

2. Элементы теории корреляции
Расчеты коэффициентов корреляции, регрессии достаточно трудоемки. Это объясняется тем, что приходится обрабатывать большое количество исходных данных; ведь одно наблюдение дает сразу две величины. Однако нужно иметь в виду, что если объем выборки невелик, то расчеты этих коэффициентов несложны. При малых выборках общую корреляционную таблицу не составляют, а результат наблюдений оставляют в том виде, каким он получается непосредственно в опыте, т. е. в виде так называемой простой корреляционной таблицы. В такой таблице каждому номеру наблюдений соответствует пара наблюдавшихся значений случайных величин. Конечно, вычисленный по малому числу наблюдений коэффициент в целом имеет меньшую надежность. В тех случаях, когда известен общий вид зависимости между средней одной величины и значениями другой, параметры этой зависимости могут быть найдены методом наименьших квадратов.
2.1. Линейная корреляция
Рассмотрим выборку
двумерной случайной величины (Х,
Y)
. Примем в качестве оценок условных
математических ожиданий компонент их
условные средние значения, а именно:
условным
средним
![]() назовем
среднее арифметическое наблюдавшихся
значений Y,
соответствующих Х
= х. Аналогично
условное
среднее
назовем
среднее арифметическое наблюдавшихся
значений Y,
соответствующих Х
= х. Аналогично
условное
среднее
![]() - среднее
арифметическое наблюдавшихся значений
Х,
соответствующих Y
= y.
Введем уравнения регрессии Y
на Х и
Х
на Y:
- среднее
арифметическое наблюдавшихся значений
Х,
соответствующих Y
= y.
Введем уравнения регрессии Y
на Х и
Х
на Y:
M (Y / x) = f (x), M ( X / y ) = φ (y).
Условные средние и являются оценками условных математических ожиданий и, следовательно, тоже функциями от х и у, то есть
= f*(x) - (1)
- выборочное уравнение регрессии Y на Х,
= φ*(у) - (2)
- выборочное уравнение регрессии Х на Y.
Соответственно функции f*(x) и φ*(у) называются выборочной регрессией Y на Х и Х на Y , а их графики – выборочными линиями регрессии. Выясним, как определять параметры выборочных уравнений регрессии, если этих уравнений известен.
Пусть изучается двумерная случайная величина (Х, Y), и получена выборка из п пар чисел (х1, у1), (х2, у2),…, (хп, уп). Будем искать параметры прямой линии среднеквадратической регрессии Y на Х вида
Y = ρyxx + b , (3)
Подбирая параметры ρух и b так, чтобы точки на плоскости с координатами (х1, у1), (х2, у2), …, (хп, уп) лежали как можно ближе к прямой (3). Используем для этого метод наименьших квадратов и найдем минимум функции
![]() .
(4)
.
(4)
Приравняем нулю соответствующие частные производные:
 .
.
В результате получим систему двух линейных уравнений относительно ρ и b:
 .
(5)
.
(5)
Ее решение позволяет найти искомые параметры в виде:
 . (6)
. (6)
При этом предполагалось, что все значения Х и Y наблюдались по одному разу.
Теперь рассмотрим случай, когда имеется достаточно большая выборка (не менее 50 значений), и данные сгруппированы в виде корреляционной таблицы:
Y |
X |
||||
x1 |
x2 |
… |
xk |
ny |
|
y1 y2 … ym |
n11 n12 … n1m |
n21 n22 … n2m |
… … … … |
nk1 nk2 … nkm |
n11+n21+…+nk1 n12+n22+…+nk2 …………….. n1m+n2m+…+nkm |
nx |
n11+n12+…+n1m |
n21+n22+…+n2m |
… |
nk1+nk2+…+nkm |
n=∑nx = ∑ny |
Здесь nij
– число появлений в выборке пары чисел
(xi,
yj).
Поскольку
![]() ,
заменим в системе (5)
,
заменим в системе (5)
![]()
![]() , где пху
– число появлений пары чисел (х,
у). Тогда
система (5) примет вид:
, где пху
– число появлений пары чисел (х,
у). Тогда
система (5) примет вид:
 .
(7)
.
(7)
Можно решить эту систему и найти параметры ρух и b, определяющие выборочное уравнение прямой линии регрессии:
![]() .
.
Но чаще уравнение регрессии записывают в ином виде, вводя выборочный коэффициент корреляции. Выразим b из второго уравнения системы (7):
![]() .
.
Подставим это
выражение в уравнение регрессии:
![]() .
Из (7)
.
Из (7)
![]() ,
(8)
,
(8)
где
![]() Введем понятие выборочного
коэффициента корреляции
Введем понятие выборочного
коэффициента корреляции
![]()
и умножим равенство
(8) на
![]() :
:
![]() ,
откуда
,
откуда
![]() .
Используя это соотношение, получим
выборочное уравнение прямой линии
регрессии Y
на Х
вида
.
Используя это соотношение, получим
выборочное уравнение прямой линии
регрессии Y
на Х
вида
![]() .
(9)
.
(9)
Коэффициент корреляции – безразмерная величина, которая служит для оценки степени линейной зависимости между Х и Y: эта связь тем сильнее, чем ближе |r| к единице.
Для качественной оценки тесноты корреляционной связи между X и Y можно воспользоваться таблицей Чеддока (табл.1):
Таблица 1
Диапазон изменения | rB | |
0,1-0,3 |
0,3-0,5 |
0,5-0,7 |
0,7-0,9 |
0,9-0,99 |
Характер тесноты связи |
слабая |
умеренная |
заметная |
высокая |
весьма высокая |
Итак,
если для
выборки двумерной случайной величины
(X,
Y):
{(xi,
yi),
i
= 1, 2,..., n}
вычислены выборочные средние
и
![]() и выборочные средние квадратические
отклонения σх
и σу,
то по этим данным можно вычислить
выборочный
коэффициент корреляции
и выборочные средние квадратические
отклонения σх
и σу,
то по этим данным можно вычислить
выборочный
коэффициент корреляции
![]()
и получить линейные уравнения, описывающие связь между Х и Y, которые называются выборочным уравнением прямой линии регрессии Y на Х:
![]()
и выборочным уравнением прямой линии регрессии Х на Y :
![]() .
.
Пример. Для выборки двумерной случайной величины
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
xi |
1,2 |
1,5 |
1,8 |
2,1 |
2, 3 |
3,0 |
3,6 |
4,2 |
5,7 |
6,3 |
yi |
5,6 |
6,8 |
7,8 |
9,4 |
10,3 |
11,4 |
12,9 |
14,8 |
15,2 |
18,5 |
вычислить выборочные средние, выборочные средние квадратические отклонения, выборочный коэффициент корреляции и составить выборочное уравнение прямой линии регрессии Y на Х.
![]()
![]()
![]() Для определения
выборочного коэффициента корреляции
вычислим предварительно
Для определения
выборочного коэффициента корреляции
вычислим предварительно
![]() Тогда
Тогда
![]() Выборочное уравнение
прямой линии регрессии Y
на Х имеет
вид:
Выборочное уравнение
прямой линии регрессии Y
на Х имеет
вид:
![]() или
или
![]() ◄
◄
Пример.
По заданной корреляционной таблице
найти выборочные средние
![]() среднеквадратические отклонения Χ,
Υ,
коэффициент корреляции ρΧΥ
и уравнение линейной регрессии Y
на X.
Вычислить условные средние
среднеквадратические отклонения Χ,
Υ,
коэффициент корреляции ρΧΥ
и уравнение линейной регрессии Y
на X.
Вычислить условные средние
![]() по дан-ным таблицы и найти наибольшее
их отклонение от значений, вычисляемых
из уравнения регрессии.
по дан-ным таблицы и найти наибольшее
их отклонение от значений, вычисляемых
из уравнения регрессии.
Y X |
0 |
2 |
4 |
6 |
8 |
nX |
1 |
3 |
|
|
|
|
3 |
3 |
2 |
3 |
5 |
|
|
10 |
5 |
|
9 |
8 |
|
|
17 |
7 |
|
|
2 |
6 |
|
8 |
9 |
|
|
|
4 |
1 |
5 |
11 |
|
|
|
|
7 |
7 |
nY
|
5 |
12 |
15 |
10 |
8 |
50 |
Вычислим выборочные средние и среднеквадратические отклонения для X,Y
![]()

Выборочный коэффициент корреляции между Х и У отыскивается по формуле
![]()
Согласно таблице

откуда
![]()
Выборочное линейное уравнение регрессии У на Х имеет вид
![]()
или, с учётом вычисленных значений,
![]()
Условное среднее при x = xi вычисляется по формуле
![]()
где
![]() -
число выборочных значений yj
, наблюдавшихся
при данном xi
. Согласно
данным из таблицы находим
-
число выборочных значений yj
, наблюдавшихся
при данном xi
. Согласно
данным из таблицы находим

Значения условных средних , отыскиваемые по уравнению регрессии:
![]()
![]()

Отклонения значений ,
![]()
будут d1 = 0-0.45=-0.45; d2 = 2.6- 1.96 = 0.65; d3 = -0.51, d4 = 0.55; d5 = -0.05;
d6 = 0.05. Наибольшее по абсолютной величине отклонение равно 0.65. ◄
Пример. Выборочно обследовано 100 снабженческо-сбытовых предприятий некоторого региона по количеству работников X и объёмам складской реализации Y (д.е.). Результаты представлены в корреляционной таблице;
X У |
5 |
15 |
25 |
35 |
45 |
ny |
130 |
7 |
1 |
|
|
|
8 |
132 |
2 |
7 |
1 |
|
|
10 |
134 |
1 |
5 |
4 |
1 |
|
11 |
136 |
|
1 |
15 |
10 |
8 |
34 |
138 |
|
|
3 |
12 |
15 |
30 |
140 |
|
|
|
1 |
6 |
7 |
nх |
10 |
14 |
23 |
24 |
29 |
n=100 |
По данным исследования требуется:
1) в прямоугольной системе координат построить эмпирические ломаные регрессии Y на X и X на Y, сделать предположение в виде корреляционной связи;
2) оценить тесноту линейной корреляционной связи;
3) проверить гипотезу о значимости выборочного коэффициента корреляции, при уровне значимости α=0,05;
4) составить линейные уравнения регрессии У на X и X на У, построить их графики в одной системе координат;
5) используя полученные уравнения регрессии, оценить ожидаемое среднее значение признака Y при х=40 чел.; дать экономическую интерпретацию полученных результатов.
Для построения эмпирических ломаных регрессии вычислим условные средние
 и
и
 Вычисляем
.
Так
как при х=5 признак Y имеет распределение
Вычисляем
.
Так
как при х=5 признак Y имеет распределение
YY |
130 |
132 |
134 |
ni |
7 |
2 |
1 |
то
условное среднее
![]() .
.
При х=15 признак Y имеет распределение
Y |
130 |
132 |
134 |
136 |
ni |
1 |
7 |
5 |
1 |
тогда
![]() .
.
Аналогично
вычисляются все
![]() и
и
![]() .
Получим
таблицы, выражающие корреляционную
зависимость Y от X (табл.2) и X от Y (табл.3).
.
Получим
таблицы, выражающие корреляционную
зависимость Y от X (табл.2) и X от Y (табл.3).
Таблица 2
x |
5 |
15 |
25 |
35 |
45 |
|
130,8 |
132,86 |
135,74 |
137,08 |
137,86 |
Таблица 3
y |
130 |
132 |
134 |
136 |
138 |
140 |
|
6,25 |
14 |
19,54 |
32,35 |
39 |
43,57 |
В
прямоугольной системе координат построим
точки Аi(хi,![]() ),
соединив их отрезками, получим эмпирическую
линию регрессии Y на X. Аналогично строятся
точки В
j(
),
соединив их отрезками, получим эмпирическую
линию регрессии Y на X. Аналогично строятся
точки В
j(![]() ,yj)
и эмпирическая линия регрессии X на Y
(см. рис.).
,yj)
и эмпирическая линия регрессии X на Y
(см. рис.).


Построенные
эмпирические ломаные регрессии Y на X и
X на Y свидетельствуют о том, что между
количеством работающих (X) и объёмом
складских реализаций (Y) существует
линейная зависимость. Из графика видно,
что с увеличением X величина
![]() также
увеличивается, поэтому можно выдвинуть
гипотезу о прямой линейной корреляционной
зависимости между количеством работающих
и объёмом складских реализаций.
также
увеличивается, поэтому можно выдвинуть
гипотезу о прямой линейной корреляционной
зависимости между количеством работающих
и объёмом складских реализаций.
2. Оценим тесноту связи. Вычислим выборочный коэффициент корреляции, предварительно вычислив характеристики по формулам
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() :
:
![]() ;
;
![]() ;
;
![]() ;
;
![]()
![]() ;
;
![]()

![]() .
.
Это значение rB говорит о том, что линейная связь между количеством работников и объемом складских реализаций высокая. Этот вывод подтверждает первоначальное предположение, сделанное исходя из графика.
3. Запишем теоретические уравнения линейной регрессии:
![]() ,
,
![]() .
.
Подставляя в эти уравнения найденные величины, получаем искомые уравнения регрессии:
1) уравнение регрессии Y на X:
![]() ,
или
,
или
![]() ;
;
2) уравнение регрессии X на Y:
![]() ,
или
,
или
![]() .
.
П остроим
графики найденных уравнений регрессии.
Зададим координаты двух точек,
удовлетворяющих уравнению
остроим
графики найденных уравнений регрессии.
Зададим координаты двух точек,
удовлетворяющих уравнению
![]() .
Пусть х = 10, тогда
.
Пусть х = 10, тогда
![]() ,
А1(10; 132,41), Если х = 40, тогда
,
А1(10; 132,41), Если х = 40, тогда
![]() ,
А2(40; 137,51). Аналогично находим
точки, удовлетворяющие уравнению
,
А2(40; 137,51). Аналогично находим
точки, удовлетворяющие уравнению
![]() ,
В1(10,2; 131), В2(43; 139). Графики
прямых линий регрессии изображены ниже
на рисунке.
,
В1(10,2; 131), В2(43; 139). Графики
прямых линий регрессии изображены ниже
на рисунке.
![]()
Контроль:
точка пересечения прямых линий регрессии
имеет координаты
![]() .
В нашем примере: С(29,8; 135,78).
.
В нашем примере: С(29,8; 135,78).
4. Найдём среднее значение Y при х=40 чел., используя уравнение регрессии Y на X. Подставим в это уравнение х=40, получим
![]() .
.
Ожидаемое в генеральной совокупности среднее значение объёма складских реализаций при заданном количестве работников (х=40) составляет 137,51 д.е.
Замечание 1. Если в корреляционной таблице даны интервальные распределения, то за значения вариант надо брать середины частичных интервалов.
Замечание 2. Если данные наблюдений над признаками X и Y заданы в виде корреляционной таблицы с равноотстоящими вариантами, то целесообразно перейти к условным вариантам:
![]() ,
,
![]() ,
,
где h1 – шаг, т.е. разность между двумя соседними вариантами xi; С1 – «ложный нуль» вариант xi (в качестве «ложного нуля» удобно принять варианту, которая расположена примерно в середине ряда); h2 – шаг вариант Y; С2 – «ложный нуль» вариант Y.
В этом случае выборочный коэффициент корреляции
![]() ,
,
где
![]() ,
,
![]() ,
,
![]()
![]() ,
,
![]() .
.
Зная
эти величины, находят
![]() ,
,
![]() ,
σх,
σу
по
формулам
,
σх,
σу
по
формулам
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Найденные величины подставляем в уравнения (10).
Так в
данном примере С1
=25, h1=10,
С2=136,
h2=2;
![]() ,
,
![]() .
.
Корреляционная таблица в условных вариантах имеет вид
U V |
-2 |
-1 |
0 |
1 |
2 |
ny |
-3 |
7 |
1 |
|
|
|
8 |
-2 |
2 |
7 |
1 |
|
|
10 |
-1 |
1 |
5 |
4 |
1 |
|
11 |
0 |
|
1 |
15 |
10 |
8 |
34 |
1 |
|
|
3 |
12 |
15 |
30 |
2 |
|
|
|
1 |
6 |
7 |
nx |
10 |
14 |
23 |
24 |
29 |
n=100 |
По этой таблице и приведённым выше формулам находим характеристики:
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
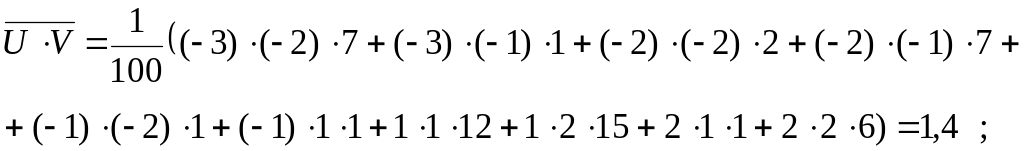
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
В результате получаем те же уравнения линейной регрессии:
![]() ;
.◄
;
.◄