

Глава II. Аналитический обзор средств разработки учебного корпуса
2.1. Аналитический обзор программных средств для аннотирования текста
Как уже говорилось выше, учебный корпус – электронное собрание учебных данных иностранного или второго языка, которые составляют новый ресурс для овладения вторым языком, а также для преподавания языков. Практически все учебные корпуса являются лингвистически размеченными.
Лингвистическая разметка подразумевает присвоение словам особых кодов. Каждому коду соответствует определенный набор грамматических признаков, характеризующих данное слово. Коды также известны как тэги (от англ. tag – ярлык, метка), а сам процесс приписывания словам тэгов соответственно имеет название тэггинг (от англ. tagging).
В настоящее время не существует общепризнанных стандартов представления лингвистической и других видов информации в текстах. Специальный международный проект Text Encoding Initiative (TEI) предназначен для того, чтобы разработать стандартизированные средства разметки. Для этого применяется уже общепризнанный международный язык разметки документов SGML или его подмножество XML. Типы разметки, которые может содержать корпус, можно условно подразделить на лингвистические и внешне лингвистические. К последним относятся:
-
разметка, отражающая особенности форматирования текста (заголовки, абзацы, отступы и т.д.);
-
разметка, касающаяся сведений об авторе и тексте. Причем сведения об авторе могут включать не только его имя, но также и возраст, пол, годы жизни и многое другое, а сведения о тексте обычно содержат, кроме названия, еще и язык, на котором он написан, год и место издания и т.д.
Наличие подобной информации позволяет значительно детализировать поиск в текстовых базах данных и, кроме того, предоставляет средства идентификации соответствующего документа.
К первичной разметке текстов относятся этапы, обязательные для каждого корпуса:
-
токенизация (разбиение на орфографические слова);
-
лемматизация (приведение словоформ к словарной форме).
Следующим важным этапом является морфологический анализ. В иностранных источниках употребляется термин part-of-speech tagging, дословно – частеречная разметка, в действительности она включает не только признак части речи, но и признаки грамматических категорий, свойственных данной части речи. Это основной тип разметки в текстах, он рассматривается как основа для дальнейших этапов анализа – синтаксического и семантического. Схема морфологической разметки предполагает наличие, во-первых, набора тэгов, во-вторых, описания того, что каждый из них означает и, в-третьих, правил присвоения тэгов единицам текста. Размер наборов тэгов, применяемых в разных корпусах варьируется. Несомненно, чем больше набор тэгов, тем более детальный анализ текста осуществим с его помощью. Однако по мере увеличения объема корпусов наметилась тенденция к сокращению числа морфологических помет. Упрощенная система кодировки способствует избежанию лишних ошибок, непоследовательности, уходу от морфологической неоднозначности и, в конечном итоге, быстроте разметки больших массивов текста, содержащих миллионы слов.
Среди лингвистических типов разметки кроме морфологического типа также выделяются:
Синтаксическая. Является результатом синтаксического анализа или парсинга (от англ. parsing). Чаще всего в его основе лежит грамматика структур непосредственно составляющих. Графически синтагматические отношения между членами предложения изображаются, как известно, в виде дерева, а в тексте они представлены пaрами из открывающейся и закрывающейся квадратных скобок, которые обрамляют различные синтаксические конструкции – именные, глагольные и предложные словосочетания, придаточные предложения. Рядом как с открывающейся, так и с закрывающейся скобкой ставятся метки (коды), описывающие заключенную в них конструкцию. Одни пары скобок вложены в другие, элементом высшего уровня является предложение, обозначаемое символом S. Тексты, получившие синтаксическую разметку, известны как treebanks. На синтаксическом уровне, как и на морфологическом, проявляется тенденция к меньшей детализации схем грамматической разметки в целях увеличения скорости и последовательности анализа текста. Метод, который возник в результате этой тенденции, получил название skeleton parsing;
Семантическая. Хотя для семантической, как и для других видов разметки, нет стандартной формы, чаще всего для ее представления используют код, состоящий из букв и цифр или только цифр, в котором первая буква или цифра обозначает общую семантическую категорию, в которую входит данное слово, а последующие символы – более узкие подкатегории, специализирующие его значение. В схемах семантической разметки предусмотрены те случаи, когда в качестве единицы смысла выступает не отдельное слово, а словосочетание. Все члены такого словосочетания получают один и тот же код, при этом для каждого из них дополнительно указываются его порядковый номер, а также общее число слов в идиоматическом выражении;
Анафорическая. Из всех видов референции наибольшую сложность для автоматической обработки текста представляет местоименная. Так, большинство систем машинного перевода обрабатывает текст по отдельным предложениям, отчего страдает связность выходного текста. Таким образом, эффективность таких систем гораздо повысилась бы, если бы правильно определялась референция местоимений-заместителей. В частности, этому и призвана способствовать анафорическая разметка. Как правило, антецедент, в роли которого обычно выступает именное словосочетание, берется в пронумерованные скобки, а рядом с местоимением-заместителем ставится особый знак, отсылающий к антецеденту с соответствующим номером;
Просодическая. В корпусах затранскрибированной звучащей речи применяются метки, описывающие ударение и интонацию. Просодической часто сопутствует так называемая дискурсная разметка, которая служит для обозначения пауз хезитации, повторов, оговорок и т. д.
Аннотирование корпусов осуществляется программными средствами. Во-первых, это экономичнее с точки зрения временных и трудозатрат, чем если бы разметка проводилась вручную. Во-вторых, что более важно, это связано с поиском решений в области автоматической обработки текста.
К числу известных и наиболее часто используемых программ при аннотировании корпусов относятся такие программы как AntConc, WordSmith, MonoConc Pro, MonoConc Easy и CATMA описание которых, представлено ниже.
AntConc (http://www.antlab.sci.waseda.ac.jp/software.html) является бесплатной, мультиплатформенной программой для проведения корпусных лингвистических исследований и управления данными. Она работает на любом компьютере под управлением Microsoft Windows (проверено на Win 98/Me/2000/NT, XP, Vista, Win 7), Linux. Она была разработана в Перле с использованием ActiveState's PerlApp компилятора для создания исполняемых файлов для различных операционных систем.
AntConc содержит семь инструментов, к которым можно получить доступ, нажав на клавишу табуляции в меню инструментов, или используя функциональные клавиши F1-F7.
Конкорданс. Данный инструмент показывает результаты исследования формата KWIC (ключевое слово в контексте). Он позволяет увидеть, как слова и фразы обычно используются в разных контекстах.
График конкорданса. В этом инструменте все адреса для каждого элемента поиска представлены в виде “штрих-кода”, указывающего на место в файле, где находится элемент. График позволяет увидеть, какие файлы включают искомый элемент. Он также может быть использован для определения, где сталкиваются искомый элемент и кластер.
Просмотр файлов. В любое время целевой файл можно посмотреть в оригинальной форме, используя меню «просмотр файлов». Это позволяет более подробно исследовать результаты, полученные в других инструментах AntConc.
Кластеры. Инструмент кластеры используется для создания упорядоченного списка кластеров, которые появляются вокруг поиска в целевом файле, перечисленные в левой части главного окна.
Расположение. Инструмент «расположение» показывает расположение элемента поиска. Это позволяет исследовать непоследовательные модели в языке.
Список слов. Данный инструмент подсчитывает все слова в корпусе и представляет их в упорядоченном списке. Это позволяет быстро найти, какие слова употребляются наиболее часто в корпусе.
Список ключевых слов. В дополнение к созданию списка слов, с помощью AntConc можно сравнить слова в целевом файле со словами, которые появляются в «базисном корпусе», чтобы создать список "Ключевых слов", которые являются наиболее частыми (или редкими) в целевых файлах. Окно продукта представлено на рисунке 4.
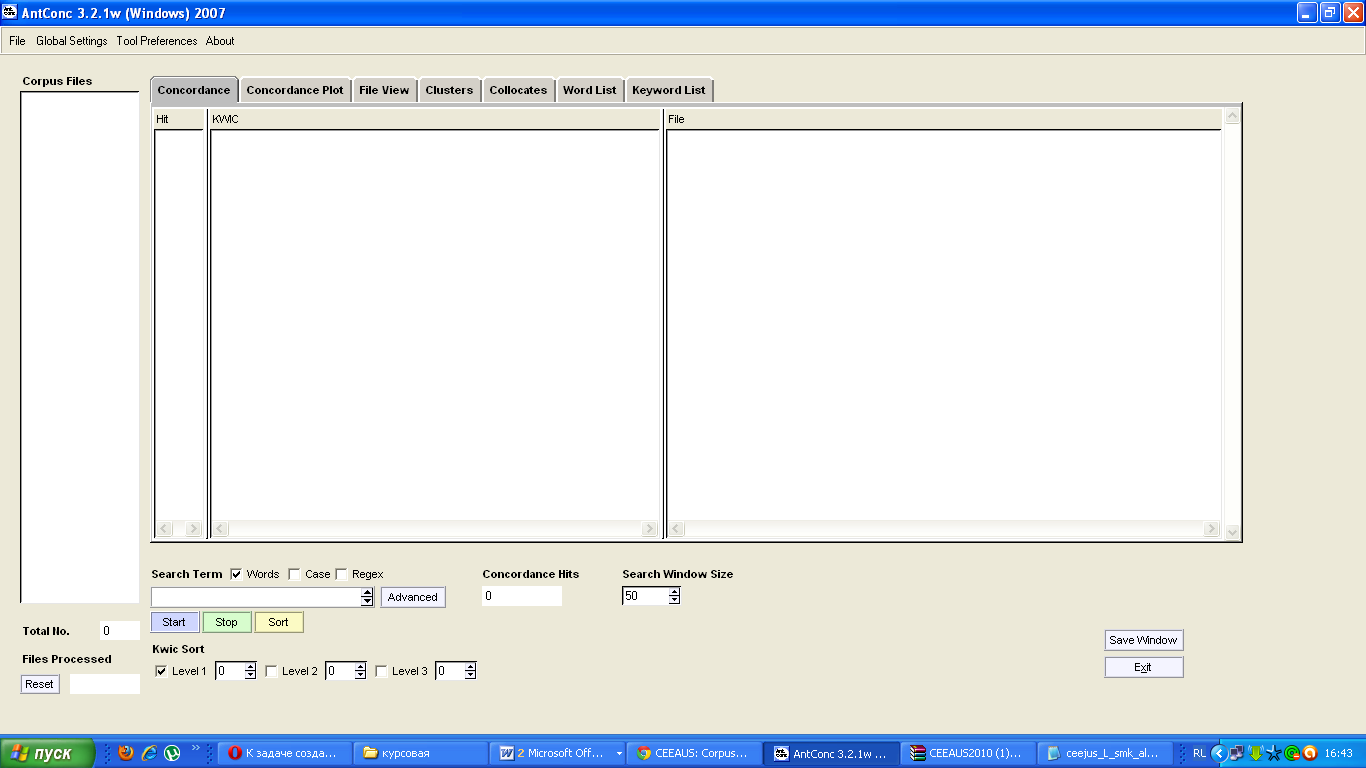
Рисунок 2 Окно программы AntConc
WordSmith Tools (http://www.lexically.net/wordsmith/index.html) программа управления инструментами. Она показывает и изменяет текущие значения по умолчанию, управляет выбором текстовых файлов, а также вызывает различные инструменты. Программа состоит из трех инструментов: Concord, KeyWords, WordList.
Concord это программа, которая создает конкорданс, используя DOS, Text Only, ASCII или ANSI текстовые файлы.
Для ее использования необходимо задать поиск слова, которое Concord будет искать во всех текстовых файлах, которые вы выбрали. Затем она представит конкорданс, и вы получите доступ к информации о расположение искомого слова, график расположения, показывающий, где искомое слово находится в каждом файле. Кластер исследует данные повторяющихся кластеров слов (фраз) и т.д.
Конкорданс дает возможность просмотреть множество примеров слов или фраз в контексте. Вы получаете гораздо лучшее представление об использовании слова, видя множество примеров, а также, увидев или услышав новые слова в контексте много раз, вы приходите к пониманию их значений. Словарь дает лишь значение слова, но не показывает, как и когда его можно или нужно использовать. Студенты, изучающие язык могут использовать конкорданс, чтобы узнать, как использовать слова или фразы, или какие другие слова должны употребляться с этим словом.
KeyWords
Это программа для идентификации "ключевых" слов в одном или нескольких текстах. Ключевыми словами являются такие слова, частота которых необычайно высока по сравнению с некоторой нормой.
Ключевые слова предоставляют полезный способ охарактеризовать текст или жанр. Потенциальные области применения включают в себя: обучение языку, судебную лингвистику, стилистику, контент-анализ, поиск текста.
Программа сравнивает два уже существующие списка слов, которые должны были быть созданы с помощью WordList Tool. Один из них должен быть большим списком слов, который будет выступать в качестве справочного файла. Другой список слов должен быть основан на тексте, который вы хотите исследовать.
Целью является выяснить, какие слова характеризуют интересующий вас текст, т.е. меньший из двух выбранных текстов.
Ключевые слова и связи между ними могут быть выстроены в базу данных и сгруппированы в соответствии с их ассоциациями.
WordList
Данная программа создает списки слов на основе одного или более ASCII или ANSI текстовых файлов. Слова автоматически строятся и в алфавитном порядке и по частоте, и, при необходимости вы можете создать список слов по индексу.
Она может быть использована:
-
просто для изучения использованной лексики;
-
определения лексических групп;
-
сравнения частоты слов в различных текстовых файлах или по жанрам;
-
сравнения частоты родственных слов или перевод соответствий между различными языками;
-
создания конкорданса одного или нескольких текстов из вашего списка.
В рамках WordList можно сравнить два списка или провести последовательный анализ (поверхностный или детальный) в целях стилистического сравнения.
Эти списки слов могут быть также использованы в качестве входных данных программе KeyWords, которая анализирует слова в данном тексте и сравнивает частоты со справочным корпусом, для того, чтобы создать список "ключевых слов".
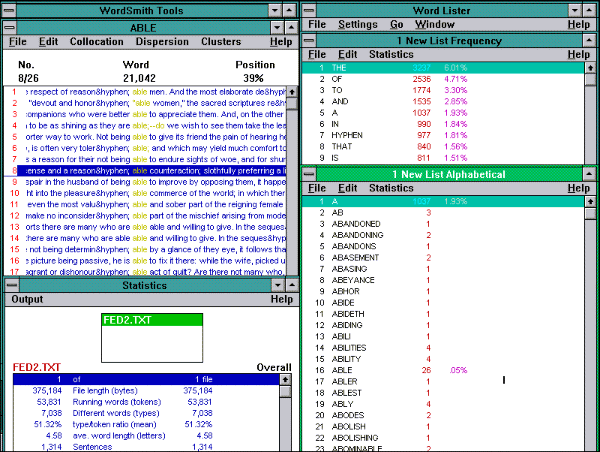
Рисунок 3 Окно программы WordSmith
MonoConc Pro (http://www.athel.com/mono.html) быстрая программа конкорданс (текстовый поиск) с отличным пользовательским интерфейсом. Он используется для анализа английских или других текстов - испанских, французских, японских, китайских и т.д. - для лингвистического или языкового преподавания и изучения языков (ESL). Наряду с предоставлением KWIC результатов конкордансом, программное обеспечение производит также информацию о списках слов и словосочетаний. Программа проста в использовании, хотя и поставляется с целым рядом мощных функций, таких как контекстный поиск, поиск по регулярному выражению, частеречный поиск по тегам, сочетаемости слов и корпус сравнения.
Программное обеспечение используется в составе многих корпусных лингвистических курсов и также широко используется в ESL / EFL для пополнения словарного запаса и изучения языка в целом. Программа MonoConc Pro разработана для работы в компьютерных сетях и работает под управлением Windows в различных средах (W95 и выше).
Является коммерческой программой.

Рисунок 4. Окно программы MonoConc Pro
MonoConc Easy имеет много особенностей MonoConc Pro, но такие дополнительные функции, как расширенная сортировка и корпусное сравнение в него не включены. Это программное обеспечение очень полезно для создания конкорданса и для использования в компьютерных лабораториях. Программа предназначена для использования студентами и для обучения, а не для корпусных исследований.
CATMA (Computer Aided Textual Markup and Analysis) (http://www.catma.de/download) является практическим и интуитивно понятным инструментом для литературоведов, студентов и других сторон, имеющих интерес к анализу текстов и литературным исследованиям. Версия CATMA 3.2 JAVA основана для Mac и Windows PC и доступна на сайте для скачивания.
Основанная на известной программе «Usebase», данная программа предоставляет разметку и функциональный анализ, содержащихся в двух ее составляющих: Tagger и Analyzer.
CATMA делает сильный акцент на удобство использования. Она предназначена для пользователей с небольшим опытом работы с цифровым анализом текста.
В отличие от структурной разметки, которая в большинстве случаев может быть выражена более или менее фиксированным набором тегов, разметка, которая интерпретирует смысл текстовых элементов - так называемых "герменевтической разметкой" - должна быть гибкой и расширяемой, но в то же время отвечать требованиям стандартов с тем чтобы дать возможность взаимодействию инструментов.
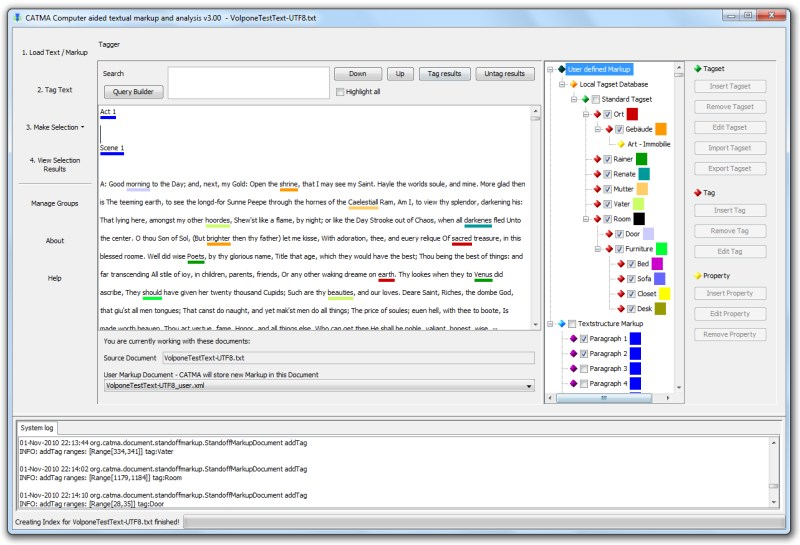
Рисунок 5. Окно программы CATMA
Изучив все эти продукты, можно сделать вывод, что наиболее удобным и простым в использовании является программное средство AntConc. Благодаря таким инструментам как конкорданс, график конкорданса, кластеров, инструмента просмотра файлов, спискам ключевых слов и некоторым другим инструментам, программа дает возможность проведения подробных корпусных лингвистических исследований. Ко всему прочему программа является бесплатной.