

39.Статистический метод распознавания.
Статистический подход к распознаванию образов можно использовать в тех случаях, когда имеющихся сведений недостаточно для описания o6разов или классов, которые, возможно, содержатся в рассматриваемом наборе данных. В таких обстоятельствах выходом из положения может оказаться применение статистических методов для анализа, что позволяет использовать всю имеющуюся априорную информацию. Иногда необходимо провести и проанализировать новые наблюдения. Представление этих данных на статистическом языке (в виде, например, плотностей распределения, вероятностей) иногда оказывается чрезвычайно затруднительным. Если эти трудности не удается преодолеть удовлетворительным образом, то можно воспользоваться многошаговой процедурой, при реализации которой попеременно используются статистический, «физический» и эвристический подходы.
Исходным материалом для применения статистической процедуры служит некоторый набор объектов, каждый из которых задается некоторым набором значений признаков. Необходимы априорные сведения, касающиеся возможных плотностей распределения назначений признаков, адекватности признаков и т. д. При статистическом подходе совершенно безразлично, являются ли объекты распознавания реальными физическими объектами либо такими «нефизическими» категориями, как «социальное поведение» или «экономический прогресс», если все они допускают единообразное представление через признаки.
Рассмотрим дискриминантный метод анализа данных: строятся функции, зависящие от признаков и обеспечивающие оптимальное в некотором смысле разделение объектов, относящихся к разным классам.
Статистические методы формирования дискриминантной функции, разделяющей два или несколько классов объектов, основывается основываются главным образом на минимизации оценки ошибки классификации.
Эта ошибка (ε) представляет собой вероятность неправильной классификации поступившего на распознавание произвольного k-мерного объекта х:
 (4.1)
(4.1)
где L
— число классов; D(x)
—функция, выносящая классификационное
решение (может принимать одно из значений
1,
2, ...,
l,
..., L),
и pl=prob(х![]() классу
l)—
априорная вероятность принадлежности
произвольного объекта х
классу l.
Выражение prob
(a\b)
обозначает вероятность совершения
события а
при выполнении условия b.
классу
l)—
априорная вероятность принадлежности
произвольного объекта х
классу l.
Выражение prob
(a\b)
обозначает вероятность совершения
события а
при выполнении условия b.
40.Структурные (лингвистические) методы распознавания.
Для этих задач характерной особенностью является то, что распознаваемые объекты, принадлежащие разным классам, зачастую не могут быть расположены произвольным образом, т.е. имеется некая структура, охватывающая эти объекты. Кроме того, и сами объекты образованы из некоторых элементарных частей отнюдь не произвольным образом, а в соответствии с некоторой схемой, или, как мы буде говорить, обладают структурой. На рис. 4.4 изображен пример видеоизображения, на котором представлены объекта из двух различных классов. Здесь N есть задняя стена, М есть пол, на котором стоят объекты D и Е. У объекта D видны грани L и Т. Грань L — прямоугольная, грань Т — треугольная. У объекта Е видны грани X, Y и Z. Все грани — прямоугольные.
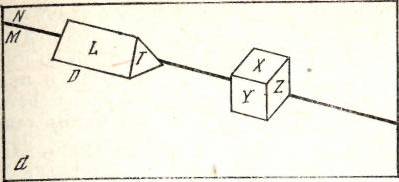
Рис. 4.4. Пример видеоизображения
Структурность всего видеоизображения заключается в том, что объекты D и Е расположены определенным образом друг относительно друга и относительно стены N и пола М. Структурность объекта D заключается в том, что он составлен из треугольных и прямоугольных граней, структурность объекта Е заключается в том, что он составлен только из прямоугольных граней.
Подход, используемый для представления иерархической структурной информации, содержащейся в каждом объекте, т.е. для описания объекта при помощи более простых подобъектов, которые, в свою очередь, описываются еще более простыми подобъектами, и т. д., будем называть структурным подходом к распознаванию образов. Этот подход основан на аналогии между структурой объектов и синтаксисом языка. В рамках этого подхода считается, что объекты состоят из соединенных различными способами подобъектов так же, как фразы и предложения строятся путем соединения слов, а слова составляются из букв. Очевидно, что, для того чтобы такой подход был полезен, наипростейшие подобъекты, называемые примитивами, должны распознаваться проще, чем сами образы. Отметим, что распознавание примитивов должно осуществляться уже обычными, неструктурными методами. Язык, который обеспечивает структурное описание объектов в терминах наборов примитивов и операций их объединения, называют языком описания образов. Правила композиции примитивов даются обычно так называемой грамматикой описания образов. После того как каждый примитив объекта идентифицирован, процесс распознавания завершается выполнением синтаксического анализа, т. е. грамматическим разбором «предложения» из цепочки примитивов, описывающего объект. Эта процедура устанавливает, правильно оно или пет синтаксически относительно заданной грамматики образа, что позволяет отнести “предложение” к одному из классов.
Структурный подход к распознаванию позволяет описывать большую совокупность сложных объектов, используя небольшие наборы простых примитивов и пpaвил грамматики. Грамматическое правило — в нашем случае это правило подстановки — можно использовать произвольное число раз, и таким образом очень компактно выразить некоторые структурные особенности, вообще говоря, бесконечного множества предложений, составленных из цепочек примитивов. Очевидно, что практическая ценность такого подхода целиком зависит от способности распознавать примитивы и их взаимосвязи. Обычно взаимосвязь между примитивами определяется логическими или арифметическими операциями.