

2.1 Ошибки систематические и случайные
Поскольку выборка охватывает, как правило, весьма незначительную часть генеральной совокупности, то следует предполагать, что будут иметь место различия между оценкой и характеристикой генеральной совокупности, которую эта оценка отображает. Эти различия получили название ошибок отображения или ошибок репрезентативности. Ошибки репрезентативности подразделяются на два типа: систематические и случайные.
Систематические ошибки - это постоянное завышение или занижение значения оценки по сравнению с характеристикой генеральной совокупности. Причиной появления систематической ошибки является несоблюдение принципа равновероятности попадания каждой единицы генеральной совокупности в выборку, то есть выборка формируется из преимущественно «худших» (или «лучших») представителей генеральной совокупности. Соблюдение принципа равновозможности попадания каждой единицы в выборку позволяет полностью исключить этот тип ошибок.
Случайные ошибки – это меняющиеся от выборки к выборке по знаку и величине различия между оценкой и оцениваемой характеристикой генеральной совокупности. Причина возникновения случайных ошибок - игра случая при формировании выборки, составляющей лишь часть генеральной совокупности. Этот тип ошибок органически присущ выборочному методу. Исключить их полностью нельзя, задача состоит в том, чтобы предсказать их возможную величину и свести их к минимуму. Порядок связанных в связи с этим действий вытекает из рассмотрения трех видов случайных ошибок: конкретной, средней и предельной.
2.2 Конкретная, средняя и предельная ошибки выборки
2.2.1 Конкретная
ошибка – это ошибка одной проведенной
выборки. Если средняя по этой выборке
(
![]() ) является оценкой для генеральной
средней (
0
) и, если предположить, что эта генеральная
средняя нам известна, то разница
) является оценкой для генеральной
средней (
0
) и, если предположить, что эта генеральная
средняя нам известна, то разница
![]() =
=![]() -
0
и будет конкретной ошибкой этой выборки.
Если из этой генеральной совокупности
выборку повторим многократно, то каждый
раз получим новую величину конкретной
ошибки:
-
0
и будет конкретной ошибкой этой выборки.
Если из этой генеральной совокупности
выборку повторим многократно, то каждый
раз получим новую величину конкретной
ошибки:
![]() …,
и так далее. Относительно этих конкретных
ошибок можно сказать следующее: некоторые
из них будут совпадать между собой по
величине и знаку, то есть имеет место
распределение ошибок, часть из них
будет равна 0, наблюдается совпадение
оценки и параметра генеральной
совокупности;
…,
и так далее. Относительно этих конкретных
ошибок можно сказать следующее: некоторые
из них будут совпадать между собой по
величине и знаку, то есть имеет место
распределение ошибок, часть из них
будет равна 0, наблюдается совпадение
оценки и параметра генеральной
совокупности;
2.2.2 Средняя
ошибка – это средняя квадратическая
из всех возможных по воле случая
конкретных ошибок оценки :
 ,
где
,
где
![]() - величина меняющихся конкретных
ошибок;
- величина меняющихся конкретных
ошибок;
![]() частота
( вероятность ) встречаемости той или
иной конкретной ошибки. Средняя ошибка
выборки показывает насколько в среднем
можно ошибиться, если на основе оценки
делается суждение о параметре
генеральной совокупности. Приведенная
формула раскрывает содержание средней
ошибки, но она не может быть использована
для практических расчетов, хотя бы
потому, что предполагает знание параметра
генеральной совокупности, что само по
себе исключает необходимость выборки.
частота
( вероятность ) встречаемости той или
иной конкретной ошибки. Средняя ошибка
выборки показывает насколько в среднем
можно ошибиться, если на основе оценки
делается суждение о параметре
генеральной совокупности. Приведенная
формула раскрывает содержание средней
ошибки, но она не может быть использована
для практических расчетов, хотя бы
потому, что предполагает знание параметра
генеральной совокупности, что само по
себе исключает необходимость выборки.
Практические
расчеты средней ошибки оценки основываются
на той предпосылке, что она (средняя
ошибка) по сути, является средним
квадратическим отклонением всех
возможных значений оценки. Эта предпосылка
позволяет получить алгоритмы расчета
средней ошибки, опирающиеся на данные
одной единственной выборки. В частности
средняя ошибка выборочной средней
может быть установлена на основе
следующих рассуждений. Имеется выборка
(
,
…
) состоящая из
единиц. По выборке в качестве оценки
генеральной средней определена
выборочная средняя
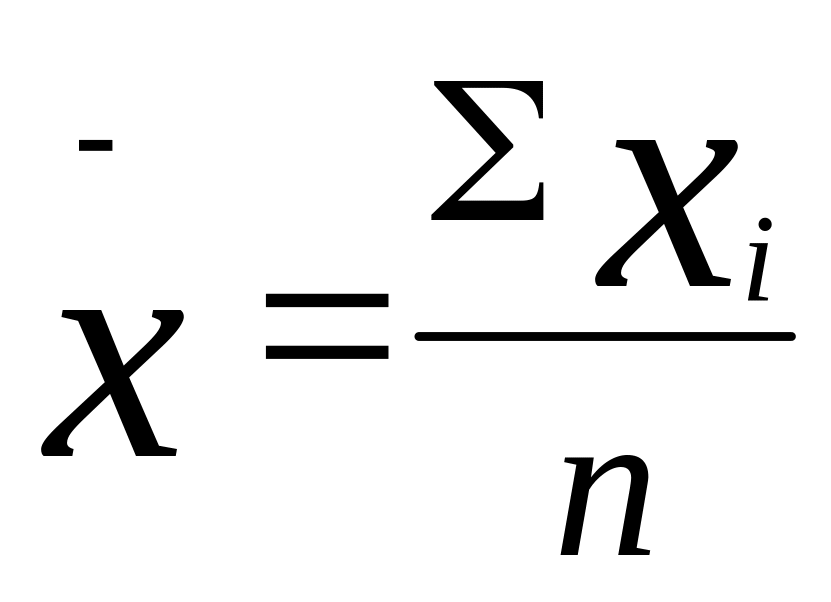 .
Каждое значение
.
Каждое значение![]() (
,
…
) , стоящее под знаком суммы, следует
рассматривать как независимую случайную
величину, поскольку при бесконечном
повторении выборки первая, вторая и
т.д. единицы могут принимать любые
значения из присутствующих в генеральной
совокупности. Следовательно
(
,
…
) , стоящее под знаком суммы, следует
рассматривать как независимую случайную
величину, поскольку при бесконечном
повторении выборки первая, вторая и
т.д. единицы могут принимать любые
значения из присутствующих в генеральной
совокупности. Следовательно
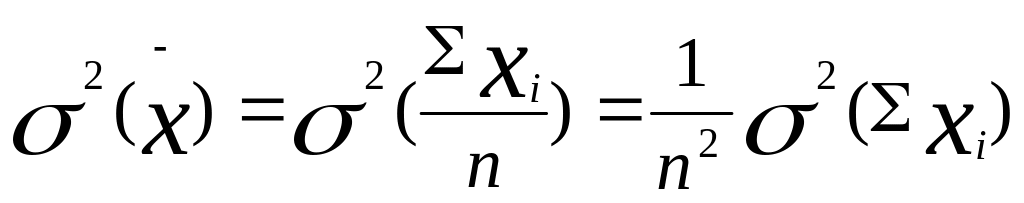 Поскольку, как известно, дисперсия суммы
независимых случайных величин равна
сумме дисперсий, то
Поскольку, как известно, дисперсия суммы
независимых случайных величин равна
сумме дисперсий, то
![]()
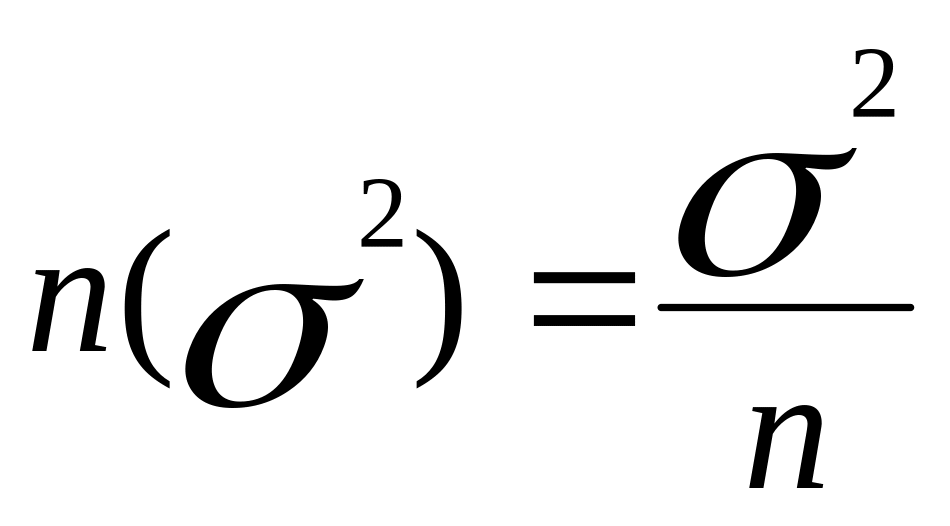 .
Отсюда следует, что средняя ошибка
для выборочной средней будет равная
.
Отсюда следует, что средняя ошибка
для выборочной средней будет равная
![]() и находится она в обратной зависимости
от численности выборки (через корень
квадратный из нее) и в прямой от среднего
квадратического отклонения признака
в генеральной совокупности. Это
логично, поскольку выборочная средняя
является состоятельной оценкой для
генеральной средней и по мере увеличения
численности выборки приближается по
своему значению к оцениваемому параметру
генеральной совокупности. Прямая
зависимость средней ошибки от колеблемости
признака обусловлена тем, что чем больше
изменчивость признака в генеральной
совокупности, тем сложнее на основе
выборки построить адекватную модель
генеральной совокупности. На практике
среднее квадратическое отклонение
признака по генеральной совокупности
заменяется его оценкой по выборке, и
тогда формула для расчета средней
ошибки выборочной средней приобретает
вид:
и находится она в обратной зависимости
от численности выборки (через корень
квадратный из нее) и в прямой от среднего
квадратического отклонения признака
в генеральной совокупности. Это
логично, поскольку выборочная средняя
является состоятельной оценкой для
генеральной средней и по мере увеличения
численности выборки приближается по
своему значению к оцениваемому параметру
генеральной совокупности. Прямая
зависимость средней ошибки от колеблемости
признака обусловлена тем, что чем больше
изменчивость признака в генеральной
совокупности, тем сложнее на основе
выборки построить адекватную модель
генеральной совокупности. На практике
среднее квадратическое отклонение
признака по генеральной совокупности
заменяется его оценкой по выборке, и
тогда формула для расчета средней
ошибки выборочной средней приобретает
вид:![]() ,
при этом учитывая смещенность выборочной
дисперсии
,
при этом учитывая смещенность выборочной
дисперсии
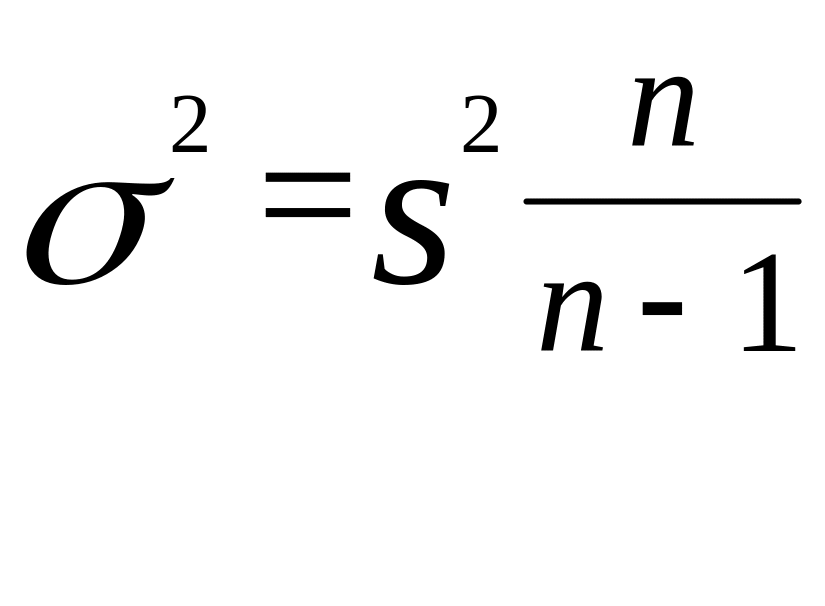 ,
выборочное среднее квадратическое
отклонение рассчитывается по формуле
,
выборочное среднее квадратическое
отклонение рассчитывается по формуле
![]()
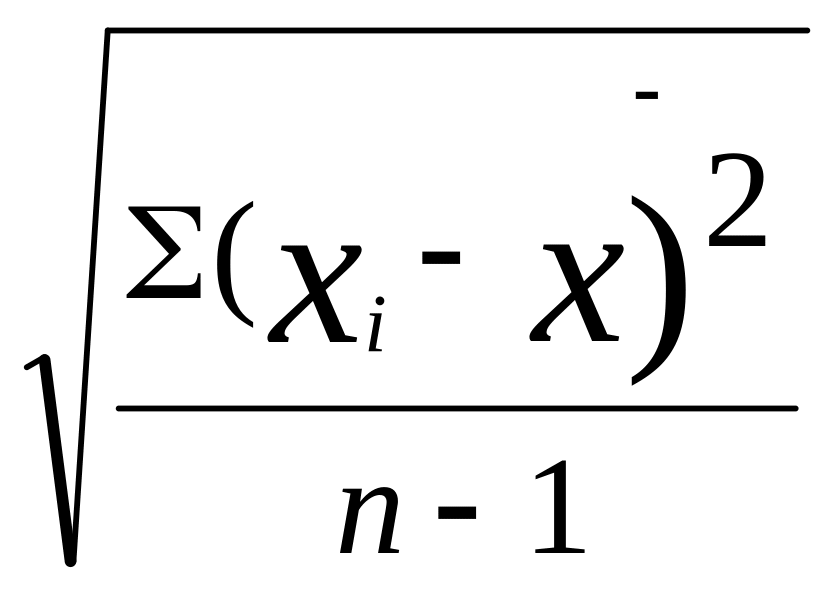 =
=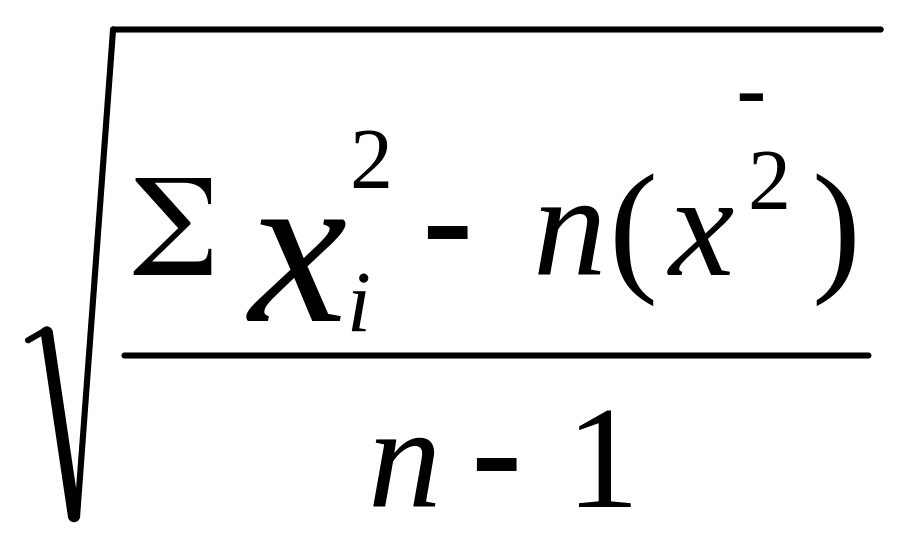 .
Так как символом n
обозначена численность выборки, то в
знаменателе при расчете среднего
квадратического отклонения должна
использоваться не численность выборки
(n), а так называемое число
степеней свободы (n-1).
Под числом степеней свободы понимается
число единиц в совокупности, которые
могут свободно варьировать (изменяться),
если по совокупности определена
какая-либо характеристика. В нашем
случае, поскольку по выборке определена
ее средняя, свободно варьировать могут
.
Так как символом n
обозначена численность выборки, то в
знаменателе при расчете среднего
квадратического отклонения должна
использоваться не численность выборки
(n), а так называемое число
степеней свободы (n-1).
Под числом степеней свободы понимается
число единиц в совокупности, которые
могут свободно варьировать (изменяться),
если по совокупности определена
какая-либо характеристика. В нашем
случае, поскольку по выборке определена
ее средняя, свободно варьировать могут
![]() единицы.
единицы.
В таблице 2.2
приведены формулы для расчета средних
ошибок различных выборочных оценок.
Как видно из этой таблицы, величина
средней ошибки по всем оценкам находится
в обратной связи с численностью выборки
и в прямой с колеблемостью. Это можно
сказать и относительно средней ошибки
выборочной доли ( частости ). Под корнем
стоит дисперсия альтернативного
признака, установленная по выборке (
![]() )
)
Приведенные в таблице 2.2 формулы относятся к так называемому случайному , повторному отбору единиц в выборку. При других способах отбора , о которых речь пойдет ниже, формулы будут несколько видоизменяться.
Таблица 2.2 Формулы для расчета средних ошибок выборочных оценок
Выборочные оценки |
Формулы для расчета средней ошибки выборочной оценки |
Выборочная
средняя (
|
|
Выборочная
дисперсия
(
|
|
Выборочное среднее квадратическое отклонение ( s ) |
|
Выборочная доля (w ) |
|
2.2.3 Предельная ошибка выборки Знание оценки и ее средней ошибки в ряде случаев совершенно недостаточно. Например, при использовании гормонов при кормлении животных знать только средний размер неразложившихся их вредных остатков и среднюю ошибку, значит подвергать потребителей продукции серьезной опасности. Здесь настоятельно напрашивается необходимость определения максимальной (предельной ошибки). При использовании выборочного метода предельная ошибка устанавливается не в виде конкретной величины, а виде равных границ (интервалов) в ту и другую сторону от значения оценки.
Определение
границ предельной ошибки основывается
на особенностях распределения конкретных
ошибок. Для так называемых больших
выборок, численность которых более 30
единиц (![]() ),
конкретные ошибки распределяются в
соответствии с нормальным законом
распределения; при малых выборках (
),
конкретные ошибки распределяются в
соответствии с нормальным законом
распределения; при малых выборках (![]() )
конкретные ошибки распределяются в
соответствии с законом распределения
Госсета (Стьюдента). Применительно к
конкретным ошибкам выборочной средней
функция норм0ального распределения
имеет вид:
)
конкретные ошибки распределяются в
соответствии с законом распределения
Госсета (Стьюдента). Применительно к
конкретным ошибкам выборочной средней
функция норм0ального распределения
имеет вид:
 ,
где
,
где
![]() - плотность вероятности появления тех
или иных значений
- плотность вероятности появления тех
или иных значений
![]() ,
при условии, что
,
при условии, что
![]()
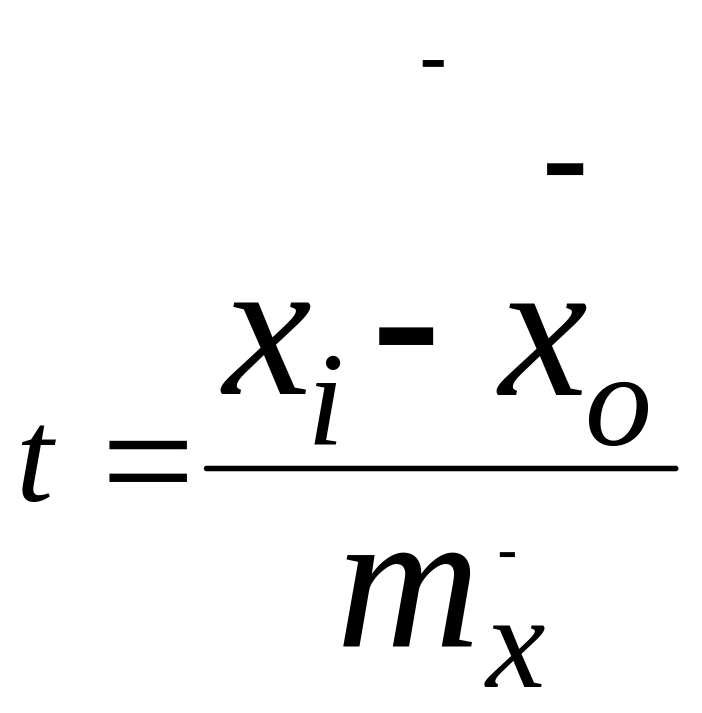 ,
где
,
где
![]() выборочные средние;
выборочные средние;
![]() -
генеральная средняя,
-
генеральная средняя,
![]() - средняя ошибка для выборочной
средней. Поскольку средняя ошибка (
)
является величиной постоянной, то в
соответствии с нормальным законом
распределяются конкретные ошибки
- средняя ошибка для выборочной
средней. Поскольку средняя ошибка (
)
является величиной постоянной, то в
соответствии с нормальным законом
распределяются конкретные ошибки
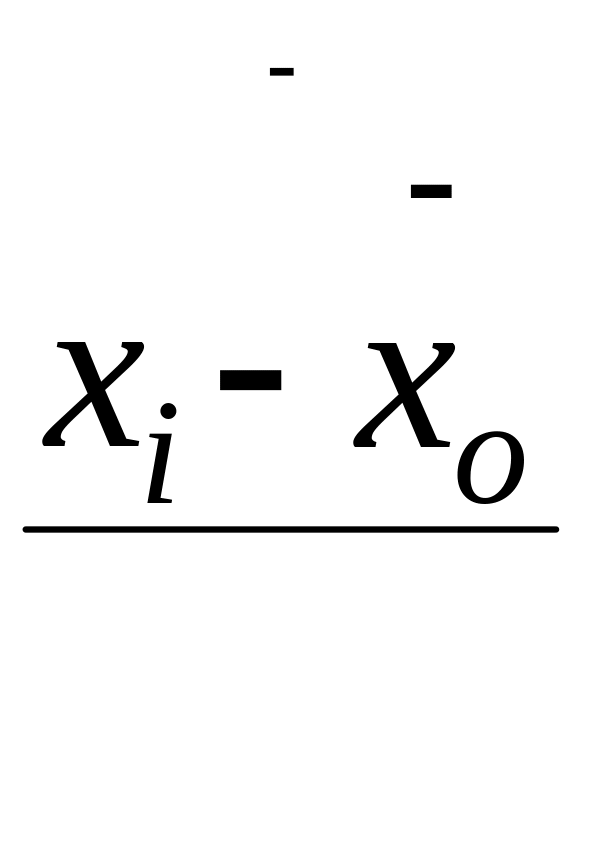 ,
выраженные в долях средней ошибки, или
так называемых нормированных отклонениях.
,
выраженные в долях средней ошибки, или
так называемых нормированных отклонениях.
Взяв интеграл функции нормального распределения, можно установить вероятность того, что ошибка будет заключена в некотором интервале изменения t и вероятность того, что ошибка выйдет за пределы этого интервала (обратное событие). Например, вероятность того, что ошибка не превысит половину средней ошибки (в ту и другую сторону от генеральной средней) составляет 0,3829, что ошибка будет заключена в пределах одной средней ошибки - 0,6827, 2-х средних ошибок -0,9545 и так далее.
Взаимосвязь между уровнем вероятности и интервалом изменения t (а в конечном счете интервалом изменения ошибки) позволяет подойти к определению интервала (или границ) предельной ошибки, увязав его величину с вероятностью осуществления. Вероятность осуществления - это вероятность того, что ошибка будет находиться в некотором интервале. Вероятность осуществления будет «доверительной» в том случае, если противоположное событие (ошибка будет находиться вне интервала) имеет такую вероятность появления, которой можно пренебречь. Поэтому доверительный уровень вероятности устанавливают, как правило, не ниже 0,90 (вероятность противоположного события равна 0,10). Чем больше негативных последствий имеет появление ошибок вне установленного интервала, тем выше должен быть доверительный уровень вероятности (0,95; 0,99; 0,999 и так далее).
Выбрав доверительный
уровень вероятности по таблице интеграла
вероятности нормального распределения,
следует найти соответствующее значение
t, а затем используя
выражение
=
![]() определить интервал предельной ошибки
определить интервал предельной ошибки
![]() .
Смысл полученной величины в следующем
– с принятым доверительным уровнем
вероятности предельная ошибка выборочной
средней не превысит величину
.
Смысл полученной величины в следующем
– с принятым доверительным уровнем
вероятности предельная ошибка выборочной
средней не превысит величину
![]() .
.
Для установления границ предельной ошибки на основе больших выборок для других оценок (дисперсии, среднего квадратического отклонения, доли и так далее) используется выше рассмотренный подход, с учетом того, что для определения средней ошибки для каждой оценки используется свой алгоритм.
Что касается
малых выборок (
)
то, как уже говорилось, распределение
ошибок оценок соответствует в этом
случае распределению t
- Стьюдента. Особенность этого распределения
состоит в том, что в качестве параметра
в нем , наряду с ошибкой, присутствует
численность выборки ,вернее не численность
выборки, а число степеней свободы
![]() .
При увеличении численности выборки
распределение t-Стьюдента
приближается к нормальному, а при
эти распределения практически совпадают.
Сопоставляя значения величины
t-Стьюдента и t
- нормального распределения при одной
и той же доверительной вероятности
можно сказать, что величина t-Стьюдента
всегда больше t - нормального
распределения, причем, различия
возрастают с уменьшением численности
выборки и с повышением доверительного
уровня вероятности. Следовательно, при
использовании малых выборок имеют
место по сравнению с выборками большими,
более широкие границы предельной
ошибки, причем, эти границы расширяются
с уменьшением численности выборки и
повышением доверительного уровня
вероятности.
.
При увеличении численности выборки
распределение t-Стьюдента
приближается к нормальному, а при
эти распределения практически совпадают.
Сопоставляя значения величины
t-Стьюдента и t
- нормального распределения при одной
и той же доверительной вероятности
можно сказать, что величина t-Стьюдента
всегда больше t - нормального
распределения, причем, различия
возрастают с уменьшением численности
выборки и с повышением доверительного
уровня вероятности. Следовательно, при
использовании малых выборок имеют
место по сравнению с выборками большими,
более широкие границы предельной
ошибки, причем, эти границы расширяются
с уменьшением численности выборки и
повышением доверительного уровня
вероятности.
Резюме по модульной единице 2
Использование выборочного метода неизбежно сопряжено с появлением ошибок. Случайный характер этих ошибок, нормальный или t - Стьюдента закон их распределения позволяет определить их средний и предельный размер и видеть пути их снижения
Модульная единица 3 Типовые задачи, решаемые на основе выборочного метода