют два одинаковых первых символа 00. Следовательно, независимо от последующих символов оба пути должны сойтись именно в этом узле а и в будущем выродиться в один.
Таким образом, необходимо запомнить четыре выживших пути и их расстояние от принятой последовательности. В общем случае количество выживших путей равно количеству состояний, т.е. 2K–1.
Теперь рассмотрим два очередных принятых символа. Допустим принимается последовательность символов 01 00 01 00. Сравним два выживших пути, которые сходятся в узле а четвертого уровня. Они могут выходить только из узлов а и с третьего уровня и соответствовать последовательностям 00 00 00 00 и 11 01 01 11, которые имеют расстояния, соответственно равные 2 и 4 от принятой последовательности 01 00 01 00. Следовательно, путь 00 00 00 00 следует считать выжившим для узла а четвертого уровня. Далее аналогичная процедура отбора повторяется для узлов b, c и d.
Отметим, что до окончания декодирования сохраняются только четыре конкурирующих пути, которые соответствуют выжившим путям для узлов a, b, c и d. Остается решить вопрос, когда произвести усечение алгоритма и принять решение в пользу одного из четырех оставшихся путей. Это можно сделать принудительно, положив последние два информационных символа равными 00, т.е. осуществить сброс. При поступлении на вход регистра первого символа 0 необходимо рассматривать выжившие пути только для узлов а и с, поскольку переход в узлы b и d возможен только при поступлении на вход символа 1. При поступлении на вход регистра второго символа 0 необходимо рассмотреть только выжившие пути, сходящиеся в узле а, поскольку при поступлении символов 00 декодер должен перейти в состояние а.
При реализации алгоритма Витерби объем памяти и сложность вычислений пропорциональна 2K, поэтому его целесообразно использовать при длине кодового ограничения K < 10. При больших длинах кодового ограничения, которые необходимы для достижения низких значений вероятности ошибки, обычно используется алгоритм последовательного декодирования.
АЛГОРИТМ ПОСЛЕДОВАТЕЛЬНОГО ДЕКОДИРОВАНИЯ
При последовательном декодировании, алгоритм которого был предложен Возенкрафтом, сложность декодера возрастает линейно с увеличением длины кодового ограничения. Для описания особенностей алгоритма рассмотрим кодер с K = 4 и n = 3, изображенный на рис. 3.8. Кодовое дерево сверточного кода показано на рис. 3.9. Здесь каждый входной информационный символ порождает три кодовых символа и оказывает влияние на четыре группы из трех символов. При декодировании будем рассматривать только три (или n) символа одновременно, чтобы принять промежуточное решение, предполагающее возможность его изменения при возникновении трудностей в дальнейшем.
Декодер, реализующий алгоритм последовательного декодирования, можно сравнить с водителем, который случайно принимает неверные решения при разветвлении дороги, но быстро обнаруживает свои ошибки (по дорожным указателям), возвращается назад и движется по новому пути.
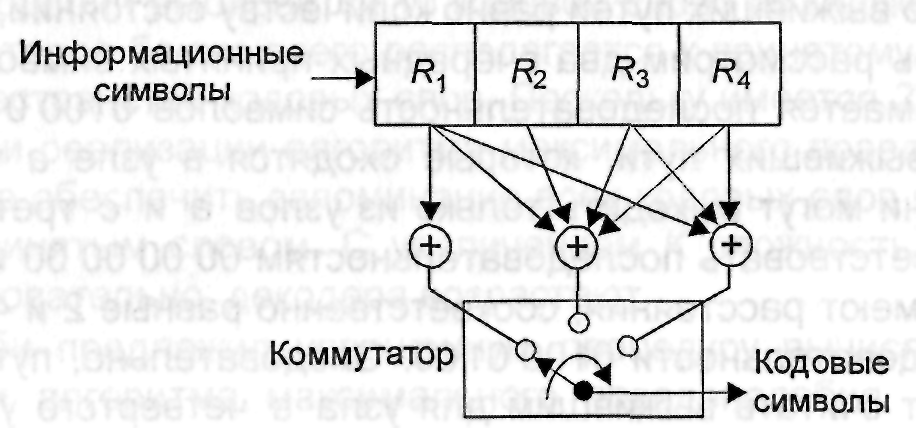
Рис. 3.8. Структурная схема кодера сверточного кода
Применительно к рассматриваемому алгоритму это означает следующее. Из начального узла п1 для первых трех принятых символов имеется два пути длиной три символа. Выбирается тот путь, который соответствует последовательности, имеющая наименьшее расстояние Хэмминга от первых трех принятых символов. В результате выбирается наиболее вероятный узел. Из этого узла выходят также два пути длиной, равной трем символам. Для второй группы из трех принятых символов также выбирается путь, соответствующий последовательности с минимальным расстоянием Хэмминга, и осуществляется переход в четвертый узел. Если имеет место большое количество ошибок в определенных группах из n принятых символов, то будет выбран ошибочный путь, при движении по которому будут возникать трудности согласования принятой последовательности символов с последовательностями, соответствующими ложному узлу. Это служит основанием для того, чтобы сделать вывод о наличии ошибки при выборе пути.
Поясним это на примере. Предположим, что входная последовательность информационных символов 11010 поступает на вход кодера, изображенного на рис.3.8. Так как K = 4, то необходимо дополнить эту последовательность последовательностью 000, которая обеспечивает окончание процедуры декодирования. Поэтому последовательность информационных символов, дополненная последовательностью «сброса», будет иметь структуру 11010000.
Согласно
кодовому дереву, изображенному на рис.
3.9, последовательность кодовых символов
будет 111 101 001 111 001 011 011 000. Пусть принимаемая
последовательность, содержащая три
ошибки (одну в первой группе символов
и две во второй), будет 101 011 001 111
001 011 011 000. Процедура декодирования
начинается с узла n1.
Первая группа символов 101 ближе всего
к последовательности 111, поэтому при
правильном решении происходит переход
к узлу n2.
Однако вторая группа символов 011,
содержащая две ошибки, оказывается
ближе к последовательности 010, а не к
истинной последовательности 101. Поэтому
происходит переход не к истинному узлу
n3,
а к ложному
![]() .
Начиная с этого узла процесс идет по
ложному пути, поэтому принятая
последовательность не будет согласована
с любой последовательностью, начинающейся
в узле
.
.
Начиная с этого узла процесс идет по
ложному пути, поэтому принятая
последовательность не будет согласована
с любой последовательностью, начинающейся
в узле
.
Третья
группа принятых символов 001 не будет
согласована с любой последовательностью,
начинающейся в
,
например 001 или 100, и она оказывается
ближе к последовательности 011. Потому
происходит переход в узел
![]() .
.
Четвертая
группа принятых символов 111 снова
оказывается несогласованной с любой
из последовательностей, начинающихся
в узле
,
например 011 или 100, и она оказывается
ближе к последовательности 011. В этом
случае произойдет переход в узел
![]() .
Можно заметить, что расстояние Хэмминга
между последовательностью, соответствующей
пути между узлами n1,
n2,
,
,
и содержащей 12 символов, равно 4. Это
показывает, что имеют место четыре
ошибки при условии, что выбранный путь
является правильным.
.
Можно заметить, что расстояние Хэмминга
между последовательностью, соответствующей
пути между узлами n1,
n2,
,
,
и содержащей 12 символов, равно 4. Это
показывает, что имеют место четыре
ошибки при условии, что выбранный путь
является правильным.
Такое
большое количество ошибок должно вызвать
подозрение. Действительно, если
вероятность ошибки в двоичном символе
равна Рb,
то среднее значение количества ошибок
пE
в блоке, содержащем d
символов, равно Рbd.
Поскольку значение Рb
обычно лежит в пределах от 10-4
до 10-6, то такое количество ошибок
в блоке, содержащем 12 символов,
представляется неправдоподобным.
Поэтому следует возвратиться к узлу
и двигаться по нижнему пути, который
ведет к узлу
![]() .
Однако путь через узлы n1,
n2,
,
.
Однако путь через узлы n1,
n2,
,
![]() ,
оказывается еще хуже с предыдущего,
поскольку он соответствует наличию
пяти ошибок в блоке из 12 символов. Поэтому
происходит возвращение к узлу п2
и движение по пути, приводящему в узел
n3,
и так далее до тех пор, пока не будет
найден путь, проходящий через узлы n1,
n2,
n3,
n4,
n5
и соответствующий наличию трех ошибок.
Если предположить, что возвращение
произойдет в узел n1
и попытаться найти другие пути, то среди
них не найдется ни одного, который
соответствовал бы наличию менее пяти
ошибок.
,
оказывается еще хуже с предыдущего,
поскольку он соответствует наличию
пяти ошибок в блоке из 12 символов. Поэтому
происходит возвращение к узлу п2
и движение по пути, приводящему в узел
n3,
и так далее до тех пор, пока не будет
найден путь, проходящий через узлы n1,
n2,
n3,
n4,
n5
и соответствующий наличию трех ошибок.
Если предположить, что возвращение
произойдет в узел n1
и попытаться найти другие пути, то среди
них не найдется ни одного, который
соответствовал бы наличию менее пяти
ошибок.

Рис. 3.9. Кодовое дерево для кодера, изображенного на рис.3.8
Поэтому в качестве правильного принимается путь, проходящий через узлы n1, n2, n3, n4, n5. Этому пути соответствует первый декодированный символ 1. Далее процедура продолжается с целью декодирования второго символа, начиная с узла n2, с отбрасыванием первых трех принятых символов, и она повторяется до тех пор, пока не будут декодированы все символы.
Одним
из основных является вопрос о выборе
критерия, согласно которому выносится
решение о выборе ложного пути. Зависимость
математического ожидания количества
ошибок пE
от числа декодируемых символов d
представляет собой прямую (![]() )
с наклоном, определяемым значением Рb,
которая приведена на рис. 3.10. Там же
показано истинное значение количества
ошибок, соответствующее выбранному
пути. Если количество ошибок лежит в
допустимых пределах, установленных
пороговым уровнем, то декодирование
продолжается. В противном случае
происходит переход назад к ближайшему
узлу и предпринимаются попытки найти
другой путь. Если количество ошибок
продолжает расти, то возвращение
осуществляется к следующему по порядку
узлу, и так до тех пор, пока количество
ошибок не окажется в допустимых пределах.
)
с наклоном, определяемым значением Рb,
которая приведена на рис. 3.10. Там же
показано истинное значение количества
ошибок, соответствующее выбранному
пути. Если количество ошибок лежит в
допустимых пределах, установленных
пороговым уровнем, то декодирование
продолжается. В противном случае
происходит переход назад к ближайшему
узлу и предпринимаются попытки найти
другой путь. Если количество ошибок
продолжает расти, то возвращение
осуществляется к следующему по порядку
узлу, и так до тех пор, пока количество
ошибок не окажется в допустимых пределах.
Если значение порогового уровня выбрать близким к математическому ожиданию количества ошибок, то это сократит средний объем вычислений. С другой стороны, если значение порогового уровня установить слишком «жестким» (т.е. очень близким к математическому ожиданию количества ошибок), то при декодировании будут отбрасываться все возможные пути в некоторых чрезвычайно редких случаях, когда из-за воздействия шума может произойти необычайно большое количество ошибок. Это явление может быть устранено путем выбора «жесткого» порогового уровня в начале процесса декодирования, и если при декодировании происходит отбрасывание всех путей, то пороговый уровень постепенно увеличивается до тех пор, пока не окажется приемлемым один из возможных путей.
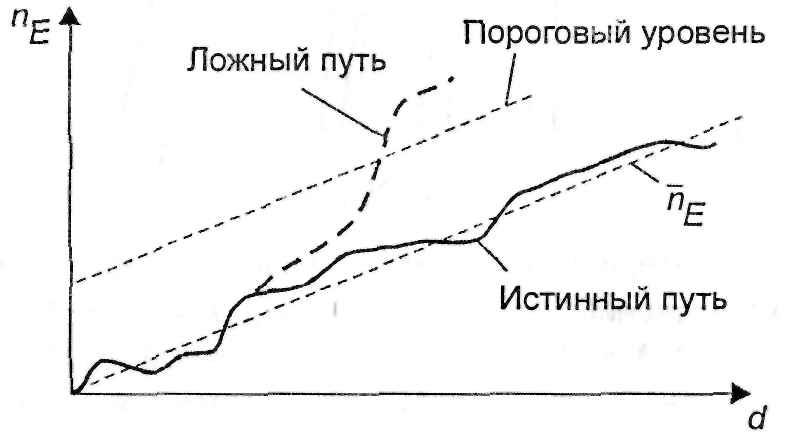
Рис. 3.10. Иллюстрация выбора порога при последовательном декодировании
Установлено, что при последовательном декодировании вероятность ошибки с увеличением K уменьшается по экспоненциальному закону, а его сложность – по линейному. При этом среднее число анализируемых ложных путей на один декодируемый символ остается ограниченным, если величина = 1/n оказывается меньше так называемой предельной вычислительной скорости 0.
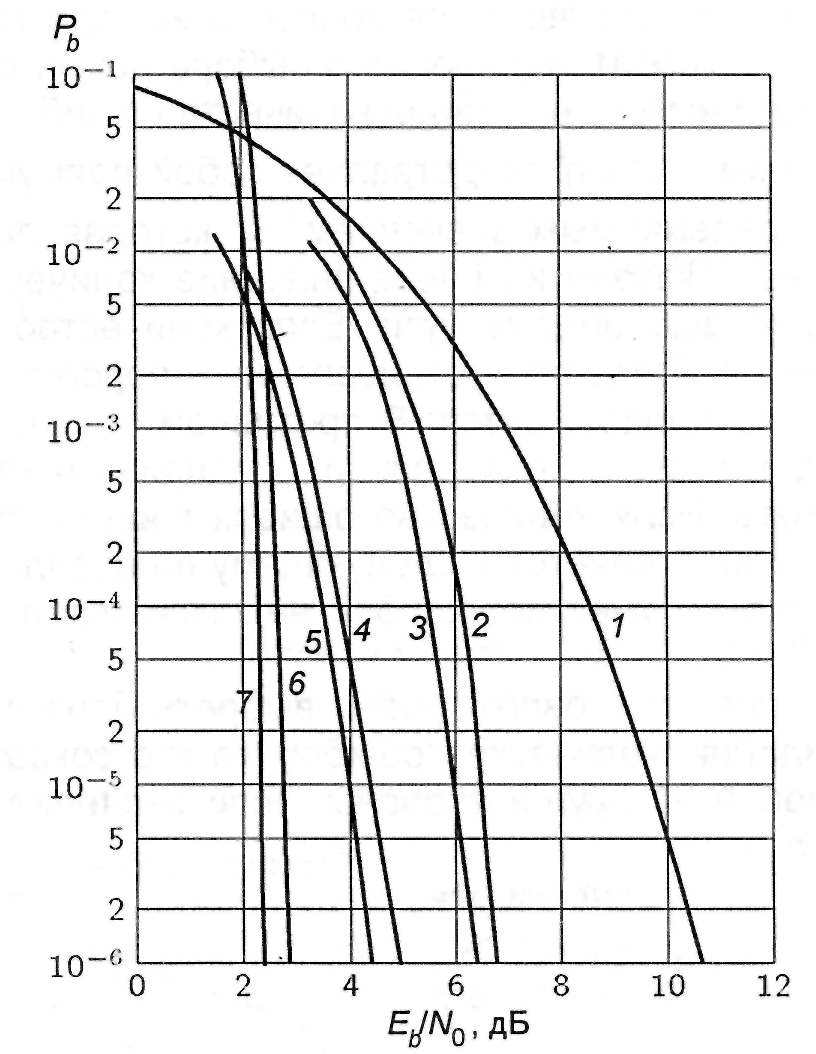
Рис. 3.11. Характеристики помехоустойчивости сверточных кодов: 1 – без кодирования; 2 – сверточный код, R = 1/2, K = 7, ж.р., АВ; 3 – сверточный код, R = 1/3, K = 7, ж.р., АВ; 4 – сверточный код, R = 1/2, K = 7, м.р., АВ; 5 – сверточный код, R = 1/3, K = 7, м.р., АВ; б – сверточный код, R = 1/2, K = 41, АП; 7 – сверточный код, R = 1/2, K = 41, АП (ж. р. – жесткие решения; м.р.– мягкие решения; АВ - алгоритм Витерби; АП – алгоритм последовательного декодирования)
Алгоритму последовательного декодирования присущи следующие недостатки:
количество ложных участков и, следовательно, вычислительная сложность является случайной величиной, зависящей от уровня шума в канале связи;
для снижения необходимого объема памяти скорость декодирования должна в 10...20 раз превышать скорость поступления входных данных, что ограничивает максимальную скорость передачи сообщений;
среднее количество анализируемых ложных участков пути эпизодически может оказаться чрезвычайно большим и привести к переполнению памяти, а это может вызывать появление сравнительно длинных выходных последовательностей, содержащих большое количество ошибок.
Характеристики помехоустойчивости сверточных кодов при использовании этих алгоритмов из-за трудностей математического характера в основном могут быть получены методом математического моделирования. На рис. 3.11 приведены характеристики помехоустойчивости некоторых сверточных кодов для системы связи, использующей двоичную ФМ и когерентную демодуляцию.
К наиболее просто реализуемым алгоритмам декодирования сверточных кодов относятся алгоритм декодирования с обратной связью и алгоритм порогового (мажоритарного) декодирования. Однако характеристики этих алгоритмов заметно уступают характеристикам первых двух.
ПОРОГОВОЕ ДЕКОДИРОВАНИЕ
Рассмотрим
простой пример, иллюстрирующий особенности
алгоритма порогового декодирования.
Структурная схема кодера изображена
на рис. 3.12, а. Пусть содержимое разрядов
регистра есть R1 = an
и R1 = an-1,
а выходная последовательность
![]() .
.
Структурная схема порогового декодера, реализующая метод порогового декодирования Мэсси, изображена на рис. 3.12, б.
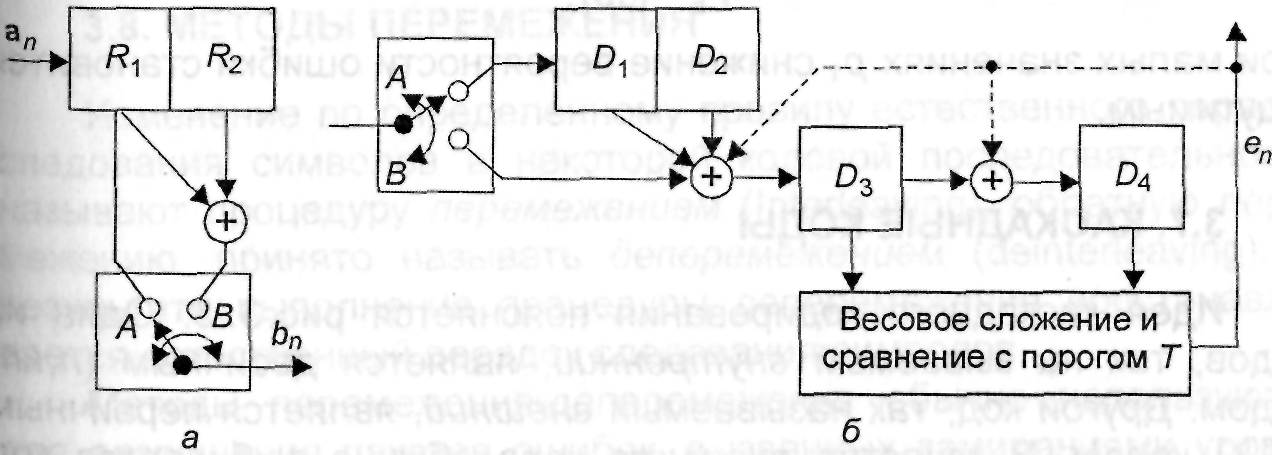
Рис. 3.12. Структурные схемы кодера (а) и декодера (б) сверточного кода, допускающего пороговое декодирование
Последовательность символов на входе кодера
![]() ,
,
где
![]() ,
,
![]() – последовательность символов
вектора ошибок, возникающих в канале
связи при передаче первого и второго
символов соответственно. Ключ находится
в положении А при декодировании
первого символа и в положении В при
декодировании второго символа
соответственно.
– последовательность символов
вектора ошибок, возникающих в канале
связи при передаче первого и второго
символов соответственно. Ключ находится
в положении А при декодировании
первого символа и в положении В при
декодировании второго символа
соответственно.
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
При соответствующих значениях отношения сигнал/шум в D3 и D4 содержится достаточно информации для надежного решения.
Если
D3
и D4
равны 1, то имеется две возможности.
Во-первых, символ
![]() равен 1, во вторых
= 0,
тогда
равен 1, во вторых
= 0,
тогда
![]() либо
либо
![]() равен 1 и
равен 1 и
![]() либо
равен 1. Для малых вероятностей ошибки
в канале вероятность того, что
равен 1, приблизительно есть p1.
В другой ситуации требуется, чтобы в
последовательности
,
,
,
имели место две ошибки. Вероятность
этого события
либо
равен 1. Для малых вероятностей ошибки
в канале вероятность того, что
равен 1, приблизительно есть p1.
В другой ситуации требуется, чтобы в
последовательности
,
,
,
имели место две ошибки. Вероятность
этого события
![]() .
Таким образом, если и D3
и D4
равны 1, то с высокой вероятностью
равен 1. Оценить это можно с помощью
пороговой схемы, установив пороговое
значение 0,5. Если порог превышается, то
с высокой вероятностью обнаруживается
ошибка в предшествующем информационном
символе (код является систематическим).
.
Таким образом, если и D3
и D4
равны 1, то с высокой вероятностью
равен 1. Оценить это можно с помощью
пороговой схемы, установив пороговое
значение 0,5. Если порог превышается, то
с высокой вероятностью обнаруживается
ошибка в предшествующем информационном
символе (код является систематическим).
Вероятность появления ошибки при декодировании определяется вероятностью того, что в последовательности , , , , имеет место более одной ошибки. Вероятность этого события
![]() .
.
Для малых значений p1
![]() .
.
При малых значениях p1 снижение вероятности ошибки становится ощутимым.