

ms_labs
.pdfОскільки поділ на кластери здійснюється практично вибором відстаней між ними за шкалою ординати, то вибір кількості кластерів в першу чергу визначається поставленою задачею.
Застосування процедури ієрархічного агломеративного кластерного аналізу, дає на відміну від інших методів весь спектр кластерів, а вже вибір тої чи іншої кількості кластерів, тобто рівня дерева належить досліднику.
Хід роботи
Приведені алгоритми: побудови матриці близькостей, знаходження параметрів дендрограми та її побудови, а також інтерпретації кластерного аналізу на підставі усереднених характеристик кластерів можуть бути застосовані і до завдань, запропонованих викладачами. Тому хід роботи означає проведення кластерного аналізу в той самий спосіб як наведений приклад, лише з іншими даними.
Крім того вказується викладачем вид відстані та характер стратегії, які подані в табл. 2.
Умови для завдань і проведення агломеративного ієрархічного кластерного аналізу здійснюється за вказаними: формулою нормування, метрикою та стратегією, що наведені в табл. 5.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблиця 2 |
|
|
|
|
|
Вибір формул для індивідуальних завдань |
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
№ |
Формула |
Вид відстані (метрика) |
|
|
|
Стратегія |
||||||||||||||||||||
з/п |
|
|
|
|||||||||||||||||||||||
нормування |
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Стратегія |
||||
|
|
|
x xсер |
|
N |
|
|
|
|
|
найближчого сусіда. |
|||||||||||||||
|
z |
|
|
|
|
|
|
DE (x1, x2 ) |
(x1 j x2 j )2 |
|
i |
|
j |
0.5 , |
||||||||||||
|
|
|
s |
|||||||||||||||||||||||
|
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0, 0.5. |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
2 |
|
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
|
Стратегія |
||||
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
найдальшого сусіда. |
|||||||||||
|
|
|
|
|
|
|
||||||||||||||||||||
|
z |
|
|
|
|
|
DM x1 x2 |
|
|
|
x1 j x2 j |
|
|
|
i |
j |
0.5 , |
|||||||||
|
xmax |
|||||||||||||||||||||||||
|
|
|
|
|
i1 |
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
0, |
0.5. |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
3 |
|
|
x xmin |
|
|
|
|
|
|
|
|
|
|
|
|
Гнучка стратегія. |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
DЧ (x1, x2 ) max |
|
x1 j x2 j |
|
|
|
|
|
1, |
||||||||||||||
|
z x |
|
i |
j |
||||||||||||||||||||||
|
|
|
x |
|
j |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
i j , 1, 0 . |
||||||||||||||||
|
|
max |
min |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
91
ЛАБОРАТОРНА РОБОТА № 4
КОРЕЛЯЦІЙНИЙ АНАЛІЗ ЧАСОВИХ ПОСЛІДОВНОСТЕЙ
ВСТУП
У практичній діяльності системного аналітика часто зустрічаються ситуації, в яких оцінку однієї з властивостей об'єкта необхідно здійснювати з врахуванням оцінки іншої властивості. У цьому випадку виникає необхідність визначення взаємного впливу властивостей. Закономірності такого впливу досить складно описати математичними моделями. У подібних ситуаціях використовують кореляційну оцінку показників, встановлюючи елемент якісної, експертної оцінки впливу одного показника на інший. Метою дослідника при вирішенні зазначеної задачі є не тільки знаходження кореляційної залежності між двома властивостями об'єкта, а й отримання якісної (експертної) оцінки впливу однієї властивості на іншу.
Під кореляційним аналізом розуміють групу методів, що дозволяють виявляти наявність і ступінь взаємозв'язку між кількома параметрами, що змінюються випадковим чином. Міра такого взаємозв'язку оцінюється спеціальними числовими характеристиками, а також їх статистиками, що визначають ступінь близькості цього взаємозв'язку до функціонального, який може існувати між параметрами, що володіють детермінованим характером зміни.
Кореляційний зв'язок з'являється, коли одному і тому ж значенню аргументу (незалежної змінної) відповідає низка значень функції (залежної змінної). Тоді зв'язок виявляється у вигляді тенденції зміни середніх значень функції залежно від змін аргументу. Цим кореляційний зв'язок відрізняється від функціонального, який виникає у разі, коли заданому значенню аргументу відповідає цілком певне значення функції. По суті кореляційний зв'язок є неповним, оскільки залежність між функцією і аргументом в кожному конкретному випадку схильна до впливу з боку інших чинників (які найчастіше мають мінливий характер).
Найбільш повно в статистиці розроблена методологія парної кореляції, що розглядає вплив варіації однієї факторної ознаки на результатну.
Дослідження парної кореляції здійснюється на основі кореляційного
92
аналізу, передбачає послідовне вирішення низки завдань:
|
виявлення зв'язку; |
|
опис зв'язку в табличній і графічній формах; |
|
вимірювання тісноти зв'язку; |
|
формулювання висновків про характер існуючого зв'язку. |
Основні |
завдання кореляційного аналізу – це визначення і вираження |
форми аналітичної залежності результативної ознаки y від факторних ознак xi . Відмінною рисою кореляційного аналізу є вимірювання тісноти зв'язку між y і x . Його основними числовими характеристиками є коефіцієнт
кореляції і кореляційне відношення.
Виділяють такі етапи кореляційного аналізу:
–виявлення взаємозв'язку між ознаками;
–визначення форми зв'язку;
–визначення сили ( тісноти ) і напрямку зв'язку .
Інтерпретуючи результати кореляційного аналізу потрібно мати на увазі, що коефіцієнт кореляції є статистичним показником, який не вказує на те, що досліджувані величини знаходяться в причинно-наслідковому зв'язку. Тому будь-яке трактування кореляційної залежності повинне ґрунтуватися на інформації про суть і характер досліджуваних експериментальних даних та процесів, яким вони відповідають.
До переваг кореляційного аналізу можна віднести можливість створення нового правила взаємодії функцій одна з одною, а також оцінку взаємодії функцій отриманих невідомим шляхом.
Недоліками є те, що всі результати, отримані за допомогою цієї методики можна використовувати лише в області даного дослідження або близько до нього. Після виявлення стохастичних зв'язків між досліджуваними змінними величинами дослідник приступає до математичного опису виявленої ним і цікавої для нього залежності.
Мета і завдання лабораторної роботи
Метою роботи є ознайомлення з методами кореляційного аналізу експериментальних даних, поданих часовими послідовностями або послідовностями випадкових чисел (вибірками).
Для цього потрібно:
-побудувати кореляційне поле;
-визначити значення коефіцієнта кореляції;
-перевірити гіпотези щодо значущості коефіцієнта кореляції;
93
- побудувати кореляційну матрицю.
І. Теоретичні відомості
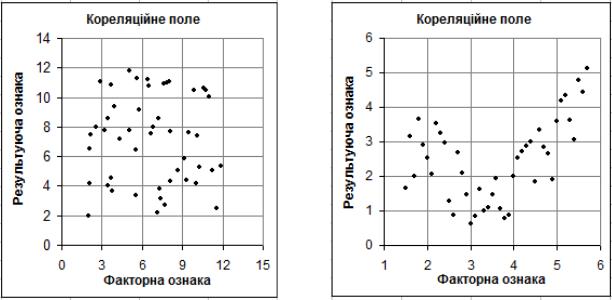
Кореляційне поле. У своїй практиці дослідник часто виявляє існування певних залежностей між отриманими експериментальними даними та впливаючими на результат чинниками. Переважно, вже на підставі візуального аналізу поля кореляції можна висунути гіпотезу щодо існуючого зв'язку між усіма можливими значеннями X і Y: лінійний або нелінійний, сильний, слабкий або відсутній. Переважно такий зв'язок є випадковим.
Графічне подання взаємозв’язку між двома досліджуваними послідовностями називається кореляційним полем або полем кореляції або діаграмою розсіювання. Графічний метод забезпечує наочне зображення форми зв'язку між цими послідовностями. Для цього, в прямокутній системі координат будують графік – по осі ординат відкладають індивідуальні значення однієї послідовності, вибраної в якості результативної ознаки Y , а по осі абсцис - індивідуальні значення іншої – факторної ознаки X . Власне сукупність точок результативної і факторної ознак, як зображено на рис. 7.1
називається полем кореляції.
а б
Рис. 7.1. Візуальна оцінка характеру зв’язку: а – вказує на його відсутність, б – на нелінійність.
Отже, кореляційне поле – це сукупність точок у прямокутній системі координат, абсциса кожної з яких відповідає значенню факторної ознаки (х), а
94
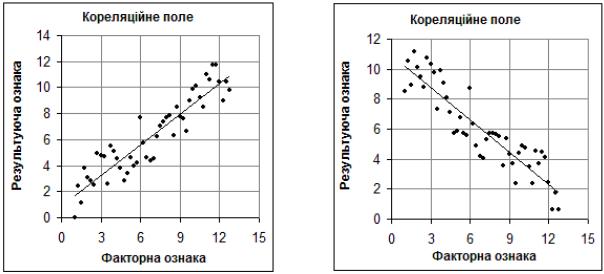
ордината – значенню результативної ознаки (у) певної одиниці спостереження. Кількість точок на графіку відповідає кількості одиниць спостереження. Використовується для аналізу наявності та характеру (напряму) зв’язку між результатами двох вибірок спостережень. Розміщення точок на графіку свідчить про наявність і напрям зв’язку. Загалом, локалізація точок кореляційного поля вказує на наявність прямого, оберненого зв’язку між ознаками, або його відсутність, а також на форму лінії регресії (рис. 7.2).
а |
б |
Рис. 7.2. Види зв’язку та лінія регресії: а – прямий (додатний) лінійний зв’язок, б – обернений (від’ємний) лінійний зв’язок.
Розміщення точок на кореляційному полі дозволяє судити про характер залежності, наприклад: лінійна, параболічна, гіперболічна, логістична, логарифмічна, експонентна, показникові або відсутність залежності.
Кореляційні зв'язки можна вивчати на якісному рівні з діаграм розсіяння емпіричних значень змінних X і Y і відповідним чином їх інтерпретувати. Так, наприклад, якщо підвищення рівня однієї змінною супроводжується підвищенням рівня іншої, то йдеться про додатну кореляцію або прямий зв'язок (рис. 7.2а,). Якщо ж зростання однієї змінної супроводжується зниженням значень іншої, то маємо справу з від’ємною кореляцією або оберненим зв'язком (рис. 7.2б,). Нульовою або відсутньою називається кореляція за відсутності зв'язку змінних (рис. 7.1а). Проте нульова загальна кореляція може свідчити лише про відсутність лінійної залежності, а не взагалі про відсутність будь якого статистичного зв'язку .
При цьому функцію, графік якої відповідає розміщенню точок називають теоретичною лінією регресії. Для вибору тієї чи іншої форми кореляційної
95
залежності, треба порівняти уявну емпіричну лінію регресії з графіками відомих функцій.
Методи кореляційного аналізу широко застосовуються для виявлення та опису стохастичних залежностей між випадковими величинами – якими переважно є зібрані або експериментальні дані.
Для експериментального вивчення залежності між випадковими величинами Y і Х проводять деяку кількість незалежних дослідів.
Результат i -го досвіду дає пару значень xi , yi , де i 1, 2, , n . Отже, досліджувані послідовності можна подати так:
X  x1, x2 , , xn
x1, x2 , , xn  ; Y
; Y  y1, y2 , , yn
y1, y2 , , yn  .
.
Якщо послідовності подати у вигляді функцій, що залежать від одного аргументу, то, провівши кореляційний аналіз, можна встановити взаємний вигляд зв’язку між ними та його величину, при цьому обсяг даних має буди однаковий. Про наявність чи відсутність кореляції між двома випадковими величинами якісно можна судити з вигляду поля кореляції, відобразивши експериментальні пари точок на координатну площину.
Коефіцієнт кореляції.
Для кількісної оцінки тісноти зв'язку служить вибірковий коефіцієнт кореляції. Вибірковий коефіцієнт кореляції r за абсолютною величиною не перевищує одиниці. Для незалежних випадкових величин коефіцієнт кореляції дорівнює нулю, але він може бути рівний нулю для деяких залежних величин, які при цьому називаються некорельованими.
Для випадкових величин, що мають нормальний розподіл, відсутність кореляції означає і відсутність будь-якої залежності.
Вибірковий коефіцієнт кореляції не змінюється при зміні початку відліку і масштабу величин . Коефіцієнт кореляції характеризує не довільну залежність, а тільки лінійну. Лінійна імовірнісна залежність випадкових величин полягає в тому , що при зростанні однієї випадкової величини інша має тенденцію зростати (або спадати ) за лінійним законом.
Коефіцієнт кореляції характеризує ступінь тісноти лінійної залежності . У загальному випадку , коли величини X і Y пов'язані деякою стохастичною залежністю, коефіцієнт кореляції може мати значення в межах –1 ≤ r ≤ +1.
Відзначимо властивості коефіцієнта кореляції:
коефіцієнт парної кореляції обчислюється для кількісних ознак;
коефіцієнт кореляції симетричний, тобто не змінюється, якщо X і Y поміняти місцями;
96
коефіцієнт кореляції є величиною безрозмірною.
коефіцієнт кореляції не змінюється при зміні одиниць виміру ознак X
і Y.
величина коефіцієнта кореляції не змінюється від додавання до Х і Y невипадкових доданків;
величина коефіцієнта кореляції не змінюється від множення Х і Y на позитивні числа;
якщо одну з величин, не змінюючи іншу, помножити на –1 , то на –1 треба помножити і коефіцієнт кореляції.
Схема застосування кореляційного аналізу в практичних цілях приблизно така: є кілька параметрів, які спостерігаються протягом деякого проміжку часу, про які, за результатами спостережень (або з будь-яких апріорних міркувань), можна припустити, що вони можуть бути взаємопов'язані будь-яким чином.
Обчислення коефіцієнта кореляції здійснюють за такою формулою
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi x |
yi y |
|
|
|
|
|
|
|
|
|
|||||
rxy |
|
i 1 |
|
|
|
|
|
|
|
. |
|
|
|
|
|
(7.1) |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
n |
|
|
|
|
n |
|
|
|
|
|
|
|
||||||
|
|
|
|
xi x 2 |
|
yi y 2 |
|
|
|
|
|
|
|
|
|||||
|
|
|
|
i 1 |
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
В статистичній літературі рекомендують використовувати для |
|||||||||||||||||||
обчислення коефіцієнта кореляції такий вираз |
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
n |
|
|
n |
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n xi yi xi yi |
|
|
|
|
|
|
|
|
|
|||||
rxy |
|
|
|
|
i 1 |
|
|
i 1 |
i 1 |
|
|
|
|
|
|
|
. |
(7.2) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
||||||
|
|
n |
|
n |
|
n |
|
|
n |
|
2 |
|
|
||||||
|
|
n xi2 |
|
xi |
|
n yi2 |
|
yi |
|
|
|
|
|||||||
|
|
|
i 1 |
|
|
|
|
i 1 |
|
|
|
|
|
|
|
||||
|
|
|
i 1 |
|
|
i 1 |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
В цьому випадку відпадає потреба обчислювати відхилення біжучих значень від середньої величини, а це виключає помилки в розрахунках при округленні середніх величин.
Коефіцієнт кореляції rxy є випадковою величиною, оскільки
обчислюється для випадкових величин.
Сам по собі коефіцієнт кореляції не має змістовної інтерпретації. Проте
його квадрат R r 2 , який називають коефіцієнтом детермінації (позначається R і зазвичай виражається у %), має простий сенс – це показник того, наскільки зміни залежної ознаки пояснюються змінами незалежної.
97
Звизначення коефіцієнта детермінації випливає, що він приймає значення
вдіапазоні від 0 % до 100 %.
Якщо дві змінні функціонально лінійно залежні (точки на кореляційному полі лежать на одній прямій), то можна сказати, що зміна однієї з них повністю пояснюється зміною іншої, а це якраз той випадок, коли коефіцієнт детермінації дорівнює 100 % (при цьому коефіцієнт кореляції може дорівнювати як +1, так і – 1) .
Чим вище за модулем (за абсолютною величиною) значення коефіцієнта кореляції, тим сильніший зв'язок між ознаками.
Прийнято вважати, що коефіцієнти кореляції, які за модулем більше 0.7, вказують про сильний зв'язок (при цьому коефіцієнти детермінації > 50%, тобто одна ознака визначає іншу більш, ніж наполовину).
Коефіцієнти кореляції, які по модулю менше 0,7 , але більше 0,5 , говорять про зв'язок середньої сили (при цьому коефіцієнти детермінації менше 50 % , але більше 25%). Нарешті , коефіцієнти кореляції , які по модулю менше 0,5 , говорять про слабку зв'язку (при цьому коефіцієнти детермінації менше 25%).
Перевірка гіпотез відносно коефіцієнта кореляції
Стосовно нього можна висувати і перевіряти такі гіпотези:
Гіпотеза 1. Коефіцієнт кореляції значимо відрізняється від нуля, тобто між величинами є взаємний зв’язок.
Для перевірки цієї гіпотези обчислюють тестову статистику. Якщо тестова статистика є більшою за табличне значення, то коефіцієнт кореляції значимо відрізняється від нуля.
Гіпотеза 2. Значення коефіцієнта кореляції є значимим, якщо тестова статистика – розраховане значення перевищує табличне, крім того, ще визначають оцінку значущості коефіцієнта парної кореляції з використанням t - критерію Стьюдента, порівнюючи обчислене значення з табличним критерієм.
3. Чи є значимою відмінність між двома коефіцієнтами кореляції також встановлюють, порівнюючи тестову статистику з табличним значенням.
Кореляційна матриця.
В разі великого числа спостережень, коли коефіцієнти кореляції необхідно послідовно обчислювати для декількох вибірок, для зручності отримані коефіцієнти зводять в таблиці, які називають кореляційними матрицями.
Кореляційна матриця – це квадратна таблиця, в якій на перетині відповідних рядка і стовпця знаходиться коефіцієнт кореляції між
98
відповідними вибірками. Оскільки коефіцієнт кореляції є парною величиною, тобто обсяги обох вибірок, між якими визначають зв’язок мають бути однаковими, тому у випадку багатьох вибірок їхні обсяги мають бути однакові.
ІІ. Хід роботи
1. Побудова кореляційного поля.
Для побудови кореляційного поля використовуємо пакет (надбудову) «Аналіз даних», а в ньому функцію Генерація випадкових чисел, для якої вибираємо число змінних рівне 2, кількість випадкових чисел рівне 50, розподіл
– рівномірний, параметри – від -10 до 10, випадкове розсіювання рівне 2 (оскільки ми генеруємо дві вибірки), вихідний інтервал – $A$1. В результаті виконання операції OK, отримуємо дві вибірки рівномірно розподілених випадкових чисел обсягом по 50 значень в діапазоні від -10 до 10 в стовпчиках А1:А50 та В1:В50.
Далі, виділивши обидва стовпчики і використовуючи «Майстер діаграм → стандартні → тип → точкова» натискаємо кнопку «готово». В результаті отримаємо зображення кореляційного поля. Оскільки, «Майстер діаграм» за замовчуванням сполучає лініями послідовні значення необхідно позбутися цих ліній або в самому «Майстер діаграм» або, навівши на один з маркерів курсор клацнути правою кнопкою мишки і у вкладці «Формат ряду даних → Вид → Лінія» вибрати «Відсутня», а на вкладці «Маркери» вибрати потрібний вид, розмір та колір маркерів.
2. Визначення значення коефіцієнта кореляції двох вибірок.
В цьому випадку необхідно змоделювати дві вибірки випадкових величин. Для цього побудуємо на чернетці дві лінії регресії (не обов’язково
паралельні) в прямокутній площині розміром, наприклад 10 10 кв. одиниць, |
|
задаючи по дві точки для кожної. Нехай A1 x1; y1 і B1 x2; y2 точки початку і |
|
кінця першої лінії регресії, A2 x1; y1 і |
B2 x2; y2 – відповідно другої. |
Приймемо, що ці дві лінії є непаралельні, не перетинаються в межах нашої
площини і обидві утворюють додатні кути з віссю абсцис, а значення |
||||
координат їх точок є такі: A1 1;2 , |
B1 9;4 , |
A2 |
1;3 і |
B2 9;7 . За цими даними |
знайдемо рівняння першої і другої лінії за відомою формулою |
||||
y y y2 y1 |
x x |
|
||
1 |
x2 x1 |
|
1 |
|
|
|
|
||
– рівняння прямої, що проходить через дві точки.
99

В нашому випадку,
y 2 4 2 x 1 ,
9 1
y 3 7 3 x 1 ,
9 1
тобто це такі рівняння:
y 0.25 x 1.75 , y 0.5 x 2.5 .
Нехай обсяг вибірок становить n1 n2 50 . Генеруємо два стовпчики А1:А50 і В1:В50 рівномірно розподілених випадкових чисел. Далі використовуємо пакет (надбудову) «Аналіз даних», а в ньому функцію
Генерація випадкових чисел, для якої вибираємо число змінних рівне 2,
кількість випадкових чисел рівне 50, розподіл – рівномірний, параметри –
встановлюємо в межах від -1 до 1, випадкове розсіювання рівне 2 (оскільки ми генеруємо дві вибірки), вихідний інтервал – $A$1. В результаті виконання операції OK, отримуємо дві вибірки рівномірно розподілених випадкових чисел обсягом по 50 значень в діапазоні від -10 до 10 в стовпчиках А1: А50 та В1:В50.
Встановлюємо шкалу для осі абсцис. Для цього інтервал зміни x , який
лежить в межах від 1 до 9, розділимо на m 50 1 частин: 9 1 0.1632 .
49
Вкомірку D1 запишемо значення 1, а в комірку D2 – значення 1 , тобто 1,1632 і далі, використовуючи «автозаповнення» заповнимо стовпчик D1:D50.
Вкомірки F1 і G1 вставляємо формули « = 0,25*D1+1,75 » і « = 0,5*D1+2,5 »
відповідно, далі використовуючи автозаповнення визначаємо значення для стовпчиків F1:F50 та G1:G50. виділивши ці два стовпчики і використовуючи
«Майстер діаграм → стандартні → тип → графік» отримуємо зображення двох наших ліній.
Введемо в комірки J1 і K1 такі формули: « = F1+А1 » і « G1+В1 » відповідно і автозаповненням заповнюємо значення J1:J50 та K1:K50 відповідно. Використовуючи формули (7.1) та (7.2) обчислюємо між ними ступінь кореляційного зв’язку.
Далі, вказуємо комірку для значення коефіцієнта кореляції, наприклад під попередньою, за допомогою «Майстра функцій» викликаємо функцію КОРРЕЛ, яка має такий синтаксис
КОРРЕЛ(массив1;массив2)
100