

3.4. Вероятности ошибочного приема сообщения и двоичного символа (бита)
При оценке энергетического выигрыша кодирования кодов, различающихся длиной блока и кодовой скоростью, более удобной оказывается характеристика помехоустойчивости, выражаемая через вероятность ошибки на двоичный символ (бит).
Соотношение между вероятностями ошибки декодирования слова и ошибки на бит определяется структурой порождающей матрицы конкретного кода. Однако для обобщенного анализа могут быть получены простые границы для вероятности ошибки на бит. Пусть длительность сеанса связи составляет 1с. Тогда за сеанс связи может быть передано 1/TW кодовых слов, которые содержат k/TW информационных символов. Количество ошибочно принятых кодовых слов равно PWk/TW. Если через k0 обозначить количество ошибочно принятых информационных символов при каждом ошибочно принятом кодовом слове, то вероятность ошибки на бит будет равна
![]() . (3.19)
. (3.19)
Проблема заключается в определении величины k0. В наихудшем случае ошибочный прием кодового слова сопровождается ошибочным приемом всех k информационных символов. Тогда получаем верхнюю границу
![]() . (3.20)
. (3.20)
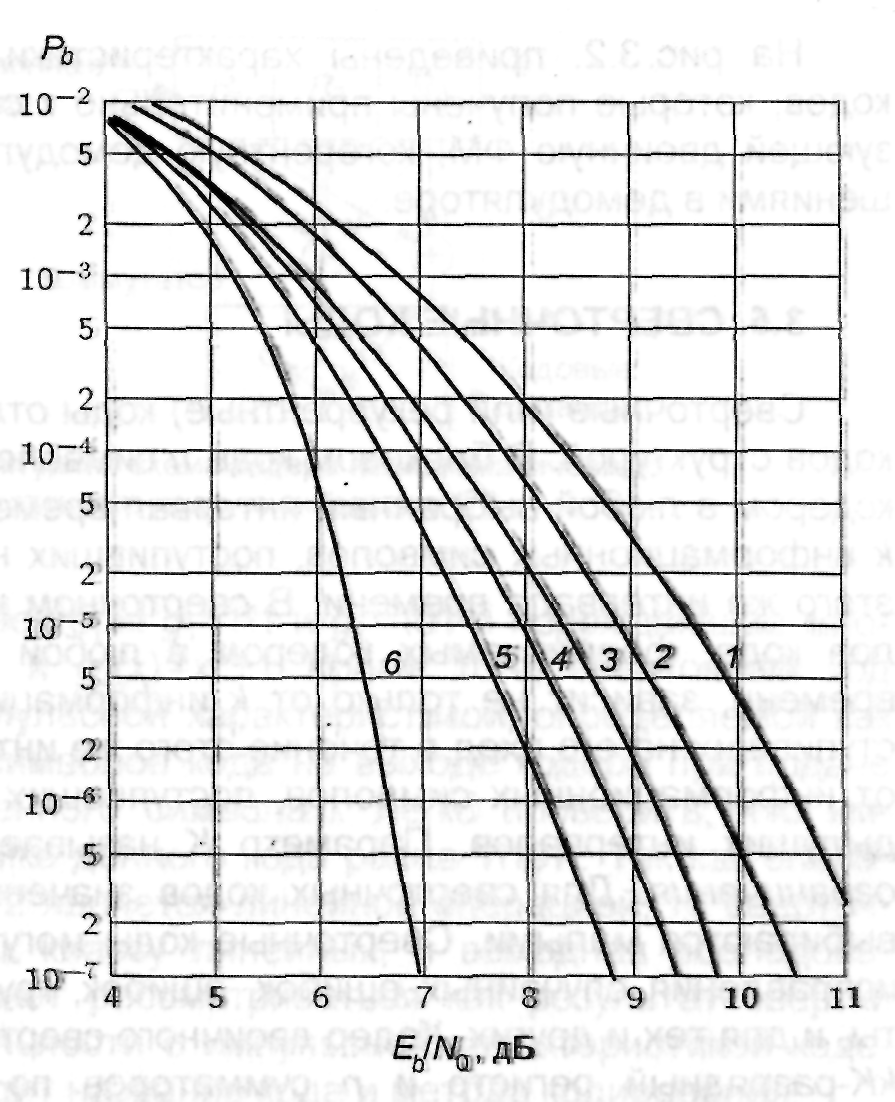
Рис.3.2. Характеристики помехоустойчивости блоковых кодов: 1 – без кодирования; 2 – код Хэмминга (7, 4); 3 – код Хэмминга (15, 11); 4 – код Хэмминга (31, 26); 5 – код Голея (24, 12); 6 – код БЧХ (127, 64)
В лучшем случае ошибочный прием кодового слова приводит к единственной ошибке в информационных символах. Поэтому для нижней границы имеем k0=1 и
![]() . (3.21)
. (3.21)
Для малых значений k верхняя и нижняя границы становятся строгими, и для оценки вероятности ошибки на бит может быть использована вероятность ошибочного приема слова. Для высоких значений Eb/N0 вероятность ошибки на символ оказывается чрезвычайно малой и ошибки при декодировании кодовых слов с большой вероятностью возникают при появлении (t+1) ошибочных символов. Из этих (t+1) ошибочных символов в среднем (t+1)/n относится к информационным. В результате
![]() , (3.22)
, (3.22)
![]() . (3.23)
. (3.23)
На рис. 3.2. приведены характеристики некоторых блоковых кодов, которые получены применительно к системе связи, использующей двоичную ФМ, когерентную демодуляцию с жесткими решениями в демодуляторе.
3.5. Сверточные коды
Сверточные (или рекуррентные) коды отличаются от блоковых кодов структурой. В блоковом коде n символов кода, формируемых кодером в любой выбранный интервал времени, зависят только от k информационных символов, поступивших на его вход в течение этого же интервала времени. В сверточном коде блок из n символов кода, формируемых кодером в любой выбранный интервал времени, зависит не только от k информационных символов, поступивших на его вход в течение этого же интервала времени, но и от информационных символов, поступивших в течение (K–1) предыдущих интервалов. Параметр K называется длиной кодового ограничения. Для сверточных кодов значение параметров n и k выбираются малыми. Сверточные коды могут использоваться для исправления случайных ошибок, ошибок, группирующихся в пакеты, и для тех и других. Кодер двоичного сверточиого кода содержит kK-разрядный регистр и n сумматоров по mod 2. Обобщенная структурная схема кодера сверточного кода приведена на рис.3.3.
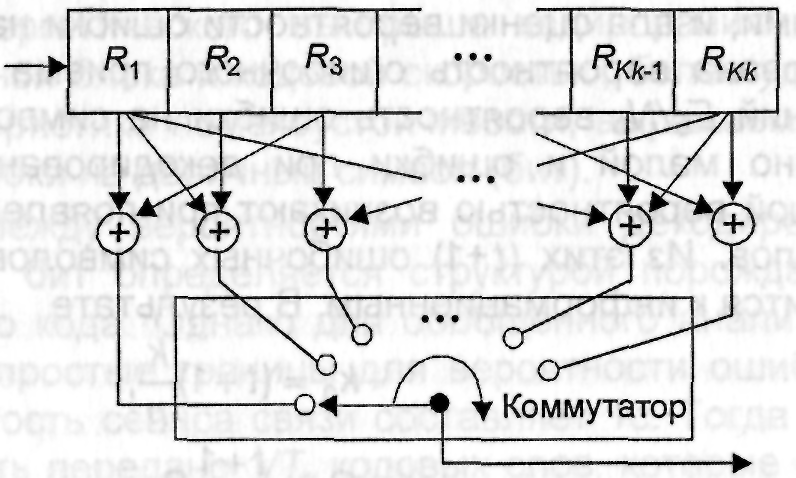
Рис. 3.3. Обобщенная структурная схема кодера сверточного кода
На рис. 3.4 приведены пример кодера сверточного кода с параметрами k =1, n = 2, K = 3, Rk = 1/2. Информационные символы поступают на вход регистра, а символы кода формируются на выходе коммутатора. Коммутатор (КМ) последовательно опрашивает выходы сумматоров по mod 2 в течение интервала времени, равного длительности информационного символа (бита).
Схема подключения сумматоров по mod 2, значения k, n и K полностью описывают сверточный код. Их можно определить с помощью генераторных векторов или многочленов. Например, сверточный код, формируемый кодером, изображенным на рис.3.4,
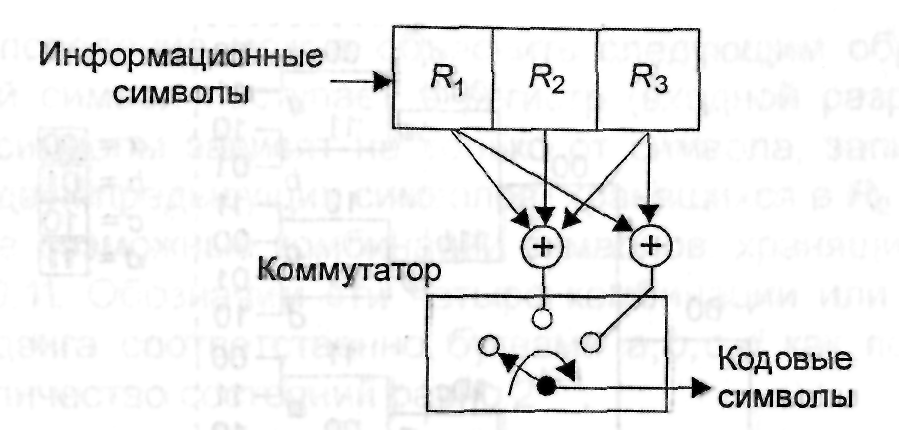
Рис. 3.4. Структурная схема кодера несистематического сверточного кода со скоростью 1/2
Информационные символы имеет порождающие векторы g1 = 111 и g2 = 101 и порождающие многочлены g1(х) = х2+х+1 и g2(х)=х2+1. Кроме того, сверточный код может быть задан импульсной характеристикой, определяемой как последовательность символов кода на выходе кодера при подаче на его вход единственного символа 1. Легко проверить, что импульсная характеристика данного кода равна 111011. Так как операция сложения по mod 2 является линейной операцией, то сверточные коды относятся к классу линейных, и выходная последовательность кодера может рассматриваться как результат свертки входной последовательности с импульсной характеристикой кодера. Отсюда и происходит название кода и метода кодирования.
Процедуры кодирования и декодирования удобно описывать с помощью так называемого кодового дерева, которое отображает последовательности на выходе кодера для любой возможной входной последовательности. На рис. 3.5 приведено кодовое дерево кодера, изображенного на рис. 3.4, для блока из пяти информационных символов. Если первый символ принимает значение 0, то на выходе кодера формируется пара символов 00. Если первый символ принимает значение 1, то на выходе кодера формируется пара символов 11. Это показано с помощью двух ветвей, которые выходят из начального узла. Верхняя ветвь соответствует 0, нижняя – 1. В каждом из последующих узлов ветвление происходит аналогичным образом: из каждого узла исходит две ветви, причем верхняя ветвь соответствует 0, а нижняя – 1. Ветвление будет происходить вплоть до последнего символа входного блока. Вслед за ним все входные символы принимают значение 0, и образуется только одна обрывающаяся ветвь. Таким образом, каждой из возможных входных комбинаций информационных символов соответствует своя вершина на кодовом дереве. В данном случае имеется 32 вершины. С помощью кодового дерева легко построить выходную последовательность символов кода, соответствующую определенной входной последовательности. Например, входной последовательности 11010 соответствует выходная последовательность, лежащая на пути, изображенном пунктирной линией.

Рис.3.5. Кодовое дерево для кодера, изображенного на рис. 3.4
Анализируя структуру кодового дерева на рис. 3.5, можно заметить, что, начиная с узлов третьего уровня, она носит повторяющийся характер. Действительно, группа ветвей, заключенных в прямоугольники, изображенные пунктирными линиями, полностью совпадают. Это означает, что при поступлении на вход четвертого символа выходной символ кода будет одним и тем же, независимо от того, каким был первый входной символ: 0 или 1. Другими словами, после первых трех групп выходных символов кода входные последовательности 1x1x2x3x4... и 0x1x2x3x4... будут порождать один и тот же выходной символ.
Обозначим четыре узла третьего уровня, т.е. узлы, в которых происходит третье ветвление, буквами a,b,c,d. Повторяющаяся структура ветвей имеет место и для узлов четвертого и пятого уровней, поэтому их также можно обозначить этими же буквами. Для узлов пятого уровня любой из четырех комбинаций (11,10,01, 00) первых двух входных символов будет соответствовать один и тот же выходной символ.
Такое поведение можно объяснить следующим образом. Когда входной символ поступает в регистр (входной разряд R1), то выходные символы зависят не только от символа, записанного в R1, но и от двух предыдущих символов, хранящихся в R2 и R3. Имеется четыре возможные комбинации символов, хранящихся в R2 и R3: 00, 01, 10, 11. Обозначим эти четыре комбинации или состояния регистра сдвига соответственно буквами a, b, c, d как показано на рис. 3.5. Количество состояний равно 2K–1.
Входные символы 0 и 1 будут формировать четыре различные комбинации выходных символов в зависимости от состояния кодера. Если входной символ 0, то на выходе декодера будут формироваться 00, 10, 11 или 01 в зависимости от того, в каком состоянии находился кодер: a, b, c или d. To же самое правило можно применить относительно символа 1.
Таким образом, поведение кодера можно полностью описать с помощью диаграммы состояний, изображенной на рис. 3.6, а или направленного графа с четырьмя состояниями (рис. 3.6, б) который устанавливает однозначное соответствие между входными и выходными символами кодера. На графе сплошные линии соответствуют входному символу 0, а пунктирные – символу 1. Например, если кодер находится в состоянии а и на вход поступает 1, то на выходе декодера будет формироваться комбинация 11 (пунктирная линия) и декодер перейдет в состояние b, соответствующее R3 = 0 и R2 = 1 – Аналогичным образом при поступлении 0 декодер останется в состоянии а (сплошная линия) и на выходе будет формироваться комбинация 00.
Заметим, что прямой переход из состояния а в состояние с или d невозможен, причем из любого состояния прямой переход возможен только в одно из двух состояний. Диаграмма состояний содержит исчерпывающую информацию о структуре кодового дерева.
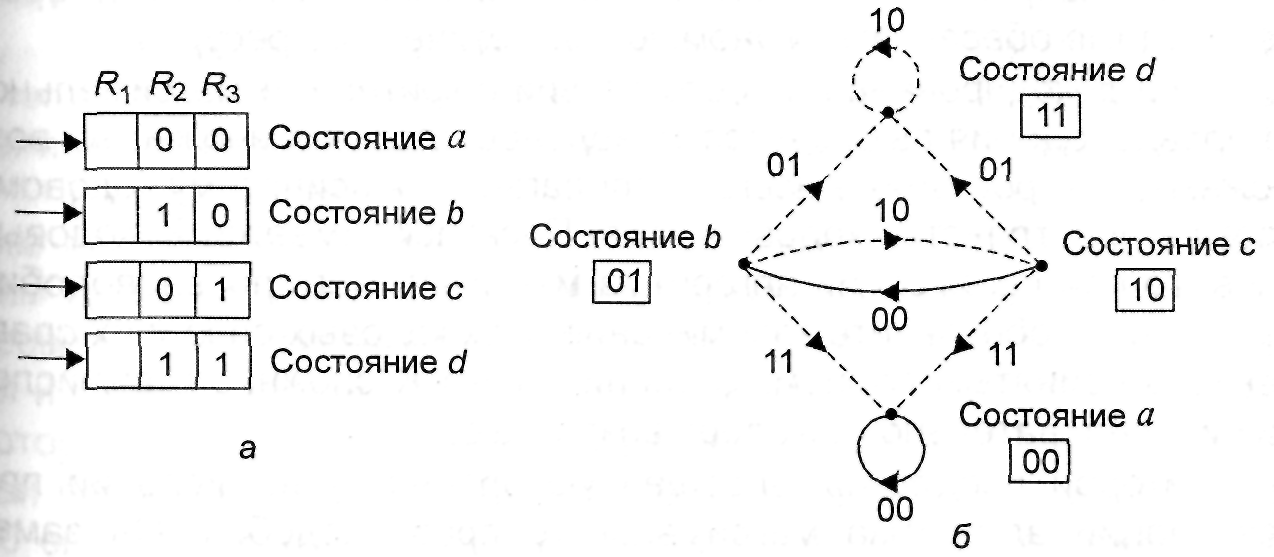
Рис. 3.6. Диаграмма состояний для кодера, изображенного на рис. 3.4
Другим полезным способом описания кодового дерева является решетчатая диаграмма, изображенная на рис. 3.7. Диаграмма берет начало из состояния а и на ней отображаются все возможные переходы при поступлении на вход очередного символа. Сплошным линиям соответствуют переходы, происходящие при поступлении символа 1 пунктирным – символа 0. При поступлении на вход двух символов кодер оказывается в одном из четырех состояний: a, b, c или d. Заметим, что решетчатая диаграмма имеет повторяющийся характер и может быть легко построена с помощью диаграммы состояний.
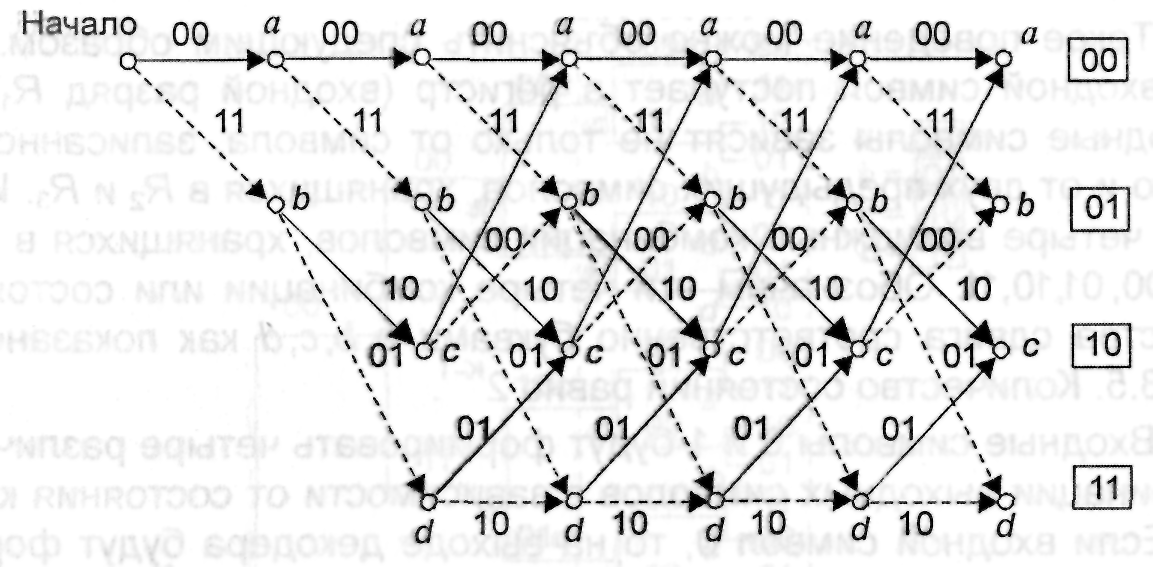
Рис. 3.7. Решетчатая диаграмма для кодера, изображенного на рис.3.4