

11. Нормальное распределение
Значения показателей (признаков) невозможно предугадать даже при полностью известных условиях эксперимента, в которых они измеряются.
Мы можем лишь указать вероятность того, что признак принимает то или иное значение.
Знание частоты встречаемости этих значений позволяет нам судить о распределении частот. Знание этого распределения исследуемого признака позволяет делать выводы о событиях, в которых участвует этот признак. Однако эти выводы тоже носят вероятностный или столастический характер.
Среди распределений есть такие распределения, которые встречаются на практике особенно часто. Эти распределения детально изучены и свойства их хорошо известны.
Наиболее распространенным распределением является нормальное распределение. Оно часто используется для приближенного описания многих случайных явлений, в которых на интересующий нас признак оказывает воздействие большое количество независимых случайных факторов, среди которых нет резко выделяющихся.
Нормальное распределение однозначно распределяется, если мы указываем значения двух его параметров: 1) среднее значение а; 2) дисперсии
2
( сигма). График нормального распределения называется кривой Гаусса и является симметричным относительно среднего значения а.
2
В ысота опред. , площадь под
2
кривой = 1. зависит от ширины.
а
Параметр а характеризует положение графика на плоскости и
2
называется поэтому параметром положения. Параметр характеризует степень сжатия или растяжения, поэтому он называется параметром
2
масштаба. Если среднее значение а=0, а дисперсия =1, то такое нормальное распределение называется стандартным. Рассмотренная в предыдущем параграфе процедура стандартизации исходных данных как раз и приводит к тому, что преобразованные данные z1, z2, …, zn имеют стандартное нормальное распределение.
График стандартного нормального распределения является симметричным относительно вертикальной координатной оси.

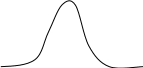

0
При обработке исходных данных иногда осуществляются преобразования с помощью арифметических операций. В результате этого возникает несколько новых видов распределения, связанных с нормальным.
Наиболее часто из таких распределений в статистике
2
рассматриваются следующие: 1) Х - распределение (хи-квадрат); 2) t – распределение Стьюдента; 3) F – распределение Фишера.
2
Х - распределение.
Оно определяется как сумма квадратов случайных величин, имеющих стандартное нормальное распределение.
2 2 2 2
Хn = Z1 + Z2 + ... +Zn
2
Х - распределение зависит от одного параметра, который называется числом степени свободы и обычно обозначается (ню). Этот параметр равен количеству суммируемых случайных величин.
=n
2
График Х распределения не является симметричным и расположен в положительной полуплоскости.

2
Среднее значение Х -распределения равно числу степен свободы (ню), а дисперсия равна 2 .
t – распределение Стьюдента.
Оно получается в результате деления частной величины, имеющей стандартное нормальное распределение на квадратный корень из случайной
2
величины, имеющей Х – распределение.
2
t = Z0: X :
t – распределение Стьюдента зависит от одного параметра – числа степеней свободы .
График этого распределения является симметричным относительно координатной вертикальной оси.
Е
 сли
> 30, то распределение Стьюдента
практически не отличается от стандартного
нормального распределения.
сли
> 30, то распределение Стьюдента
практически не отличается от стандартного
нормального распределения.
0
F – распределение Фишера. 2
Оно получается путем деления случайной величины, имеющей Х – распределение с числом степеней свободы 1 на случайную величину,
2
имеющую Х – распределение с числом степеней свободы 2.
2 2 2 2
F 1, 2 = (X 1: 1) : (X 2: 2) = ( 2 X 1) : ( 1 X 2)
F – распределение Фишера зависит от двух параметров: 1, 2.
График F – распределения не является симметричным и имеет вид :



Рассмотренные выше четыре распределения протабулированы, т.е. для них имеются соответствующие статистические таблицы.