

Проверка выполнения основных предпосылок
классической регрессии
Прежде, чем использовать построенную эконометрическую модель, важно определить, выполнялись ли предпосылки МНК, поскольку от этого зависит, обладают ли оценки параметров модели нужными свойствами. Особенно важно провести проверку на:
гомоскедастичность – является ли дисперсия остатков постоянной;
отсутствие автокорреляции остатков – остатки независимы;
отсутствие мультиколлинеарности – некоррелированность объясняющих переменных.
Гетероскедастичность приводит к тому, что оценки параметров модели больше не представляют собой лучшие оценки, или не являются оценками с минимальной дисперсией, т.е. они не обладают свойством эффективности.
Воздействие гетероскедастичности на оценку интервала прогнозирования и проверку гипотезы заключается в том, что хотя коэффициенты не смещены, дисперсии, и, следовательно, стандартные ошибки этих коэффициентов будут смещены. Чаще всего смещение является отрицательным (т.е. в сторону уменьшения), значит, стандартные ошибки будут меньше, чем они должны быть, а t-критерий – больше, чем в реальности. Вследствие этого мы можем отвергнуть нулевую гипотезу, в то время как она должна быть принята, т.е. ошибочно будем считать коэффициент регрессии значимым, тогда как это не так.
Для проверки на гетероскедастичность используется тест Голдфельда-Квандта. При проведении проверки по этому критерию предполагается, что стандартное отклонение (i) распределения вероятностей i пропорционально значению Х в этом наблюдении. Предполагается также, что возмущение распределено нормально и не подвержено автокорреляции. В соответствии с тестом Голдфельда-Квандта выполняем следующие действия:
все n наблюдений упорядочим по возрастанию Х;
отбросим с средних наблюдений; величину с предлагается определять так:
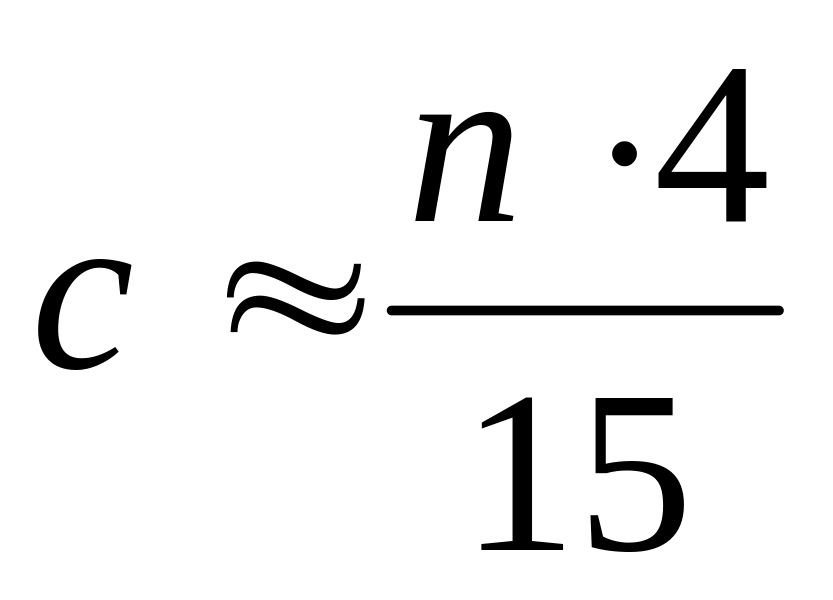 ,
,
причем удобно принимать такое значение с, которое позволяет иметь два подмассива одинаковой длины m (после отбрасывания средних наблюдений);
оцениваем отдельные регрессии для первых m и для последних m наблюдений и находим суммы квадратов остатков в двух указанных регрессиях, которые обозначим S1 и S2, соответственно;
рассчитаем отношение F = S2 /S1, которое имеет F- распределение с 1 = 2 = m – (р + 1) степенями свободы, где р – число объясняющих переменных в регрессионном уравнении. Сравнив расчетное F с табличным, делаем вывод: о наличии гетероскедастичности, если F расчетное больше F табличного; о гомоскедастичности остатков – в противном случае.
Если в модели имеется более одной объясняющей переменной, то наблюдения следует упорядочивать по той из них, которая, как предполагается, связана с i.
Метод Голдфельда-Квандта можно применять и при предположении, что i обратно пропорционально значению Х. При этом используется та же процедура, но тестовой статистикой теперь является отношение F = S1 /S2.
Пример 2. В таблице 2 (столбцы 2, 3) приведены данные о величине сбережений (Y) и доходов (Х) соответственно для выборки из18 семей. Поскольку величина дохода сильно различается, следует выполнить проверку гетероскедастичности.
Данные табл. 2 уже упорядочены по возрастанию Х. В соответствии с тестом Голдфельда-Квандта из середины массива данных удаляем 18*4/15=4,84 точки и получаем 2 массива.
Таблица 2
№ наблюдения |
Сбережения(Y) |
Доход (Х) |
Y расчетн. |
Остатки (е) |
Квадрат остатков (е2) |
1 |
2 |
3 |
4 |
5 |
6 |
1 |
2,3 |
15 |
2,16 |
2,3 –2,16=0,14 |
0,020 |
2 |
2,2 |
15 |
2,16 |
2,2 – 2,16=0,04 |
0,002 |
3 |
2,08 |
16 |
2,20 |
2,08 – 2,2=-0,12 |
0,015 |
4 |
2,2 |
17 |
2,25 |
2,2 –2,25=-0,05 |
0,002 |
5 |
2,1 |
17 |
2,25 |
2,1 –2,25=-0,15 |
0,022 |
6 |
2,32 |
18 |
2,29 |
2,32 –2,29=0,03 |
0,001 |
7 |
2,45 |
19 |
2,34 |
2,45 –2,34=0,11 |
0,012 |
8 |
2,5 |
20 |
|
|
S1=0,07453 |
9 |
2,2 |
20 |
|
|
|
10 |
2,5 |
22 |
|
|
|
11 |
3,1 |
64 |
|
|
|
12 |
2,5 |
68 |
2,53 |
2,5 –2,53=-0,03 |
0,001 |
13 |
2,82 |
72 |
2,68 |
2,82 –2,68=0,14 |
0,019 |
14 |
3,04 |
80 |
2,99 |
3,04 –2,99=0,05 |
0,002 |
15 |
2,7 |
85 |
3,18 |
2,7 –3,18=-0,48 |
0,234 |
16 |
3,94 |
90 |
3,38 |
3,94 –3,38=0,56 |
0,318 |
17 |
3,1 |
95 |
3,57 |
3,1 –3,57=-0,47 |
0,220 |
18 |
3,99 |
100 |
3,76 |
3,99 –3,76=0,23 |
0,052 |
|
|
|
|
|
S2=0,84581 |
F= |
S2/S1=11,3483 |
> Fтабл.= 11 |
|
|
|
Таблица 3 |
|
|
|
|
|
№ набл. |
Сбережен. |
Доход |
|
|
|
|
Y |
X |
YX |
X^2 |
|
1 |
2,3 |
15 |
34,5 |
225 |
|
2 |
2,2 |
15 |
33 |
225 |
|
3 |
2,08 |
16 |
33,28 |
256 |
|
4 |
2,2 |
17 |
37,4 |
289 |
|
5 |
2,1 |
17 |
35,7 |
289 |
|
6 |
2,32 |
18 |
41,76 |
324 |
|
7 |
2,45 |
19 |
46,55 |
361 |
|
Сумма |
15,65 |
117 |
262,19 |
1969 |
|
|
|
|
|
|
|
7 b0 + 117 b1 = 15,65 |
|
b0= |
1,475 |
|
|
117 b0 +1969 b1 = 262 |
|
b1= |
0,045 |
|
|
|
|
|
|
|
|
Модель 1: Y^=1,475 + 0,045X |
|
|
|
||
Таблица 4 |
|
|
|
|
|
|
Y |
X |
YX |
X^2 |
|
12 |
2,5 |
68 |
170 |
4624 |
|
13 |
2,82 |
72 |
203,04 |
5184 |
|
14 |
3,04 |
80 |
243,2 |
6400 |
|
15 |
2,7 |
85 |
229,5 |
7225 |
|
16 |
3,94 |
90 |
354,6 |
8100 |
|
17 |
3,1 |
95 |
294,5 |
9025 |
|
18 |
3,99 |
100 |
399 |
10000 |
|
Сумма |
22,09 |
590 |
1893,84 |
50558 |
|
|
|
|
|
|
|
7 b0 +590 b1 = 22,09 |
|
b0= |
-0,093 |
|
|
590 b0 + 50558 b1 = 1894 |
|
b1= |
0,038 |
|
|
|
|
|
|
|
|
Модель 2: Y^ = -0,093 + 0,038X |
|
|
|
||
В таблицах 3 и 4 показан расчет оценок параметров моделей, которые строятся на основе полученных двух массивов, а в столбце 4 таблицы 2 представлены вычисленные по этим моделям значения исследуемого показателя Y (расчетные, или теоретические). Рассчитанное значение F-критерия больше табличного, выбранного при уровне значимости = 5%, значит, гипотеза об отсутствии гетероскедастичности отвергается.
Поскольку остатки гетероскедастичны, метод наименьших квадратов для оценивания параметров модели применять нельзя.
Автокорреляция, также известная как сериальная корреляция, имеет место, когда остатки не являются независимыми друг от друга, потому что текущие значения Y находятся под влиянием прошлых значений. Зависимость между остатками описывается с помощью авторегрессионной схемы. Например, допустим, что остаток et находится под влиянием остатка из предыдущего периода времени et-1 и какого-либо текущего значения случайной переменной ut. Остаток et будет описываться следующей авторегрессионной функцией первого порядка:
![]() .
.
Для проверки на автокорреляцию применяется критерий Дарбина-Уотсона, в соответствии с которым рассчитывается d-статистика (или DW):
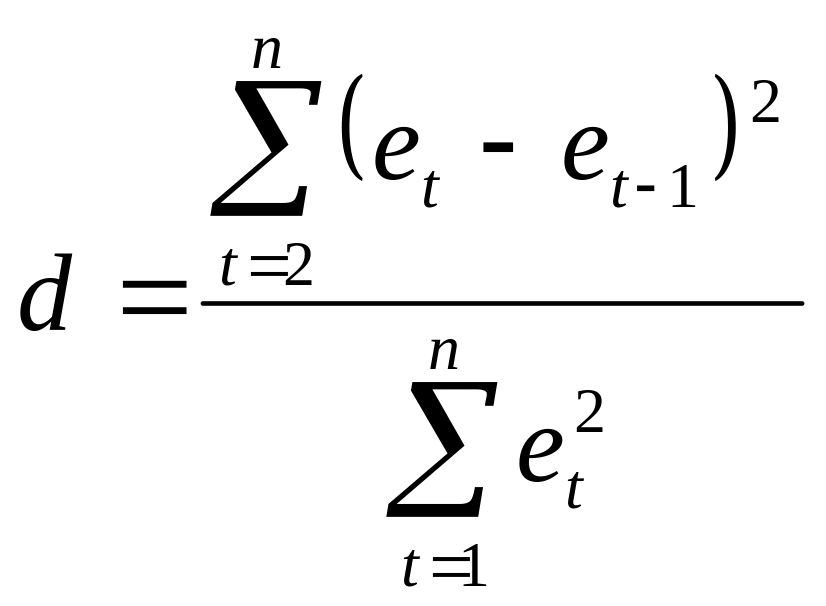 .
.
Эмпирическое правило гласит, что если критерий Дарбина-Уотсона равен двум, то не существует автокорреляции, если он равен нулю, то имеет место совершенная положительная автокорреляция а если он равен четырем, то имеет место совершенная отрицательная автокорреляция. Авторы разработали таблицу, содержащую критические значения: нижнее dL и верхнее du (или dН и dВ ). Вычисленное значение d-статистики сравнивается с табличными, выбранными при заданном уровне значимости, в зависимости от количества наблюдений и числа независимых переменных в модели. Для d 2 руководствуемся следующим правилом:
если d dL, то имеется положительная автокорреляция;
если d du, то автокорреляции нет;
если dL d du, то ничего определенного сказать нельзя.
Если расчетное значение d больше двух, то описанной проверке подвергается величина (4 – d) и делаются те же выводы с той разницей, что автокорреляция будет отрицательной.
Автокорреляция может появиться из-за того, что не все важные факторы введены в модель, из-за неверно выбранной формы связи (уравнения регрессии). Введение переменных с лагом тоже может привести к автокорреляции остатков. Применение МНК для оценивания параметров модели при наличии автокорреляции имеет те же негативные последствия, как и в случае с гетероскедастичностью.
Пример 3. Проверим наличие автокорреляции остатков, используя условия примера 2. В табл. 5 выполнен расчет d-статистики Дарбина-Уотсона. Причем расчетные значения зависимой переменной, приведенные в 3-ем столбце таблицы, получены с использованием функции Excel ТЕНДЕНЦИЯ (о применении этой функции и других подробно рассказывается в следующем разделе).
Таблица 5
-
Y
Х
Y расчетн.
Остатки (е)
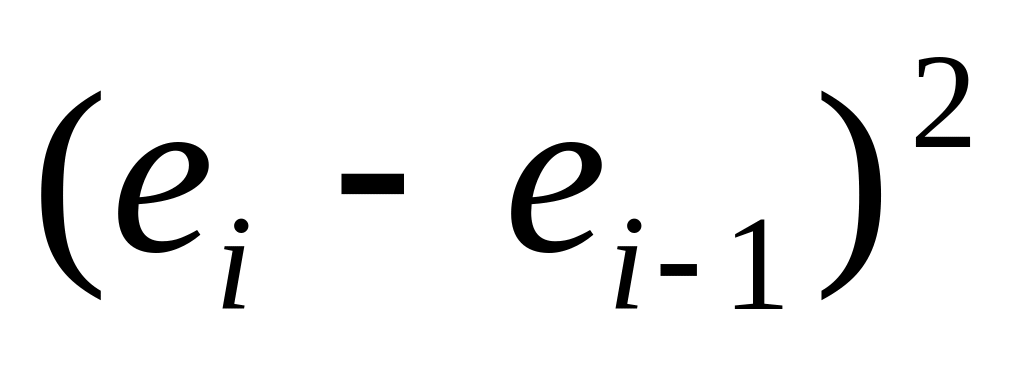

1
2
3
4
5
6
2,3
15
2,21607
0,08393
0,00704
2,2
15
2,21607
-0,01607
0,01
0,00026
2,08
16
2,23055
-0,15055
0,01808
0,02267
2,2
17
2,24503
-0,04503
0,01114
0,00203
2,1
17
2,24503
-0,14503
0,01
0,02103
2,32
18
2,2595
0,0605
0,04224
0,00366
2,45
19
2,27398
0,17602
0,01335
0,03098
2,5
20
2,28846
0,21154
0,00126
0,04475
2,2
20
2,28846
-0,08846
0,09
0,00782
2,5
22
2,31741
0,18259
0,07347
0,03334
3,1
64
2,92546
0,17454
6,5E-05
0,03046
2,5
68
2,98337
-0,48337
0,43284
0,23364
2,82
72
3,04128
-0,22128
0,06869
0,04896
3,04
80
3,15709
-0,11709
0,01085
0,01371
2,7
85
3,22948
-0,52948
0,17006
0,28035
3,94
90
3,30187
0,63813
1,36332
0,40721
3,1
95
3,37425
-0,27425
0,83245
0,07522
3,99
100
3,44664
0,54336
0,66849
0,29524
Сумма
3,81631
1,55134
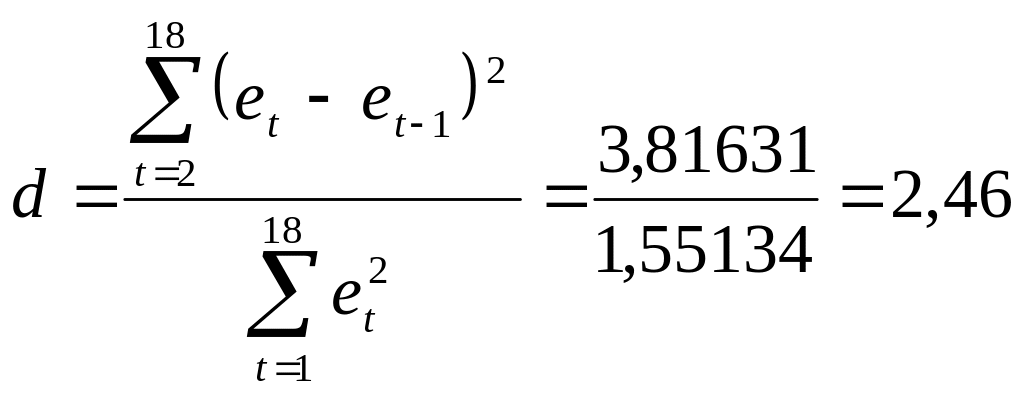 .
4 – d = 4 – 2,46 = 1,54.
.
4 – d = 4 – 2,46 = 1,54.
Из таблицы Дарбина-Уотсона при уровне значимости 0,05, задавшись количеством наблюдений n = 18 и числом независимых переменных к = 1, выбираем граничные значения:
dL = 1,16, du = 1,39. Поскольку 4 – d = 1,54 > du = 1,39, то с вероятностью 0,95 можно утверждать, что автокорреляции остатков, полученных по модели, оцененной методом наименьших квадратов, не существует.
Мультиколлинеарность означает тесную линейную взаимосвязь между независимыми переменными модели. Если некоторые или все независимые переменные во множественной регрессии связаны сильной корреляционной зависимостью (мультиколлинеарны), то регрессионная модель не в состоянии разграничить их отдельные объясняющие воздействия на Y.
При мультиколлинеарности часто возникает противоречие между величиной и значимостью коэффициента детерминации и статистической надежностью коэффициентов регрессии. Так, значение коэффициента детерминации может быть высоким, и величина F-критерия подтверждает значимость коэффициента детерминации, следовательно, и уравнения регрессии в целом; в то же время стандартные ошибки оценок параметров модели высоки, и поэтому соответствующие t-статистики свидетельствуют о ненадежности этих коэффициентов.
Для выявления мультиколлинеарности можно использовать критерий Фаррара-Глобера, включающего следующие шаги.
Нормализация переменных:
1)
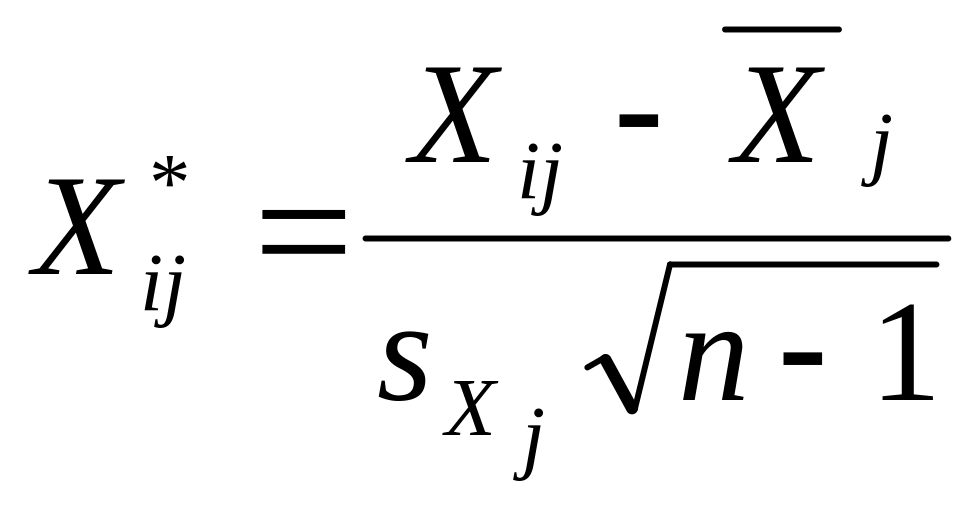 ,
или 2)
,
или 2)
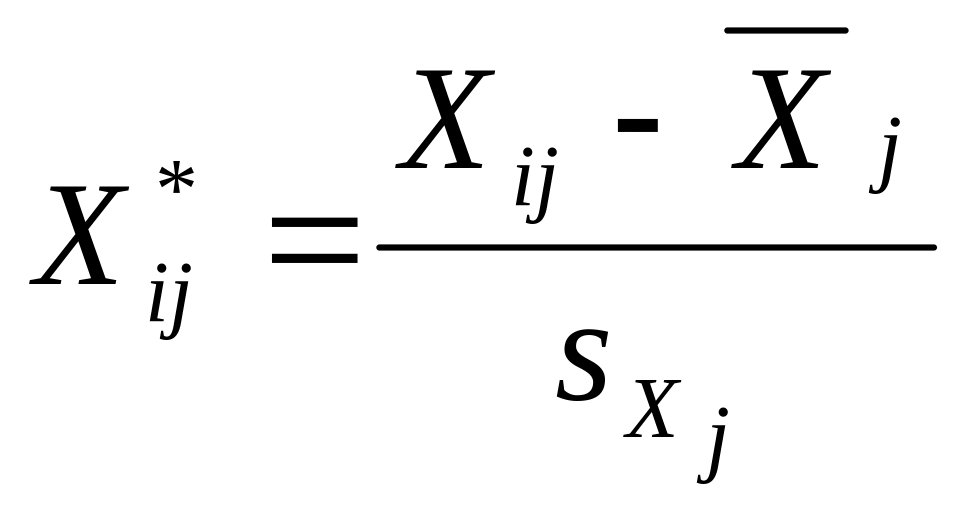 ,
,
где n – число наблюдений
![]() ;
р – количество объясняющих
переменных
;
р – количество объясняющих
переменных
![]() ;
;
![]() - средняя арифметическая j-й
объясняющей переменной;
- средняя арифметическая j-й
объясняющей переменной;
![]() -
среднее квадратичное (стандартное)
отклонение j-й
объясняющей переменной.
-
среднее квадратичное (стандартное)
отклонение j-й
объясняющей переменной.
Определение корреляционной матрицы объясняющих переменных:
![]() ,
или
,
или
![]() ,
,
где
![]() -
матрица нормализованных переменных,
-
матрица нормализованных переменных,
![]() -
транспонированная матрица нормализованных
переменных.
-
транспонированная матрица нормализованных
переменных.
Определение критерия 2:
2
= –
![]() ,
,
где
![]() -
определитель корреляционной матрицы.
-
определитель корреляционной матрицы.
Полученное значение
критерия 2
сравнивается с табличным при
![]() степенях
свободы и уровне значимости .
Если 2факт
> 2табл,
то в массиве независимых переменных
существует мультиколлинеарность.
степенях
свободы и уровне значимости .
Если 2факт
> 2табл,
то в массиве независимых переменных
существует мультиколлинеарность.
Вычисление обратной матрицы:
С = R-1
=
![]() .
.
Расчет F-критериев:
![]() ,
,
где
![]() - диагональные элементы матрицы С.
- диагональные элементы матрицы С.
Фактические значения критериев сравнивают с табличными значениями при 1 = p – 1, 2 = n – p степенях свободы и ур овне значимости . Если Fj > Fтабл, то соответствующая i-я независимая переменная мультиколлинеарна с остальными.
Определение частных коэффициентов корреляции:
![]() ,
,
где
![]() – элемент матрицы С, расположенный в
j-й строке
и к-м столбце;
и
– элемент матрицы С, расположенный в
j-й строке
и к-м столбце;
и
![]() - диагональные элементы матрицы С.
- диагональные элементы матрицы С.
Вычисление t-критериев:
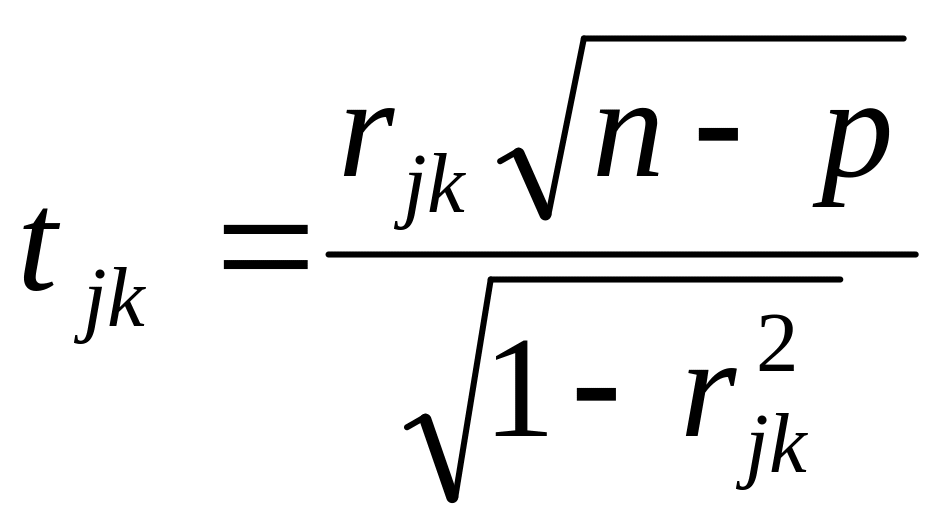 .
.
Фактические
значения t-критериев
сравнивают с табличными при n
– p степенях свободы и уровне
значимости . Если
![]() ,
то между объясняющими переменными Хk
и Xj существует мультиколлинеарность.
,
то между объясняющими переменными Хk
и Xj существует мультиколлинеарность.
Пример применения алгоритма Фаррара-Глобера рассмотрим в следующем разделе.
6. ПОСТРОЕНИЕ И АНАЛИЗ ЭКОНОМЕТРИЧЕСКОЙ МОДЕЛИ СРЕДСТВАМИ EXCEL. ИССЛЕДОВАНИЕ МОДЕЛИ. ПРОГНОЗИРОВАНИЕ С ИСПОЛЬЗОВАНИЕМ МОДЕЛИ
Построить эконометрическую модель зависимости производительности труда от основных производственных факторов.
Проверить статистическую значимость модели и оценок ее параметров. Сделать выводы.
Проверить выполнение основных предпосылок классической регрессионной модели.
Осуществить прогноз производительности труда на следующие четыре месяца, если заданы ожидаемые значения факторов, влияющих на нее. Исходные данные приведены в табл. 6.1.
Таблица 6.1
Месяц |
ПТ, тыс.грн./чел.-ч |
Фондовооружен-ность труда тыс.грн./чел |
Коэффициент текучести кадров, % |
Потери рабочего времени, % |
Стаж работы, лет |
1 |
52 |
72 |
13,0 |
2,7 |
5,0 |
2 |
53 |
74 |
12,5 |
2,8 |
5,5 |
3 |
50 |
72 |
12,0 |
3,0 |
5,0 |
4 |
51 |
73 |
11,0 |
3,2 |
6,0 |
5 |
54 |
70 |
10,1 |
3,2 |
7,0 |
6 |
55 |
67 |
9,0 |
3,3 |
8,0 |
7 |
57 |
67 |
8,5 |
3,4 |
10,0 |
8 |
52 |
62 |
8,2 |
3,6 |
10,0 |
9 |
60 |
72 |
8,0 |
3,7 |
10,5 |
10 |
60 |
72 |
5,5 |
3,7 |
11,0 |
11 |
62 |
74 |
5,0 |
3,4 |
13,0 |
12 |
64 |
75 |
4,7 |
4,0 |
10,0 |
13 |
65 |
76 |
4,6 |
4,2 |
12,0 |
14 |
67 |
80 |
4,0 |
4,3 |
13,0 |
15 |
67 |
82 |
4,1 |
4,7 |
14,0 |
16 |
62 |
84 |
4,2 |
4,8 |
14,5 |
17 |
63 |
84 |
4,5 |
4,8 |
15,5 |
18 |
66 |
87 |
4,0 |
4,9 |
17,0 |
19 |
68 |
90 |
4,0 |
5,0 |
16,5 |
20 |
70 |
92 |
3,0 |
4,7 |
17,5 |
21 |
|
92 |
4,0 |
5,2 |
17,6 |
22 |
|
93 |
5,0 |
5,3 |
17,7 |
23 |
|
93 |
5,0 |
5,4 |
17,8 |
24 |
|
94 |
6,0 |
5,4 |
17,9 |
РЕШЕНИЕ