

2.6.3. Нечеткий алгоритм к-средних (Fuzzy k-means)
Процедуру
алгоритма К-средних часто называют
«четкой» классификацией. В этом алгоритме
каждый объект выборки
![]() либо принадлежит, либо не принадлежит
к определенному классу. Алгоритм
К-средних может успешно применяться в
случае непересекающихся классов, т.е.
в случае, когда между классами можно
провести четкие границы. В противоположность
этому нечеткий алгоритм К-средних
реализует «мягкую» или «нечеткую»
классификацию и используется в тех
случаях, когда не представляется
возможным однозначно установить
принадлежность объекта к определенному
классу. В этом случае говорят, что каждый
объект
либо принадлежит, либо не принадлежит
к определенному классу. Алгоритм
К-средних может успешно применяться в
случае непересекающихся классов, т.е.
в случае, когда между классами можно
провести четкие границы. В противоположность
этому нечеткий алгоритм К-средних
реализует «мягкую» или «нечеткую»
классификацию и используется в тех
случаях, когда не представляется
возможным однозначно установить
принадлежность объекта к определенному
классу. В этом случае говорят, что каждый
объект
![]() может иметь определенную степень
принадлежности к каждому из классов.
Например, объект
может иметь определенную степень
принадлежности к каждому из классов.
Например, объект
![]() может принадлежать на 20% к первому
классу, на 65% ко второму и на 15% к третьему
классу, а объект
может принадлежать на 20% к первому
классу, на 65% ко второму и на 15% к третьему
классу, а объект
![]() - на 70% к первому, на 10% ко второму и на
20% к третьему.
- на 70% к первому, на 10% ко второму и на
20% к третьему.
Нечеткий алгоритм К-средних широко применяется для распознавания и классификации объектов с «нечеткими» признаками, например, в системах компьютерной обработки и распознавания цветных изображений, географии и геодезии при классификации почв и ландшафтов, метеорологии при предсказаниях изменений климата и др.
Идея нечеткого алгоритма К-средних основана на минимизации суммарной взвешенной среднеквадратичной ошибки
![]() (2.24)
(2.24)
при следующих условиях:
![]() для
любого
для
любого
![]() ;
;
![]() для
любого
для
любого
![]() ;
(2.25)
;
(2.25)
![]() для
любых
для
любых
![]() и
и
![]() .
.
Здесь
![]() – количество объектов в выборке;
– количество объектов в выборке;
![]() – количество классов;
– количество классов;
![]() -
«функция принадлежности», т.е. функция,
значение которой равно степени
принадлежности
-
«функция принадлежности», т.е. функция,
значение которой равно степени
принадлежности
![]() -го
объекта к
-го
объекта к
![]() -му
классу;
-му
классу;
![]() - квадрат расстояния между
- квадрат расстояния между
![]() -м
объектом и центром
-м
объектом и центром
![]() -го
класса в выбранной метрике (в дальнейшем
эту величину будем обозначать просто
-го
класса в выбранной метрике (в дальнейшем
эту величину будем обозначать просто
![]() )
.
)
.
Параметр
![]() в показателе степени в (2.24) определяет
собой «степень нечеткости», «степень
размытия» классов, или степень перекрытия
классов в конечном решении задачи
классификации. При
в показателе степени в (2.24) определяет
собой «степень нечеткости», «степень
размытия» классов, или степень перекрытия
классов в конечном решении задачи
классификации. При
![]() получится “четкая” классификация, а
при
получится “четкая” классификация, а
при
![]() решение приближается к максимальной
степени нечеткости. Выбор параметра
решение приближается к максимальной
степени нечеткости. Выбор параметра
![]() достаточно произволен и при использовании
данного алгоритма обычно требуется
многократно провести процедуру
классификации для различных
достаточно произволен и при использовании
данного алгоритма обычно требуется
многократно провести процедуру
классификации для различных
![]() ,
а затем выбрать наилучший результат.
Однако следует иметь ввиду, что очень
большие значения
,
а затем выбрать наилучший результат.
Однако следует иметь ввиду, что очень
большие значения
![]() приводят к тому, что каждый объект будет
иметь одинаковую степень принадлежности
ко всем классам и классы станут вообще
неразличимы. Кроме того, при использовании
различных метрик наилучшие результаты
будут получаться при различных значениях
параметра
приводят к тому, что каждый объект будет
иметь одинаковую степень принадлежности
ко всем классам и классы станут вообще
неразличимы. Кроме того, при использовании
различных метрик наилучшие результаты
будут получаться при различных значениях
параметра
![]() .
Так, например, для метрики Евклида
вначале рекомендуется выбирать
.
Так, например, для метрики Евклида
вначале рекомендуется выбирать
![]() ,
а для метрики Махаланобиса вначале
нужно взять меньшее значение
,
а для метрики Махаланобиса вначале
нужно взять меньшее значение
![]() .
.
Минимизация
функции
![]() с использованием условий (2.25) приводит
к следующему выражению для функции
принадлежности
с использованием условий (2.25) приводит
к следующему выражению для функции
принадлежности
![]() :
:
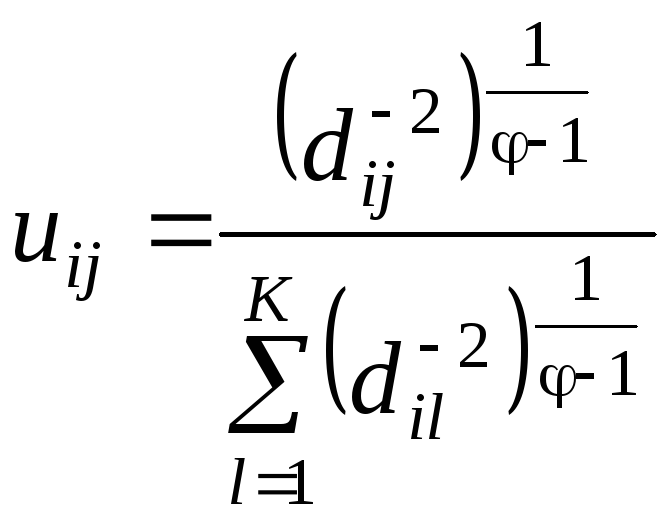 для
всех
для
всех
![]() и
и
![]() .
(2.26)
.
(2.26)
Тогда положения центров классов вычисляются следующим образом:
 для
всех
для
всех
![]() .
(2.27)
.
(2.27)
Перейдем теперь непосредственно к изложению словесного описания нечеткого алгоритма К-средних.
-
Зададим количество классов
 ,
значение для параметра нечеткости
,
значение для параметра нечеткости
 (
( )
и выберем метрику для вычисления
расстояний в пространстве существенных
признаков.
)
и выберем метрику для вычисления
расстояний в пространстве существенных
признаков. -
Задать точность вычислений
 .
Этот параметр используется для
прекращения вычислений. Если положения
центров всех классов на некоторой
итерации изменились по сравнению с их
положениями на предыдущей итерации на
величину, меньшую
.
Этот параметр используется для
прекращения вычислений. Если положения
центров всех классов на некоторой
итерации изменились по сравнению с их
положениями на предыдущей итерации на
величину, меньшую
 ,
то вычисления заканчиваются.
,
то вычисления заканчиваются. -
Задать максимально допустимое число итераций
 .
Этот параметр также используется для
прекращения вычислений. Если требуемая
точность
.
Этот параметр также используется для
прекращения вычислений. Если требуемая
точность
 еще не достигнута, но количество
проведенных итераций стало равно
еще не достигнута, но количество
проведенных итераций стало равно
 ,
то вычисления прекращаются, и выводится
сообщение о невозможности достигнуть
заданной точности
,
то вычисления прекращаются, и выводится
сообщение о невозможности достигнуть
заданной точности
 при данном числе итераций
при данном числе итераций
 .
Зададим начальное значение счетчика
итераций
.
Зададим начальное значение счетчика
итераций
 .
. -
Выбираем начальные положения центров классов
 .
Как и в «четком» алгоритме К-средних в
качестве
.
Как и в «четком» алгоритме К-средних в
качестве
 можно выбрать
можно выбрать
 первых объектов выборки, т.е.
первых объектов выборки, т.е.
 ,
,
 и т.д., либо случайным образом выбрать
и т.д., либо случайным образом выбрать
 произвольных объектов.
произвольных объектов. -
Вычисляем все компоненты функции принадлежности по формуле
 .
.
Для
этого нужно предварительно вычислить
в выбранной метрике квадраты расстояний
между всеми объектами и всеми центрами
классов, т.е. величины
![]() для всех
для всех
![]() и
и
![]() .
Если какая-либо из величин
.
Если какая-либо из величин
![]() или
или
![]() ,
где
,
где
![]() некоторое наперед заданное положительное
число
некоторое наперед заданное положительное
число
![]() ,
то для данных
,
то для данных
![]() и
и
![]() следует положить
следует положить
![]() .
.
-
Вычислив компоненты функции принадлежности для всех объектов, распределяем их по классам. Объект
 принадлежит к классу
принадлежит к классу
 ,
если
,
если
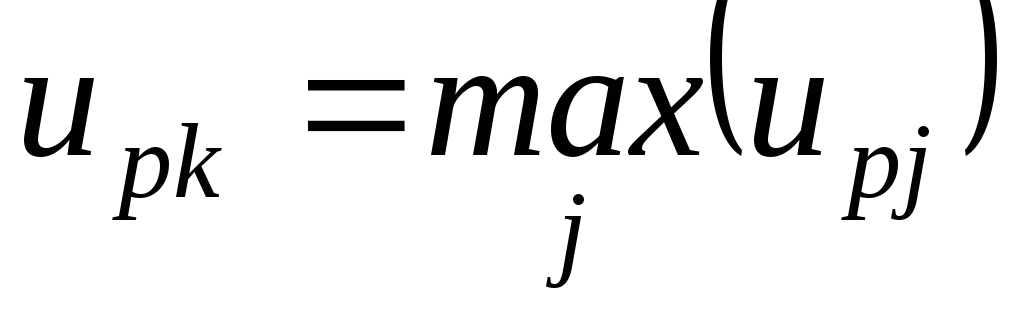 ,
то есть значение функции принадлежности
объекта для данного класса наибольшее.
,
то есть значение функции принадлежности
объекта для данного класса наибольшее. -
Увеличим счетчик итераций на единицу
 .
Вычислим новые положения центров
классов по формуле
.
Вычислим новые положения центров
классов по формуле
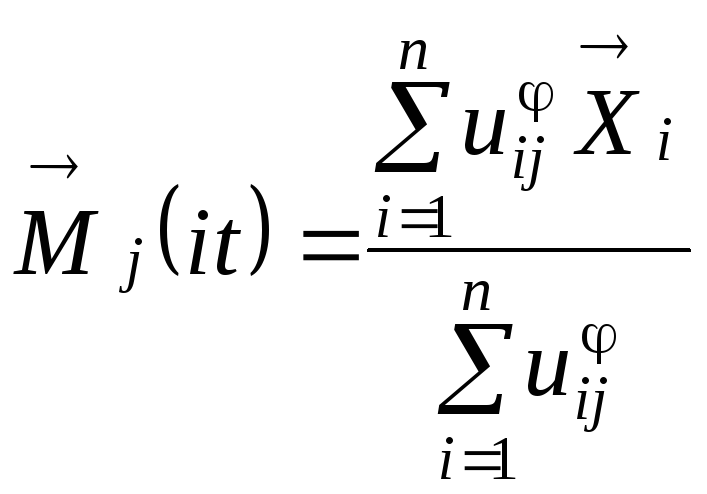 для
всех
для
всех
![]() .
.
Для
вычисления центров классов используется
функция принадлежности
![]() ,
вычисленная на шаге 5.
,
вычисленная на шаге 5.
-
Вычислим расстояние между положением центра класса на данной и предыдущей итерации для всех центров, т.е. величины
 для всех
для всех
 .
. -
Если
 ,
то вычисления закончены с выводом
дополнительного сообщения о невозможности
достигнуть заданной точности
,
то вычисления закончены с выводом
дополнительного сообщения о невозможности
достигнуть заданной точности
 при данном
при данном
 .
. -
Если

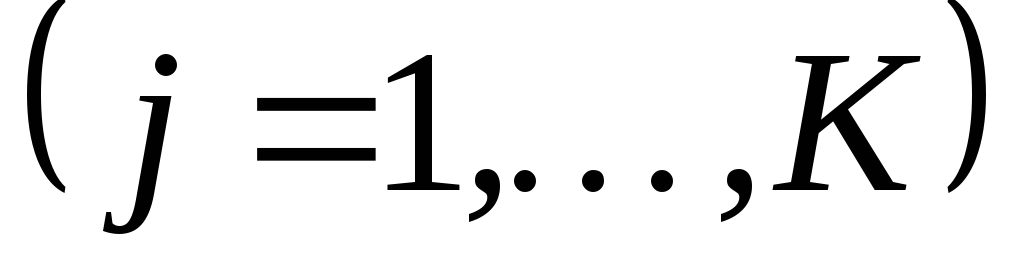 ,
то вычисления закончены, иначе перейти
к шагу 5.
,
то вычисления закончены, иначе перейти
к шагу 5.
Результатом
выполнения алгоритма является функция
принадлежности - матрица
![]() ,
которая содержит данные о степени
принадлежности
,
которая содержит данные о степени
принадлежности
![]() -го
объекта к
-го
объекта к
![]() -му
классу. Пусть, например, для пяти объектов
-му
классу. Пусть, например, для пяти объектов
![]() и трех классов
и трех классов
![]() эта матрица имеет вид:
эта матрица имеет вид:
-
j
i
1
2
3
1
0,78
0,15
0,07
2
0,92
0,08
0,00
3
0,15
0,05
0,8
4
0,00
0,05
0,95
5
0,09
0,87
0,04
Естественно
считать, что объект
![]() принадлежит к тому классу
принадлежит к тому классу
![]() для которого функция принадлежности
имеет максимальное значение. Таким
образом, для данного случая первый
объект принадлежит к первому классу
для которого функция принадлежности
имеет максимальное значение. Таким
образом, для данного случая первый
объект принадлежит к первому классу
![]() ;
второй объект принадлежит к первому
классу; третий объект принадлежит
третьему классу и т.д.
;
второй объект принадлежит к первому
классу; третий объект принадлежит
третьему классу и т.д.