

Построение эконометрической модели производительности труда
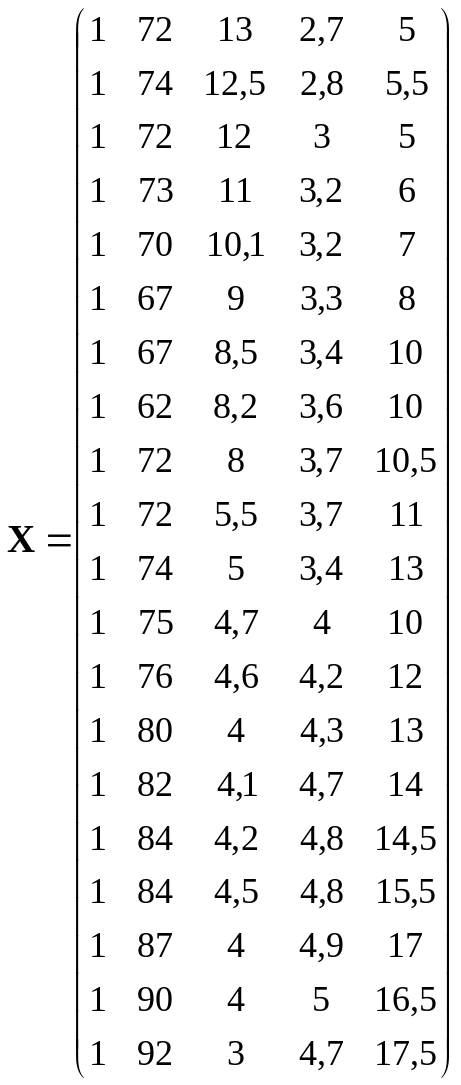
Введем обозначения: Y – зависимая переменная, результативный признак – производительность труда; Х1, Х2, Х3, Х4 – независимые переменные (объясняющие переменные, факторы), где Х1 – фондовооруженность труда, Х2 – коэффициент текучести рабочей силы, Х3 – потери рабочего времени, Х4 – стаж работы.
Модель производительности труда можно представить в следующем виде:
линейная функция Y = 0 + 1X1 + 2X2 + 3X3 + 4X4 + ;
степенная функция
 ,
,
где - стохастическая составляющая, учитывающая влияние случайных факторов на уровень производительности труда; j – параметры модели.
Соответственно расчетные по выборочной совокупности функции будут иметь вид:
= b0 + b1X1 + b2X2 + b3X3 + b4X4 ;
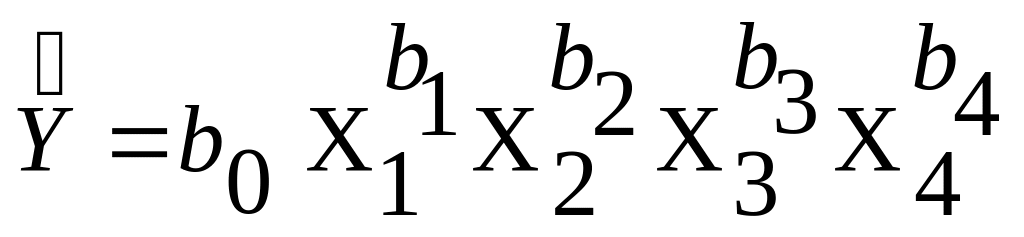 ,
,
здесь bj – оценки параметров модели (j = 1,2,3,4).
Основываясь на 20 наблюдениях, представленных в табл.1, построим линейную модель методом наименьших квадратов (МНК- модель).
Построение линейной эконометрической модели на основе матричного оператора 1МНК, пакет Excel.
Матричный
оператор 1МНК имеет вид
![]() ,
где
,
где
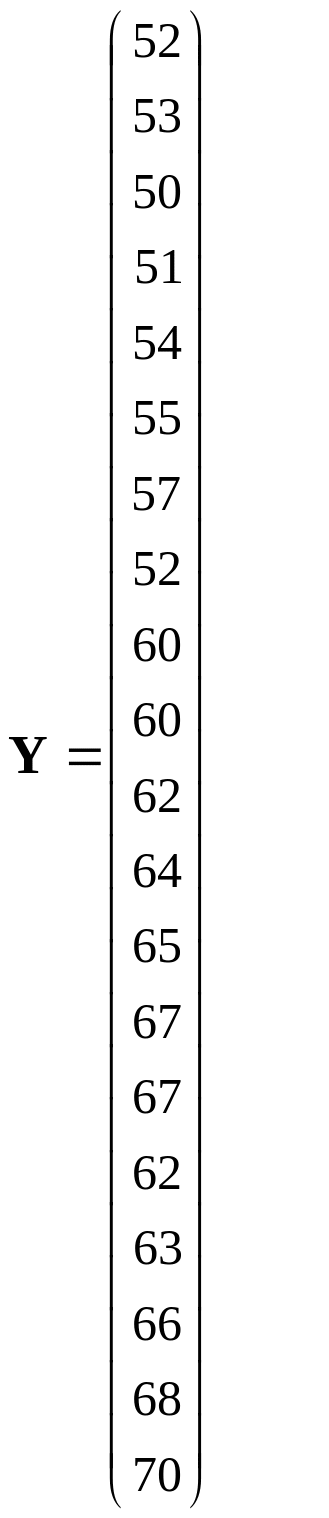
 ,
,
![]() - транспонированная матрица Х.
- транспонированная матрица Х.
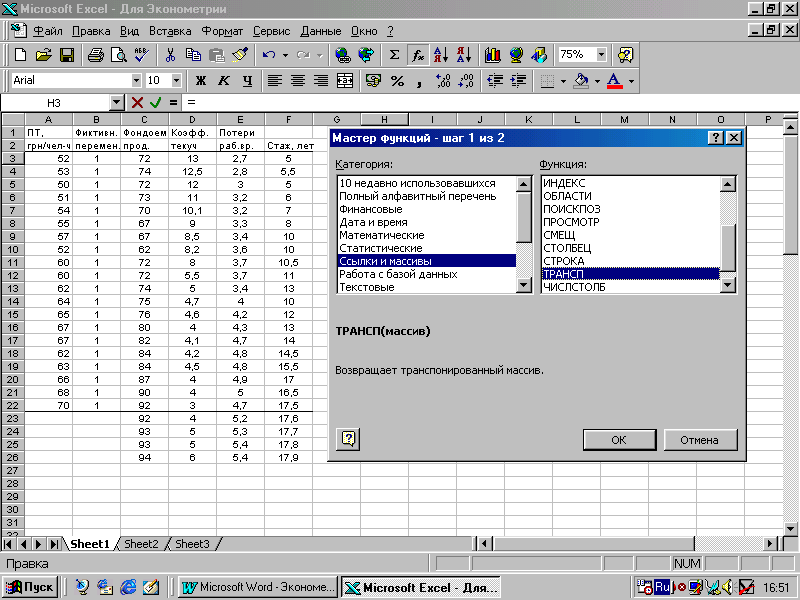
Для транспонирования матрицы Х выполните следующие действия:
выделите область пустых ячеек, состоящую из (р+1) = 5 строк и n = 20 столбцов для вывода результата, здесь р – количество независимых переменных, n – количество наблюдений;
активизируйте Мастер функций любым из способов:
в главном меню выберите Вставка/Функция;
на панели инструментов Стандартная щелкните по кнопке Вставка функции;
в раскрывшемся окне выберите Категорию Ссылки и массивы, Функцию – ТРАНСП (рис.1). Щелкните по кнопке ОК;
в
 строке Массив появившегося окна
укажите диапазон ячеек, в которых
содержится матрица Х. Щелкните по
кнопке ОК;
строке Массив появившегося окна
укажите диапазон ячеек, в которых
содержится матрица Х. Щелкните по
кнопке ОК;
Рис. 6.1
в левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем – на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Результат:
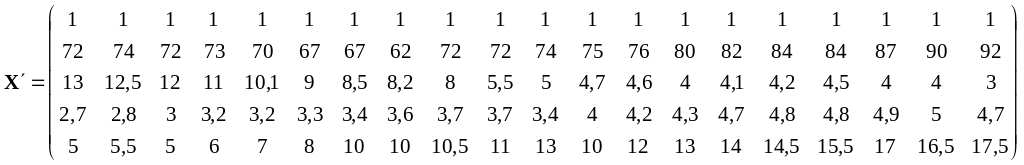 .
.
Произведение матриц (X'X) находим с помощью Мастера функций, используя Категорию Математические, функцию МУМНОЖ:
выделите область пустых ячеек, состоящую из (р+1) = 5 строк и (р+1) = 5 столбцов для вывода результата;
в окне МУМНОЖ в строке Массив 1 укажите диапазон ячеек, в которых содержится матрица X' (первый сомножитель), а в строке Массив 2 – матрица Х (второй сомножитель). Щелкните по кнопке ОК;
в левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем – на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Результат умножения матриц:
|
|
20 |
1525 |
139,9 |
77,4 |
221 |
|
||
|
|
1525 |
117509 |
10331 |
5995,4 |
17335 |
|
||
|
(X'X) = |
139,9 |
10331 |
1186,95 |
498,74 |
1307,7 |
|
||
|
|
77,4 |
5995,4 |
498,74 |
310,36 |
909,8 |
|
||
|
|
221 |
17335 |
1307,7 |
909,8 |
2756,5 |
|
||
Аналогично найдем с помощью функции МОБР обратную матрицу: |
|||||||||
|
|
15,5851 |
-0,0545 |
-0,5706 |
-1,6119 |
-0,104 |
|
||
|
|
-0,0545 |
0,00282 |
-0,0042 |
-0,0244 |
-0,0033 |
|
||
|
(X'X)-1 = |
-0,5706 |
-0,0042 |
0,04402 |
0,07434 |
0,02697 |
|
||
|
|
-1,6119 |
-0,0244 |
0,07434 |
0,98119 |
-0,0763 |
|
||
|
|
-0,104 |
-0,0033 |
0,02697 |
-0,0763 |
0,04194 |
|
||
|
|
|
|
|
|
|
|
||
|
|
1198 |
|
|
|
56,9124 |
|
||
|
|
92121 |
|
|
|
0,3375 |
|
||
|
(X'Y) = |
8003,2 |
|
B =(X'X)-1 |
(X'Y) = |
-1,8406 |
|
||
|
|
4716,5 |
|
|
|
-2,2722 |
|
||
|
|
13685 |
|
|
|
-0,0976 |
|
||




Таким образом, получили эконометрическую модель:
= 56,912 + 0,338Х1 – 1,841Х2 – 2,272Х3 – 0,098Х4.
Подставив в модель исходные значения Хij (i = 1,2,…,20; j = 1,2,3,4), получим расчетные значения . Разность между фактическими и расчетными значениями результирующего показателя представляет собой остатки (еi ), являющиеся оценками значений возмущения.
|
|
50,6616 |
|
|
1,33836 |
|
|
1,79122 |
|
|
51,9809 |
|
|
1,01908 |
|
|
1,03852 |
|
|
51,8206 |
|
|
-1,8206 |
|
|
3,31455 |
|
|
53,4467 |
|
|
-2,4467 |
|
|
5,98621 |
|
|
53,9931 |
|
|
0,00686 |
|
|
4,7E-05 |
|
|
54,6805 |
|
|
0,31949 |
|
|
0,10207 |
|
|
55,1784 |
|
|
1,82157 |
|
|
3,31813 |
|
|
53,5887 |
|
|
-1,5887 |
|
|
2,52395 |
|
|
57,0558 |
|
|
2,94423 |
|
|
8,66847 |
|
|
61,6085 |
|
e = |
-1,6085 |
|
е2 = |
2,58722 |
|
|
63,6903 |
|
|
-1,6903 |
|
|
2,85696 |
|
|
63,5094 |
|
|
0,49061 |
|
|
0,2407 |
|
|
63,3813 |
|
|
1,61865 |
|
|
2,62003 |
|
|
65,5109 |
|
|
1,4891 |
|
|
2,21743 |
|
|
64,9954 |
|
|
2,00462 |
|
|
4,01849 |
|
|
65,2103 |
|
|
-3,2103 |
|
|
10,3061 |
|
|
64,5605 |
|
|
-1,5605 |
|
|
2,4353 |
|
|
66,1197 |
|
|
-0,1197 |
|
|
0,01434 |
|
|
66,9538 |
|
|
1,04619 |
|
|
1,09451 |
|
|
70,0535 |
|
|
-0,0535 |
|
|
0,00286 |
|
|
|
|
|
|
|
Сумма |
55,1371 |


Найдем стандартную ошибку остатков (модели) по формуле:
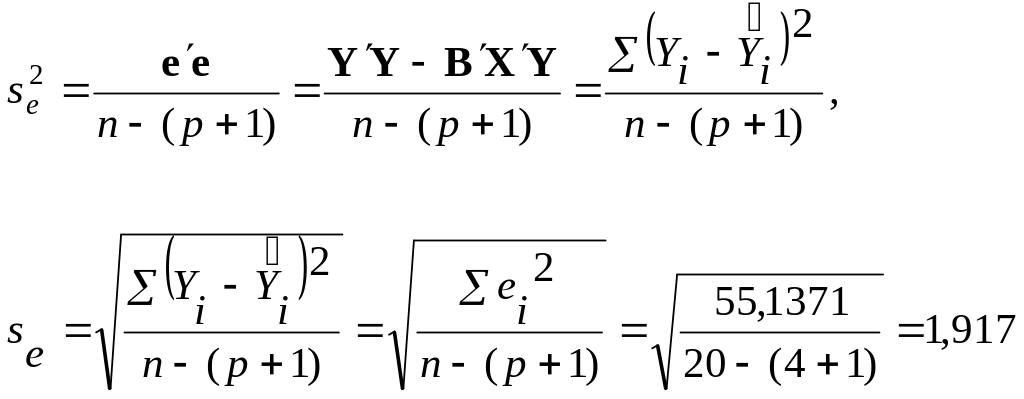
Определим стандартные ошибки оценок параметров модели:
![]() где
где
![]() – диагональные элементы матрицы
(Х’X)-1.
– диагональные элементы матрицы
(Х’X)-1.
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Для проверки статистической надежности (значимости) оценок параметров модели найдем величину t-статистики, используя формулу:
![]() .
.
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Построение эконометрической модели с использованием стандартной программы
«ЛИНЕЙН»:
Встроенная статистическая функция ЛИНЕЙН определяет коэффициенты линейной регрессии:
= b0 + b1X1 + b2X2 + b3X3 + … + bрXр.
Порядок вычислений следующий:
введите исходные данные;
выделите область пустых ячеек, состоящую из 5 строк и (р + 1) столбцов (где р – количество независимых переменных) для вывода результатов регрессионной статистики;
активизируйте Мастер функций любым из способов:
в главном меню выберите Вставка/Функция;
на панели инструментов Стандартная щелкните по кнопке Вставка функции fx
в раскрывшемся окне выберите Категорию Статистические, Функцию – ЛИНЕЙН. Щелкните по кнопке ОК;
заполните аргументы функции (рис. 2):
Известные значения У – диапазон, содержащий данные, характеризующие результативный признак;
Известные значения Х – диапазон, содержащий данные, описывающие все независимые переменные;
Константа – логическое значение, указывающее на наличие или отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член = 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения. Щелкните по кнопке ОК;
в левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем – на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Рис. 6.2. Мастер функций. Работа с функцией ЛИНЕЙН
Дополнительная регрессионная статистика будет выводиться в следующем виде (табл. 6.2):
Таблица 6.2
Значение bр |
Значение bр-1 |
. . . |
Значение b2 |
Значение b1 |
Значение b0 |
Стандартная ошибка оценки bр
( |
Стандартная ошибка оценки bр-1
( |
. . . |
Стандартная ошибка оценки b2
( |
Стандартная ошибка оцен-ки b1
( |
Стандартная ошибка оцен-ки b0
( |
Коэффициент детерминации R2 |
Стандартная ошибка модели (остатков)
|
#Н/Д |
#Н/Д |
#Н/Д |
#Н/Д |
F-статистика |
Число степеней свободы n-(p+1) |
#Н/Д |
#Н/Д |
#Н/Д |
#Н/Д |
Регрессионная сумма квадратов |
Остаточная сумма квадратов |
#Н/Д |
#Н/Д |
#Н/Д |
#Н/Д |
Функция ЛИНЕЙН используется и для
расчета оценок параметров моделей,
которые с помощью преобразования могут
быть сведены к линейному виду. Например,
степенная функция
![]() путем логарифмирования превращается
в линейную по параметрам функцию:
путем логарифмирования превращается
в линейную по параметрам функцию:
ln = lnb0 + b1 lnX1 + b2 ln X2 + b3 lnX3 + b4 lnX4,
или Z = A + b1z1 + b2z2 + b3z3 + b4z4,
где Z = ln , zj = lnXj ( j = 1,2,3,4); А = lnb0, т.е. b0 = exp(A) = eA, где е – основание натурального логарифма.
Из способа преобразования видно, что для вычисления коэффициентов степенной функции с помощью ЛИНЕЙН следует в строки Известные значения У и Известные значения Х окна рассматриваемой функции вводить логарифмы исходных значений У и Х.
Для рассматриваемого примера (модель производительности труда) результат применения функции ЛИНЕЙН выглядит следующим образом:
Линейная модель
-
-0,09758
-2,27216
-1,8406
0,33749665
56,91243
0,392655
1,899119
0,402268
0,10189618
7,568861
0,929654
1,917239
#Н/Д
#Н/Д
#Н/Д
49,55804
15
#Н/Д
#Н/Д
#Н/Д
728,6629
55,13708
#Н/Д
#Н/Д
#Н/Д
Степенная модель
0,054165
-0,12441
-0,19206
0,197562
3,625281
0,06836
0,126229
0,057959
0,12589694
0,627738
0,9251
0,033461
#Н/Д
#Н/Д
#Н/Д
46,31687
15
#Н/Д
#Н/Д
#Н/Д
0,207431
0,016794
#Н/Д
#Н/Д
#Н/Д
b0 = exp(3,625281) = e3,625281 = 37,5353.
Таким образом, получили следующие уравнения:
= 56,912 + 0,338Х1 – 1,841Х2 – 2,271Х3 – 0,098Х4;
= 37,5353 X10,198 X2-0,192 X3-0,124 X40,0541.
Однако следует иметь в виду, что статистические характеристики степенной модели определены через логарифмы, и поэтому прямо использовать их для сравнения с соответствующими характеристиками линейной модели (например, с целью выбора лучшей модели) нельзя. Необходимо привести их в сопоставимый вид. Это касается всех функций, при преобразовании которых к линейному виду изменялась (преобразовывалась) зависимая переменная Y.
С учетом пересчета, который выполняется с применением соответствующих формул (3), (5), для степенной функции получили:
R2= 0,9242; Se = 1,9906.
Построение эконометрической модели с помощью инструмента Анализа
Данных / Регрессия
Порядок действий:
проверьте доступ к Пакету анализа. При его отсутствии в главном меню выберите Сервис/Надстройки. Установите флажок Пакет анализа. Щелкните по кнопке ОК;
в главном меню выберите Сервис/Анализ данных /Регрессия. Щелкните по кнопке ОК;
заполните диалоговое окно ввода данных (фактических значений всех показателей, если рассчитываются оценки параметров линейной модели, и логарифмы фактических значений, если речь идет о степенной функции) и параметров вывода (рис.3):
Входной интервал У – диапазон, содержащий данные результативного признака ;
Входной интервал Х – диапазон, содержащий данные независимых переменных;
Метки – флажок, который указывает, содержит ли первая строка название столбцов или нет;
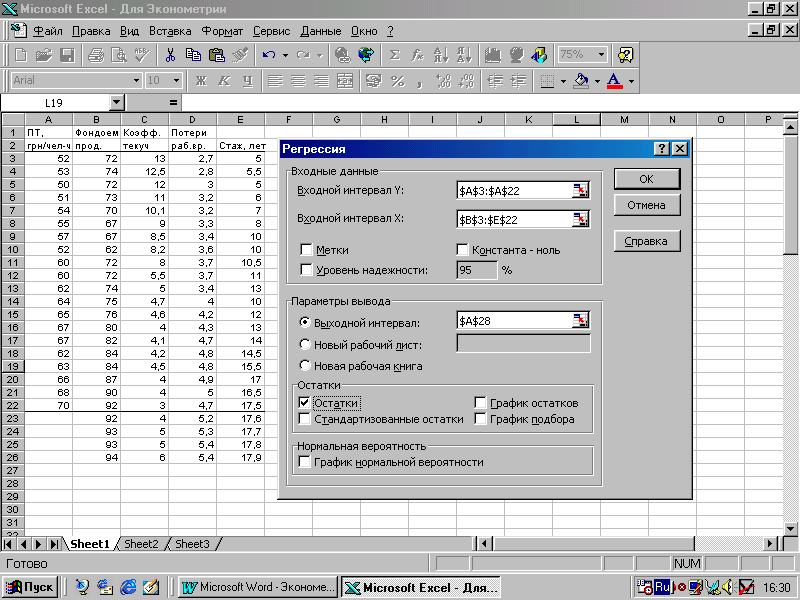
Рис.6.3
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
Новый рабочий лист – можно задать произвольное имя нового листа.
Если необходимо получить информацию и графики остатков, установите соответствующие флажки в диалоговом окне. Щелкните по кнопке ОК.
Результаты регрессионного анализа для линейной модели ПТ (табл.63):
Таблица 3.
ВЫВОД ИТОГОВ |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
Регрессионная статистика |
|
|
|
|
|
|
||
Множественный R |
0,96418574 |
|
|
|
|
|
||
R-квадрат |
0,92965414 |
|
|
|
|
|
||
Нормированный R-квадрат |
0,91089525 |
|
|
|
|
|
||
Стандартная ошибка |
1,91723904 |
|
|
|
|
|
||
Наблюдения |
20 |
|
|
|
|
|
||
|
|
|
|
|
|
|
||
Дисперсионный анализ |
|
|
|
|
|
|
||
Источники вариации |
df |
SS |
MS |
F |
Значимость F |
|||
Регрессия |
4 |
728,6629171 |
182,1657 |
49,558 |
1,8E-08 |
|
||
Остаток |
15 |
55,1370829 |
3,675806 |
|
|
|
||
Итого |
19 |
783,8 |
|
|
|
|
||
Оценки параметров модели и их значимость |
||||||||
|
Коэффициенты |
Станд.ошиб- ка |
t-стат. |
P-Значение. |
Нижн.95% |
Верх.95% |
||
Y-пересечение |
56,9124321 |
7,568860683 |
7,519287 |
1,8E-06 |
40,77978 |
73,04509 |
||
Переменная X 1 |
0,33749665 |
0,101896176 |
3,312162 |
0,00474 |
0,12031 |
0,554683 |
||
Переменная X 2 |
-1,8406011 |
0,402267501 |
-4,57557 |
0,00036 |
-2,69801 |
-0,98319 |
||
Переменная X 3 |
-2,2721556 |
1,899118933 |
-1,19643 |
0,2501 |
-6,32003 |
1,775723 |
||
Переменная X 4 |
-0,0975842 |
0,392655308 |
-0,24852 |
0,8071 |
-0,93451 |
0,739341 |
||
ВЫВОД ОСТАТКА |
|
|
|
|||||
|
|
|
|
|||||
Наблюдение |
Предсказан-ное Y |
Остатки |
|
|||||
1 |
50,6616359 |
1,338364147 |
|
|||||
2 |
51,9809221 |
1,019077932 |
|
|||||
3 |
51,8205903 |
-1,820590278 |
|
|||||
4 |
53,4466727 |
-2,446672748 |
|
|||||
5 |
53,9931396 |
0,006860385 |
|
|||||
6 |
54,6805111 |
0,319488857 |
|
|||||
7 |
55,1784278 |
1,821572197 |
|
|||||
8 |
53,5886938 |
-1,58869375 |
|
|||||
9 |
57,0557729 |
2,944227141 |
|
|||||
10 |
61,6084835 |
-1,608483531 |
|
|||||
11 |
63,6902557 |
-1,690255734 |
|
|||||
12 |
63,5093919 |
0,490608139 |
|
|||||
13 |
63,3813492 |
1,618650827 |
|
|||||
14 |
65,5108967 |
1,489103278 |
|
|||||
15 |
64,9953835 |
2,004616485 |
|
|||||
16 |
65,2103091 |
-3,210309068 |
|
|||||
17 |
64,5605446 |
-1,560544572 |
|
|||||
18 |
66,1197433 |
-0,119743273 |
|
|||||
19 |
66,9538098 |
1,046190244 |
|
|||||
20 |
70,0534667 |
-0,053466676 |
|
|||||
Результаты расчетов по этой программе дают наибольшее количество характеристик взаимосвязи. Рассмотрим эти характеристики подробнее.
Регрессионная статистика
R = 0,9642 – коэффициент корреляции;
R2 = 0,9296 – не скорректированный коэффициент детерминации (без учета числа степеней свободы) оценивает долю вариации результата за счет введенных в модель факторов в общей вариации Y. Здесь эта доля составляет 92,96% и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов, иными словами – на очень тесную связь факторов и результата.
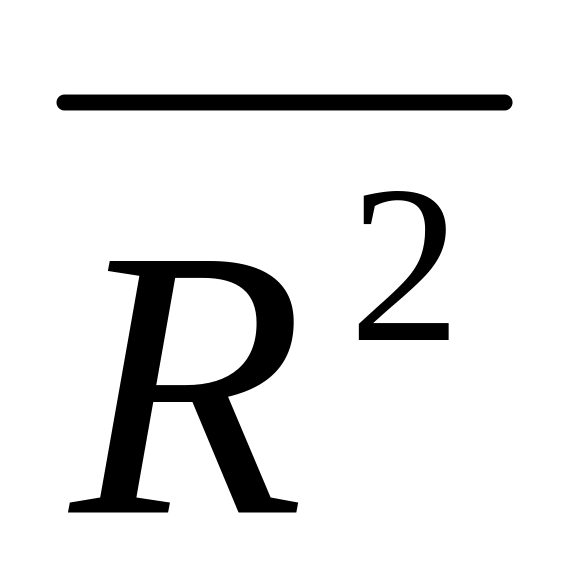 =
0,9109 – скорректированный коэффициент
детерминации определяет тесноту связи
с учетом числа степеней свободы общей
и остаточной дисперсии. Он дает оценку,
не зависящую от количества независимых
переменных (факторов) модели, и поэтому
может сравниваться по разным моделям
с разным количеством факторов. Связь
между не скорректированным и
скорректированным коэффициентами
детерминации определяется по формуле:
=
0,9109 – скорректированный коэффициент
детерминации определяет тесноту связи
с учетом числа степеней свободы общей
и остаточной дисперсии. Он дает оценку,
не зависящую от количества независимых
переменных (факторов) модели, и поэтому
может сравниваться по разным моделям
с разным количеством факторов. Связь
между не скорректированным и
скорректированным коэффициентами
детерминации определяется по формуле:
![]() .
.
Оба коэффициента (R2, ) указывают на весьма высокую (более 91%) детерминированность результата Y в модели факторами Х1, Х2, Х3, Х4.
se = 1,9172 – стандартная ошибка остатков;
n = 20 – количество наблюдений.
Дисперсионный анализ включает пять столбцов:
(df ) – степени свободы, т.е. число свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней оценок. Для условий рассматриваемого примера число степеней свободы:
для регрессии р = 4; для остатка n – (р + 1) = 20 – (4 + 1) = 15; общее n – 1 = 20 – 1 = 19;
(SS) – суммы квадратов отклонений:
![]() - регрессии (объясненная);
- регрессии (объясненная);
![]() -
остаточная (не объясненная);
-
остаточная (не объясненная);
![]() - общая (зависимой переменной);
- общая (зависимой переменной);
(MS) – дисперсия на одну степень свободы:
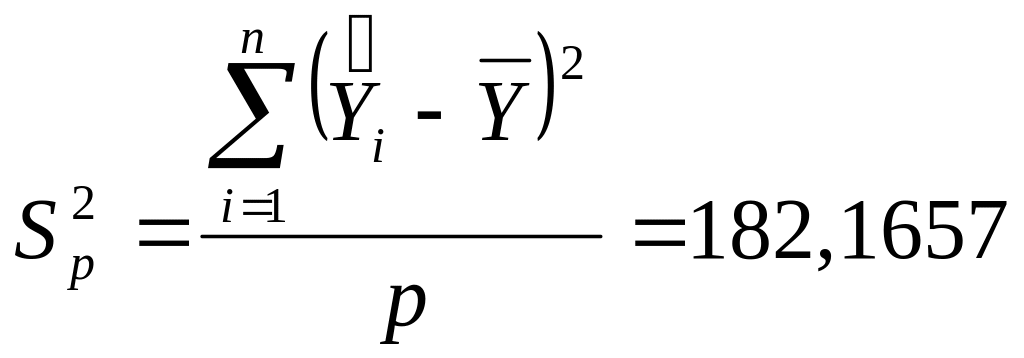 - регрессий (объясненная);
- регрессий (объясненная);![]()
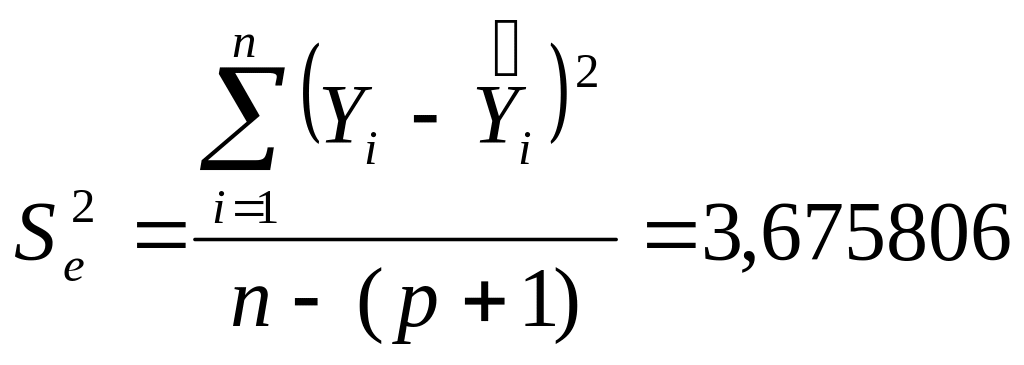 - остатков (не объясненная);
- остатков (не объясненная);
(F) – фактическое значение F-критерия:
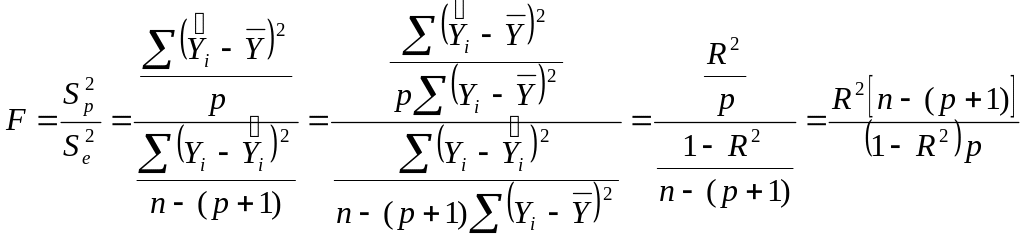 =
49,558;
=
49,558;
(Значимость F) – уровень значимости F-критерия = 1,8E-08 = 0,00000018.
Коэффициент детерминации R2 равен 0,9296, что указывает на сильную зависимость между независимыми переменными и производительностью труда. Можно использовать F-статистику, чтобы определить, является ли этот результат (с таким высоким значение R2) случайным. Величина применяется для обозначения вероятности ошибочного вывода о том, что имеется сильная взаимозависимость.
Предположим, что на самом деле нет взаимосвязи между переменными, а просто были выбраны редкие 20 наблюдений, для которых статистический анализ вывел сильную взаимозависимость.
Оценку надежности уравнения регрессии в целом и коэффициента детерминации дает F-критерий Фишера. Его расчетное (фактическое) значение F = 49,558 сравнивается с табличным, которое при уровне значимости = 5% и при числе степеней свободы v1 = р = 4, v2 = n-(р+1) = 15 составляет 3,06. Если фактическое значение превышает табличное, то с вероятностью 0,95 гипотеза о ненадежности уравнения отвергается и утверждается статистическая значимость модели и коэффициента детерминации. Или, что то же самое, из таблицы дисперсионного анализа следует, что вероятность случайно получить такое значение F-критерия (F = 49,558) составляет Р = 0,00000018, что не превышает допустимый уровень значимости 5% (величину = 0,05). Следовательно, полученное значение не случайно, оно сформировалось под влиянием существенных факторов, то есть, подтверждается статистическая значимость всей модели и коэффициента детерминации.
Оценки параметров модели и их значимость
Этот блок результатов содержит 9 столбцов.
Первый и второй – название и величина оценок параметров модели:
Y – пересечение – b0 = 56,9124321; переменная Х1 – b1 = 0,33749665;
переменная Х2 – b2 = -1,8406011; переменная Х3 – b3 = -2,2721556;
переменная Х4 – b4 = -0,0975842.
Таким образом, получена модель:
= 56,912 + 0,338Х1 – 1,841Х2 – 2,272Х3 – 0,098Х4.
Величины bj (j = 1,2,3,4) показывают, насколько изменится результат с увеличением значения некоторого фактора на единицу и при неизменной величине остальных факторов. Так, увеличение Х1 (фондовооруженность труда) на 1 тыс.грн/чел. при прочих равных условиях будет способствовать росту производительности труда на 0,338 (тыс.грн./чел.-ч)/(тыс.грн/чел). Если же Х2 (коэффициент текучести кадров) увеличится на 1%, а другие факторы не изменятся, то величина производительности труда уменьшится на 1,841(тыс.грн./чел.-ч)/%. Рост Х3 (потери рабочего времени) на единицу (1%) также отрицательно воздействует на производительность труда: уменьшает ее на 2,271(тыс.грн./чел.-ч)/% при прочих равных условиях.
Направленность воздействия первых трех из рассмотренных факторов на производительность труда не противоречит экономическому смыслу, тогда как влияние четвертого фактора – стаж работы – вызывает сомнение: казалось бы, чем дольше человек работает, тем лучше у него навыки и тем выше производительность; а b4 = -0,0975842 показывает, что увеличение стажа на 1 год, хотя и незначительно, снижает уровень производительности труда.
Сравнивать силу влияния отдельных факторов на величину результирующего показателя, сопоставляя коэффициенты, не следует, так как эти коэффициенты зависят от единиц измерения каждого показателя. С целью выявления наиболее влияющих показателей необходимо перейти к уравнению в стандартизованном масштабе, в котором в качестве единицы измерения влияния всех факторов выступает среднее квадратичное отклонение.
Третий столбец содержит стандартные ошибки оценок параметров модели:
![]() =
7,568886;
=
7,568886;
![]() = 0,101896;
= 0,101896;
![]() =
0,402267;
=
0,402267;
![]() = 1,899119;
= 1,899119;
![]() =0,392655.
=0,392655.
Они показывают, какая доля значения данной характеристики сформировалась под влиянием случайных факторов. Эти величины (см.(7)) используются для расчета t-критерия Стьюдента, значения которого для различных оценок представлены в четвертом столбце.
Четвертый столбец – t-критерий:
t0 = 7,519287; t1 = 3,312162; t2 = -4,57557; t3 = -1,19643; t4 = -0,24852.
Если значения t-критерия больше 2–3, то можно сделать вывод о существенности данного параметра, который формируется под воздействием неслучайных величин. Для более обоснованных выводов используем результаты, находящиеся в пятом столбце.
Пятый столбец – уровень значимости – показатель вероятности случайных значений параметров регрессии:
0 = 0,0000018; 1 = 0,00474; 2 = 0,00036; 3 = 0,2501; 4 = 0,8071.
Если j меньше принятого нами уровня (обычно 0,1; 0,05 или 0,01; это соответствует 10%, 5% или 1% вероятности), то делают вывод о неслучайной природе данного значения оценки, т.е. о том, что оценки параметров достоверны (статистически значимы). В противном случае принимается гипотеза о случайной природе значения коэффициента регрессии.
Поскольку 3 = 0,2501 и 4 = 0,8071 больше 0,005, то делаем вывод, что соответствующие оценки b3 и b4 – недостоверны. Это позволяет рассматривать факторы Х3 и Х4 как неинформативные и ставить под сомнение необходимость включения их в модель.
Возникшее противоречие (F-критерий утверждает достоверность модели в целом, а t-критерий – недостоверность отдельных оценок) обычно определяется существующей между независимыми переменными мультиколлинеарностью.
Оставшиеся четыре столбца с вероятностью 0,95 определяют верхние и нижние границы оценок параметров модели, т.е. позволяют осуществить интервальное оценивание параметров. (Поскольку находящиеся в этих столбцах величины повторяют друг друга, то здесь приведены только 6 и 7 столбцы).
Интервальное оценивание параметра модели j выполняется следующим образом:
bj
![]()
t ,
или bj -
t
j
bj +
t .
t ,
или bj -
t
j
bj +
t .
Так, например, для 0 :
для = 5% и 20 – 5 = 15 степеней свободы табличное значение (двустороннее) t = 2,13,
тогда t = 7,568886 2,131 = 16,1293;
56,9124321 – 16,1293 0 56,9124321+ 16,1293; 40,78 0 73,04;
0,12031 1 0,554683; -2,69801 2 -0,98319;
-6,32003 3 1,775723; -0,93451 4 0,739341.
Таким образом, с вероятностью 0,95, увеличение фондовооруженности труда на одну единицу обеспечит прирост производительности труда не ниже 0,12031 и не выше 0,554683 тыс.грн./чел.-ч. Аналогично интерпретируются остальные доверительные интервалы.
Доверительные интервалы для третьего и четвертого параметров включают нулевое значение, что еще раз подтверждает сделанный ранее вывод о недостоверности их оценок.
Вывод остатков
В этом блоке результатов приводятся расчетные значения зависимой переменной и остатки, которые определяются как разность между фактическими значениями зависимой переменной и расчетными.
Программа Анализ данных/Регрессия позволяет вывести и графики «подбора», т.е. зависимости результативного признака от каждого из факторов, а также графики остатков для парных зависимостей. Для вывода графиков следует в окне Регрессия поставить соответствующие флажки.