

Лекція 5. Скінченні автомати і регулярні мови. Лема про роздування.
В цьому параграфі ми покажемо, що скінченні автомати розпізнають виключно регулярні мови.
5.1. теорема. Для формальної мови Ь наступні умови рівносильні:
- регулярна мова;
існує такий детермінований скінченний автомат А, що Ь(А)
Ь;
існує такий недетермінований скінченний автомат А, що Ь(А) = Ь;
мова Ь породжується деякою праволінійною граматикою.
Доведення. Рівносильність 2) ^ 3) доведена в теоремі 4.3, а імплікація 1) ^ 3) в твердженні 4.5.
3) ^ 1) Покажемо як побудувати регулярний вираз, що позначає мову, яка розпізнається даним недетермінованим скінченним автоматом А. Спершу, ми доведемо цей факт для помічених графів регулярних виразів, які розглядалися в параграфі 3. Нагадаємо, що помічений граф О має дві спеціальні вершини: початкову вершину ^ і кінцеву вершину Уу, і кожна стрілка графа позначена регулярним виразом. Для кожного шляху п з вершини Vі в вершину Уу через г(п) позначимо регулярний вираз гіг2 .. .Гк, утворений позначками стрілок з п:
![]()
Далі, для кожного поміченого графа О через Ь(О) позначимо формальну мову
![]()
Доведемо індукцією за кількістю вершин графа О, відмінних від уі і Уу, що для кожного поміченого графа О формальна мова Ь(О) є регулярною мовою.
База індукції: Для п = 0 граф О має тільки дві вершини Уі та Уу, або єдину вершину Уі = Уу. Спершу замінимо всі паралельні стрілки з позначками гі ,г2,... ,гт, які ідуть з вершини V в вершину V на одну стрілку з позначкою гі + г2 + ... + гт:
а
Ь![]()
![]()
а
Ь
Як наслідок отримаємо один з двох графів:
а с
-РИЗ
Ь
де а, Ь,с,З - регулярні вирази.
Очевидно, що для першого графа О регулярна мова Ь(О) = а*. Розглянемо другий граф і шлях п з у1 до у у. Припустимо, що шлях п проходить через вершину у у к > 1 разів. Тоді, шлях п можна подати як послідовність Пі п2 . . .Пк, де Пі - це шлях з У1 до У у, а п2, . . . ,Пк - такі шляхи з У1 до У у, що У у не є проміжною вершиною в будь- якому з шляхів п^, 1 < і < к. Очевидно, що г(п1) = агі Ь для деякого іі > 0 і, для і = 2,... ,к, вираз г(п^) дорівнює або с або Заг^ Ь для деякого і^ > 0, тобто г(п) Є а*Ь(с + За*Ь)*. Таким чином, для кожного регулярного виразу г в а*Ь(с + За*Ь)*, існує такий шлях п в графі О з вершини у1 до вершини у у, що г(п) = г. Отже, Ь(О) = а* Ь(с + За* Ь)* і база доведена.
Індуктивний крок: Для п > 1, оберемо вершину у, відмінну від у1 та у у, і вилучимо її наступним чином. Спершу, за методом, використаним в базі індукції, вилучимо паралельні стрілки. Таким чином, можна вважати, що існує не більше однієї стрілки з довільної вершини у в довільну вершину и. Далі, припустимо, що у має петлю з позначкою с. Видалимо вершину у разом з цією петлею. Для довільної пари (у,и) вершин графа О з стрілками у а > У , У Ь > и ,
у ^ > и , видалимо стрілки у ^ у і у ^ и і замінимо позначку З стрілки у ^ и новою позначкою З + ас* Ь (якщо не існує стрілки у ^ и в графі О, то вважаємо, що стрілка у ^ и має позначку 0). Дане перетворення показано на рисунку:

(Щоб зробити даний рисунок простішим для розуміння, ми опускаємо деякі стрілки з вершин, розташованих ліворуч, в вершини, розміщені праворуч. Вважамо, що стрілка, яка веде з і-тої вершини зліва до і-тої вершини справа, помічена символом ^.) Відмітимо, що дане перетворення не змінює формальної мови Ь. Таким чином, за індуктивним припущенням, мова, що розпізнається графом О є регулярною.
Вище доведено, що мови, породжені поміченим графом є регулярними. Наостанок, покажемо, що для довільного недетерміновано- го скінченного автомата А формальна мова Ь(А) є регулярною. Спершу перетворимо автомат А до рівносильного автомата А' з єдиним кінцевим станом /, замінюючи кінцеві стани в А на некінцеві стани, і додаючи новий кінцевий стан і нову кінцеву е-стрілку з кожного старого кінцевого стану до нового кінцевого стану /. Граф автомата А' є поміченим графом О, кожна стрілка якого позначена єдиним символом з множини {е} ЦІ X. Очевидно також, що Ь(О) = Ь(А'). Таким чином, з доведеного вище випливає, що Ь(А') - регулярна мова.
2) ^ 4) Нехай регулярна мова Ь розпізнається ДСА X, 5, д0 ,Р). Без втрати загальності, можна вважати, що ^ П X = 0. Побудуємо праволінійну граматику О = ( ^,Т, 8, Р), де N = Ц, Т = X, 8 = д0 і
Р = {д ^ ар | 5(д, а) = р} Ц {/ ^ е | / Є Р}.

частині не містять нетермінальних символів є / ^ е, де / Є Р, то вищезгадані виведення є єдиними в граматиці С. Таким чином, Ь = Ь(С).
4) ^ 3) Нехай С = (Ж, Т, 8, Р) - праволінійна граматика. Побудуємо помічений орієнтований граф наступним чином. Множина вершин співпадає з N Ц {/}, де / Є N. Стан 8 є початковим станом, а / - єдиним кінцевим станом автомата. Для кожної продукції в С виду А ^ шВ, де А, В Є N і ш Є Т* малюємо стрілку А В в графі, а для кожної продукції вигляду А ^ ш, де А Є N і ш Є Т* малюємо стрілку А /.
Легко бачити, що кожне виведення 8 ш граматики С відповідає шляху графа від початкової вершини 8 до кінцевої вершини /, позначки якого утворюють слово ш. Таким чином, мова, яка зображується даним поміченим графом, співпадає з мовою £(С). Оскільки кожному такому поміченому орієнтованому графу відповідає НСА, який розпізнає ту ж мову, то мова £(С) є регулярною.
□
5.2. Приклад. Побудуємо праволінійну граматику, яка породжується регулярною мовою, що розпізнається детермінованим скінченним автоматом, який заданий графом:
0
О

1 0,1
Визначимо граматику С = (^ Т, 8, Р), де N = {8, А, В, С}, Т = {0,1} і множина Р продукцій містить наступні правила:
8 ^ 0А | 1В, А ^ 0А | 1С, В ^ 0С | 1В, С ^ 0С | 1С | е.
5.3. Приклад. Побудуємо недетермінований скінченний автомат, який розпізнає мову, що породжується праволінійною граматикою С, яка
складається з наступних продукцій:
5 ^ 1А | 0В | 1, В ^ 0А | 1В, А ^ 0В І 0. Граф автомата матиме наступний вигляд:
о
і
Визначимо частку формальних мов Ьі і Ь2 наступним чином:
Ьі/Ь2 = {ш | Б Є )[ш» Є Ьі]}. Наприклад, якщо
Ьі = {ш Є {0,1}*} | ш містить парну кількість входжень 0}, Ь2 = {0} і Ь3 = {0, 00}, то Ьі/Ьз = {0,1}* і
^і= {ш Є {0,1}* | ш містить непарну кількість входжень 0}.
5.4. твердження. Якщо Ьі і Ь2 є регулярними мовами, то Ьі/Ь2 теж є регулярною мовою.
Доведення. Припустимо, що Ьі розпізнається ДСА А = (Я, X, 5, до,Р). Для слова ш Є Ьі/Ь2 існує таке слово V Є Ь2, що 5(до,шіу) = 5(5(до, ш), V) Є Р. Іншими словами, припустимо, що ми аналізуємо слово ш і пере- ходмио в стан ді = 5(до ,ш). Якщо існує таке V Є Ь2, що 5(ді^) Є Р, то слово ш розпізнається, тобто ді слід визначити кінцевим станом автомата для мови Ьі/Ь2. Таким чином, визначимо
Р' = {<1 Є Я | ^ Є Ь2) [5(д^) є Р]},
і покладемо А' = (Я, X, 5, до,Р'). Легко бачити, що А' розпізнає мову
Ьі/Ь2.
□
З теорем 5.1, 2.11 і 3.6 та твердження 5.4 випливає наступний наслідок:
наслідок. Клас регулярних мов замкнений відносно скінченних об'єднань, перетинів, доповнення, різниці, симетричної різниці, конкатенації, ітерації та частки.
З наслідку 5.5 випливає, що клас регулярних мов досить широкий. Природньо виникає питання: чи даний клас співпадає з класом усіх формальних мов? Наступна лема стверджує, що це не так.
Лема. (про роздування для регулярних мов) Нехай Ь - регулярна мова, тоді існує така (залежна від Ь) константа з, що кожне слово ш Є Ь, яке задовольняє нерівність |ш| > з, можна так розбити на три підслова ш = ав7, Що виконуються наступні умови:
а) |в| > 1;
б) |ав| < з;
в) для кожного к > 0 слово авк7 Є Ь, тобто ав*7 ^ Ь.
Доведення. Нехай Ь - регулярна мова, тоді згідно з теоремою 5.1 існує ДСА А, який розпізнає цю мову. Нехай кількість станів автомата А дорівнює з (константа, яка фігурує в формулюванні леми). Якщо ш Є X, то обчислювальний шлях для слова ш починається в початковому стані д0 і закінчується в кінцевому стані ду. Цей шлях містить |ш| стрілок, оскільки кожна стрілка позначена єдиною буквою слова ш. Таким чином, він містить послідовність з |ш| + 1 станів. Оскільки |ш| > з, то деякий стан в обчислювальному шляху, згідно принципу Діріхле, обов'язково повториться двічі. Нехай дік = ді; - перший повторюваний стан при аналізі слова ш.

Позначимо через в ту частину слова ш, яка складається з букв, які позначають стрілки підшляху від першого входження стану дік до другого входження стану ді; = дік в обчислювальний шлях слова ш.
Позначимо через а частину слова и перед в, а через 7 - його частину після в. Очевидно, що |в| > 1 та |ав| < 5 (оскільки всі стани до другої появи дік різні). Більше того, слово авк7 для будь-якого цілого невід'ємного числа к має переводити автомат у той самий заключний стан, що й слово ав7. Справді, частина вк слова авк7 просто переводить стани автомата А вздовж петлі, яка починається та закінчується в стані дік. Ця петля проходить к разів. Звідси випливає, що автомат А розпізнає слова авк 7, оскільки він розпізнає слово ав7. Тому всі такі слова належать мові Ь.
□
Приклад. Доведемо, що мова {0т 1т | т = 0,1,...} нерегулярна.
Припустимо, що мова Ь є регулярною. Нехай слово и = 0т 1т і |и | = 2т > п. Тоді за лемою про роздування слова и = 0т 1т = ав7 та авк7 належать мові Ь, причому в = е. Слово в не може містити водночас нулі й одиниці, бо тоді слово в2 містило би 10, і слово ав27 не належало б мові Ь. Отже, слово в складається або виключно з нулів, або тільки з одиниць. Але тоді слово ав27 містить або забагато нулів, або забагато одиниць. Звідси випливає, що слово ав27 не належить мові Ь. Ця суперечність доводить, що мова Ь = {0т 1т | т = 0,1,...} нерегулярна.
Приклад. Покажемо, що мова {0Р | р— просте число } не є регулярною.
Припустимо, що Ь = {0Р | р— просте число } є регулярною мовою. Тоді, Ь розпізнається ДСА. Нехай 5 - кількість станів автомата. Зафіксуємо просте число р > 5. Відмітимо, що 0Р Є Ь і |0Р | = р > 5. Таким чином, за лемою про роздування, 0Р можна записати як 0Р = ав7, причому |в | > 1 і ав * 7 С Ь.
Нехай і = |а| + |71 та і = |в |. Тоді, з умови ав * 7 С Ь випливає, що для кожного к > 0, слово авк7 = 0і+к^ Є Ь, тобто для кожного к > 0, число і + к_ї є простим. Зокрема, при к = 0, маємо, що і є простим числом. Отже, і > 2. Поклавши к = і, отримаємо, що і(1 + І) - просте число. Тим не менше, оскільки в = е, то з того, що
І = |вІ — 1, випливає, що і(1 + і) є складеним. Дана суперечність доводить нергулярність мови Ь = {0Р | р— просте число }.
5.9. Приклад. Доведемо, що мова {0т | т— складене число } нерегулярна.
Припустимо, що дана мова Ь = {0т | т— складене число } є регулярною, тоді з наслідку 5.5 випливає, що мови Ь та Ь \ {0} = {0Р | р— просте число } є регулярними, що суперечить прикладу 5.8.
Вправи до лекції 5.
Довести або спростувати твердження:
а) якщо мова А є регулярною і А С В, то мова В теж є регулярною;
б) якщо мова А є регулярною і В С А, то мова В - регулярна;
в) якщо мова А2 є регулярною, то мова А є регулярною;
г) якщо мови А і АВ є регулярними, то мова В також регулярна;
д) якщо мови А і В є регулярними, то мова (Аг П Вг) теж є регулярною.
З'ясувати, чи є регулярними наступні формальні мови:
{02п 1П | п — 0};
{02П | п — 0};
{0П1П2П | п — 0};
{02п | п — 0};
{0п2 | п — 0};
{0т 1п | т = п};
{0Р9 | р, д — прості числа ;
{0т 1П | т, п — 0 т = 2п + 1};
{0т 1п | т, п — 0, т = 3п + 1};
{апЬтск | п, т, к — 0, п = т або т = к або к = п};
{шшй | ш Є {0,1}+}.
Лекція 6. Автомати з магазинною пам'яттю
Автомат з магазинною пам'яттю (МП-автомат) - це скінченний недетермінований автомат без виходу, що має додатковий пристрій пам'яті типу стек і головку стеку, яка виймає і заносить дані у стек. У стеці кожен елемент інформації заноситься в верхню комірку пам'яті, зміщуючи тим самим весь її вміст на одну комірку вниз, і дістається тільки із верхньої комірки пам'яті, зміщуючи тим самим весь її вміст на одну комірку вгору. При цьому, у кожний момент часу доступний тільки верхній елемент стеку. Теоретично, об'єм пам'яті МП-автомата не обмежений. Схема МП-автомата має вигляд:
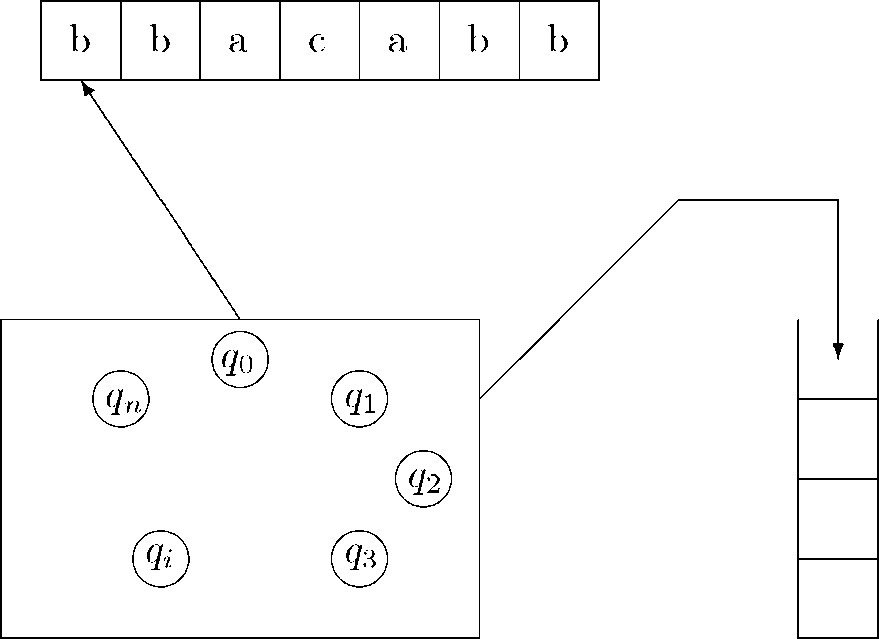
6.1. ОЗНАЧЕННЯ. Автомат з магазинною пам'яттю - це шестірка М = ^,Х,2,5,д0,Р), де X, до і Р визначаються так само як і в НСА, % - скінченна множина допустимих букв пам'яті, а 5 - функція переходів:
5 : ^ х (X ЦІ {е}) х (% Ці {е}) ^ и{е}).
Для д Є Я, а Є X і и Є % команда (р, V) Є 5(д,а,и) означає, що коли МП-автомат М пребуває в стані д, зчитує з стрічки букву а і виймає зі стеку верхню букву и, то він замінює букву стеку и на букву V, головка стрічки переміщується на одну букву праворуч і керуючий
пристрій переводить автомат в стан р. Розглянемо випадки, коли V або и дорівнює е. Якщо V = е, тобто (р, е) Є 5(д, а, и), то МП-автомат просто видаляє верхню букву и стеку, не читаючи при цьому нової букви стеку. У випадку, коли и = е, тобто (р, V) Є 5(д,а,е), МП- автомат заносить в стек букву V, не чіпаючи при цьому верхньої букви стеку. Також можливий випадок, коли а = е, тобто (р, V) Є 5(д,е,и). Ця команда аналогічеа е-тактам НСА, тобто МП-автомат М виконує операцію як і у випадку (р, V) Є 5(д, а,и), але при цьому не зчитує букви зі стрічки (головка стрічки не зміщується праворуч).
На початку роботи МП-автомат М = ^,Х,2,5,до ,Р) завжди перебуває в початковому стані до, його стек порожній і головка стрічки аналізує першу зліва букву, записану на стрічці. Вважається, що МП-автомат М розпізнає вхідне слово, якщо хоча б в одному з обчи- сювальних шляхів він повністю проаналізовує слово, має порожній стек і перебуває в кінцевому стані д Є Р. Через Ь(М) позначається мова, яка складається зі всіх слів, які розпізнаються автоматом М.
6.2. Приклад. Розглянемо МП-автомат М = ({^,р}, {а, Ь, с}, {а, Ь}, 5, д, {р} де функція переходів 5 задається наступним чином:
5(д, а, е) = {(д, а)}, 5(р, а, а) = {(р, е)}, 5(д, Ь, е) = {(д, Ь)},
5(Р, Ь, Ь) = 5(^ ^ е) = е)}.
Знайти мову Ь(М).
Цей автомат працює наступним чином. В початковому стані д він заносить букви а та Ь в стек доти, доки головка стрічки не знайде букву с. Далі, після аналізу букви с, він переходить в стан р. В стані р автомат М порівнює кожну букву стрічки з верхньою буквою стеку і, якщо всі вони рівні, то машина розпізнає вхідне слово.
Нехай и Є {а, Ь}* - префікс вхідного слова перед першим входженням букви с і V - суфікс вхідного слова після першого входження с. Відмітимо, що в той час, коли МП-автомат переходить в стан р, слово и записане в стеці в оберненому порядку (перша буква слова и записана вкінці стеку, а остання буква - на верху стеку). Таким чином, коли автомат порівнює суфікс V з буквами стеку, то спершу порівнюється перша буква слова V з останньою буквою слова и і т.д. Отже, вхідне слово розпізнається тільки у випадку, коли V = иЕ, тобто Ь(М) = {иси | и Є {а,Ь}*}.
Щоб краще зрозуміти як автомат працює, введемо поняття конфігурації МП-автомата. Конфігурація - це запис інформації про роботу автомата на певному кроці аналізу вхідного слова, який включає активний стан, букви стрічки, які ще не проаналізовані, і символи, які на даний момент є в стеку. Отже, конфігурація МП-автомата М = X, 2, д0, Р) є елементом декартового добутку ^ х X* х 2*. Конфігурація (д, х, 7) означає, що МП-автомат перебуває в стані д, непроаналізований суфікс вхідного слова дорівнює х (головка стрічки аналізує першу букву слова х) і стек містить слово 7 (перша буква слова 7 є верхньою буквою стеку).
Нехай (д, ші, в) і (р, ш2, 7) - дві конфігурації. Кажемо, що (р, ш2,7) слідує за (д,ш1, в) і записуємо (д,ш1, в) Ь (р, ш2,7), якщо існує така інструкція (р, V) Є £(д, а, п), що ш1 = аш2 і в = ^а, 7 = ^а для деякого слова а Є X*, де а, п, V можуть дорівнювати порожньому слову е. Будемо записувати (д,ш1, в) Ь* (р, ш2,7), якщо існує така послідовність конфігурацій С0, С1,..., Сп, що С0 = (д,ш1, в), Сп = (р, ш2,7) і Сі Ь Сі+1 для всіх і = 0,1,..., п — 1. Послідовність (С0, С1,..., Сп) конфігурацій МП-автомата М називається обчислювальним шляхом автомата М, якщо С0 є початковою конфігурацією (з,ш1, е), Сп не має наступної конфігурації і Сі Ь Сі+1 для всіх і = 0,1,... ,п — 1. Нагадаємо, що в загальному випадку, М є недетермінованим автоматом, а тому може бути багато обчислювальних шляхів, які починаються з початкової конфігурації. Крім того, конфігурація (д, ш1, в) може не мати наступної конфігурації, навіть, якщо ш1 = е. Таким чином, МП-автомат М розпізнає слово ш1 тоді і лише тоді, коли існує обчислювальний шлях автомата М, який починається з початкової конфігурації (з, х, е) і закінчується конфігурацією (/, е, е) для деякого кінцевого стану / Є Р, тобто
£(М) = {ш Є X* | (З/ Є Р)[(з,х,е) Ь* (/, е, е)]}.
Наприклад, розглянемо три обчислювальні шляхи МП-автомата М з прикладу 6.2 для слів а6с6а, а6с6 і а6с6а6 відповідно:
(д, а6с6а, е) Ь (д, 6с6а, а) Ь (д, с6а, 6а) Ь (р, 6а, 6а) Ь (р, а, а) Ь (р, е, е); (д, абсб, е) Ь (д, 6с6, а) Ь (д, сб, 6а) Ь (р, 6, 6а) Ь (р, е, а); (д, а6с6а6, е) Ь (д, 6с6а6, а) Ь (д, с6а6, 6а) Ь (р, 6а6, 6а) Ь (р, а6, а) Ь (р, 6, е).
Відмітимо, що другий обчислювальний шлях автомата М не є розпізнавальним, оскільки стек не стає порожнім після того як слово
проаналізоване автоматом. Третій шлях теж не розпізнає вхідного слова, оскільки після (р, Ь, е) не існує наступної конфігурації, а вхідне слово ще не проаналізовано повністю.
Аналогічно як і НСА, МП-автомат зображується графом. Вершини графа є станами автомата, а кожна стрілка з вершини д в вершину р з позначкою "а,и/у" зображує перхід (р, у) Є 5(д,а,и). Наприклад, граф автомата з прикладу 6.2 має вигляд:
Ь,
е/Ь а, е/а
Ь,
Ь/е а,
а/е