

Учебники / Computer-Aided Otorhinolaryngology-Head and Neck Surgery Citardi 2002
.pdfVirtual Reality and Surgical Simulation |
103 |
searchers are encountering in this field [4]. Future VR systems must target both the visual and physical sensory modalities before this technology will allow users to take full advantage of their innate sensory and motor skills.
In theory, a force feedback system should allow the user to perform natural gestures and interactions within the simulated space while the VR system creates feedback forces that feel realistic and convincing [3]. Tactile simulation and force feedback simulation are not equivalent. Tactile simulation replicates the texture of an object for the skin’s touch receptors. In a tactile simulation, sandpaper should feel rough and porcelain should feel smooth. Proprioception, the sensory component of force feedback, shares some features of tactile senses, but it is different. Tactile simulation allows someone to feel the smoothness of a porcelain figurine, while force feedback puts the figurine in the user’s hand (from a perceptual viewpoint). If a user grasps a figurine in a VR simulator that uses force reflective system (a type of force feedback), the VR computer measures the closure of the user’s hand and limits the closure at the calculated boundary of the figurine. The net result is that the VR figurine appears solid.
Rosenberg describes the force feedback human interface system as a closed loop. The cycle begins when a user makes a gesture within the virtual environment. Sensors that are attached to the input devices track the user’s physical motions and relay this information to the host computer. The computer then calculates the haptic sensations that the user should feel as a result of the physical motion as well as the defined contents and structure of the simulated environment. The computer signals a set of actuators that then produces haptic sensations. Actuators produce real physical forces, which make their way to the user’s body through a mechanical transmission. When the user perceives these synthesized forces and reacts to them, the cycle is complete.
7.4EXPERT SYSTEMS AND VIRTUAL ENVIRONMENTS
The incorporation of an expert system multimodal input into a VR system provides an intelligent simulation tool for medical training by increasing the functionality of the simulator to another level. The expert system uses a multilayered approach to recognize the student’s voice (i.e., ‘‘Where is the frontal recess?’’) and gestural commands (i.e., injecting the uncinate) and events in the virtual environment (i.e., navigation through the nasal cavity). The expert system then infers context from these cues and matches this context against steps in the surgical procedure. Students can query the system for both task and procedural level assistance and receives automatic feedback when they perform the surgical procedure incorrectly. The interface adds an interpretation module for integrating speech and gesture into a common semantic representation, and a rule-based expert system uses this representation to interpret the user’s actions by matching
104 |
Edmond |
them against components of a defined surgical procedure. While speech and gesture have been used before in virtual environments, Billinghurst and Edmond were the first to couple it with an expert system, which infers context and higherlevel understanding [5].
7.4.1 Multimodal Input
Employing multimodal input within medical interfaces is an ideal application for the surgical setting, since the surgeon’s hands are engaged and the surgeon relies heavily upon on vocal and gestural commands. Voice and gesture compliment each other and, when used together, create an interface more powerful than either modality alone. Cohen showed how natural language interaction is suited for descriptive techniques, while gestural interaction is ideal for direct manipulation of objects [6,7].
Users prefer using combined voice and gestural communication over either modality alone when attempting graphics manipulation. Hauptman and McAvinny used a simulated speech and gesture recognizer in an experiment to judge the range of vocabulary and gestures that were unused in a typical graphics task [8]. In this protocol, the modes of gesture only, voice only, and gesture recognition were tested. Users overwhelmingly preferred combined voice and gestural recognition due to the greater expressiveness possible.
Combining speech and gesture context understanding improves recognition accuracy. By integrating speech and gesture recognition, Bolt discovered that neither had to be perfect if together they converged on the user’s intended meaning [9]. In this case, the computer responded to user’s commands by using speech and gesture recognition in the concurrent context.
7.4.2 Expert System
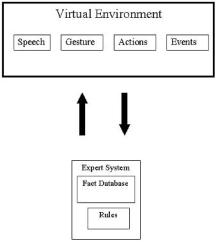
An expert system is necessary to effectively integrate voice and gestural input into a single semantic form. This unified representation can then be matched against procedural knowledge contained in the expert system to make inferences about user actions. In this way, the system can recognize when the user performs specific actions, and then the system can provide automatic intelligent feedback (Figure 7.1).
In our interface, we use a rule-based system, which encodes expert knowledge in a set of if-then production rules [6]. For example, if FACT-I, then DOTHIS, where FACT-I is the event necessary for rule activation and DO-THIS is the consequence of rule activation. The user’s speech and actions in the virtual environment generate a series of facts, which are passed to the expert system fact database and matched against the appropriate rules. This then generates intelligent response. Rule-based expert systems have been successfully applied to a wide variety of domains, such as medical diagnosis [10], configuration of computer systems [11], and oil exploration [8].
Virtual Reality and Surgical Simulation |
105 |
FIGURE 7.1 Demonstration of the user’s speech and actions in the virtual environment generates a series of facts that are passed to the expert system fact database and matched against the appropriate rules. The process yields an intelligent response.
7.4.3 Natural Language Processing
Natural language processing (NLP) techniques provide a theoretical framework for interpreting and representing multimodal inputs. NLP is traditionally concerned with the comprehension of written and/or spoken language, but these methods may be modified so that NLP can understand multimodal inputs and create inferences about user actions from these inputs. In effect, NLP methods determine the representation scheme that is used in our expert system, while the expert system determines how these representations are manipulated in an intelligent way. Previous multimodal interfaces show how voice and gesture can be integrated into a common semantic form [8], but our work extends beyond this by using low-level semantic knowledge as the basis for higher-level pragmatic understanding. To do this we draw on established NLP techniques, such as conceptual dependency representations and scripts.
7.4.4 Simulation and Training
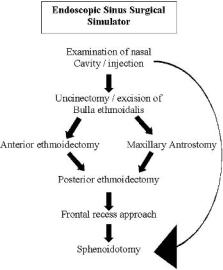
By extending this rule-based approach and adding procedural knowledge, the same expert system can be used as a sinus surgery trainer. The sinus interface supports training of a standard anterior-to-posterior approach to the paranasal sinuses. In constructing the expert system database, the complete surgical procedure was broken down into a number of self-contained steps, each of which was
106 |
Edmond |
FIGURE 7.2 Example of sequence of surgical steps (procedural knowledge) encoded into a rule-based expert system.
also comprised of several tasks. In this example, some of these steps need to be performed in a specific sequence, while other steps are not sequence-dependent. For example, in order to perform maxillary antrostomy an uncinectomy must first be performed (i.e., in a specific sequence), while the frontal recess can be addressed at any time after the uncinectomy and anterior ethmoid air cells have been opened. The complete set of surgical steps and the relationships between them are shown in Figure 7.2. To identify which stage the user is attempting in the operation, the expert system combines information from the user’s multimodal input with the state of the virtual world and compares these data to sets of rules designed to recognize context. Each set of rules corresponds to the onset of a different step in the surgical procedure and, when activated, causes the rest of the user interaction to be interpreted from within that surgical context. This contextual knowledge is then used to improve speech and gesture recognition. When the interface is used for training, activation of a particular context causes activation of the set of rules corresponding to the tasks contained in that surgical step. These rules differ from those used to recognize context in that they correspond to actions that need to be performed in definite sequence. In this way the user’s progress can be monitored through the operation in a step-by-step fashion as well as at a task-by-task level.
Response to incorrect actions depends on the training level chosen at the
Virtual Reality and Surgical Simulation |
107 |
program outset. At the very least, the system prevents the user from performing a task-level action out of sequence and gives auditory warning when they try to do so. While the system cannot constrain instrument movement, it can prevent tissue dissection and removal in virtual world simulation; this block effectively stops the user from progressing further.
Since the entire surgical procedure is encoded in the expert system database, the interface can also respond to requests for help during training. If users become confused, they can ask ‘‘What do I do now?’’ and the system will respond by vocalizing the next task or step in the operation. Alternatively, if the users say, ‘‘Show me what to do now,’’ the rules for the next task are used to send commands to the virtual environment so that the instrument moves in the correct manner. At the same time the system describes what it is doing so the user receives visual and auditory reinforcement.
7.5 ENDOSCOPIC SINUS SURGICAL SIMULATOR
Madigan Army Medical Center, in collaboration with Lockheed Martin Tactile Defense Systems (Akron, OH), Ohio State Supercomputer Center, Ohio State School of Medicine, University of Washington School of Medicine–Human Interface Technology Lab, Immersion Corporation and Uniformed Services University of the Health Sciences, has been working on the development of a prototype nonimmersive simulator for training in endoscopic sinus surgery (ESS) (Figure 7.3). Endoscopic sinus surgery is an important, yet approachable procedure for simulation. ESS simulation has more limited tissue interaction requirements than most other surgical procedures. The anatomy of the sinus region is primarily rigid to a good approximation. Dissection is localized in space and time, making the computational requirements more manageable. ESS simulation is therefore less dependent upon the immature technology of the modeling of dissectible and deformable objects. Moreover, the training requirements of learning the intranasal anatomy and spatial awareness are more important than the psychomotor tasks of tissue removal and are consequently less reliant upon realistic simulation of the tissue interaction.
7.5.1 Virtual Patient
The initial patient model for this project was the visible male from the Visible Human Data (VHD) project conducted by the National Library of Medicine. The image data set consists of cryo-slice images photographed in the transverse plane at 1 mm slice intervals. The photographic data is digitized at a 0.33 pixel size. The data set also included CT and magnetic resonance imaging (MRI) scans. These data are the raw input for the segmentation, surface reconstruction, and visual texture development steps.

108 |
Edmond |
FIGURE 7.3 Madigan Endoscopic Sinus Surgical Simulator.
7.5.2 System Overview
The system has three computer systems linked by an Ethernet interface. An Onyx 2 computer (Silicon Graphics, Mountain View, CA) serves as the simulation host platform. It contains the virtual patient model and is responsible for the simulation of the endoscope image, the surgical interactions, and the user interface. The Onyx is configured with two R10000 CPUs, IR graphics hardware, and a soundboard. The second computer, a 333-MHz Pentium PC (Intel Corporation, Santa Clara, CA), is dedicated to the control of the electro-mechanical hardware. A third computer allows voice recognition and provides virtual instruction while training.
7.5.3 Tracking and Haptic System
The haptic system is comprised of a high-speed Pentium computer and an electromechanical component. It tracks the position and orientation of the endoscope through a mechanical apparatus external to the mannequin’s head and tracks another surgical instrument via a second mechanical apparatus inside the mannequin’s head. The haptic system also monitors the status of the instrument’s scis-

Virtual Reality and Surgical Simulation |
109 |
sors-like grip and of the foot switch. As the user manipulates these physical replicas of an endoscope and a surgical instrument, the connected electromechanical hardware senses their position and orientation in all six degrees of freedom. The haptic system PC reads and transfers the complete state of both tools to the simulation computer. The haptic system applies force in three axes to the distal tip of the surgical tool, simulating haptic cues associated with surgery. The haptic system does not apply force to the endoscope replica (Figure 7.4).
FIGURE 7.4 Physical model with endoscope. The endoscope and forceps are connected to the electromechanical system, which tracks their position and orientation in all six degrees of freedom.
110 |
Edmond |
7.5.4 Image Synthesis
Our goal has been to simulate the endoscopic image as closely as possible. The image fidelity demands of the endoscopic imagery are significant and differ sharply with flight simulation and conventional virtual reality applications. Unlike simulating terrain on a flight simulator, the close proximity of the anatomical structures causes a high percentage of the polygons that represent the sinuses to fall simultaneously within the viewing frustum. This places a heavy load on the simulation computer and graphics hardware. All illumination originates from the endoscope creating an image with a high degree of depth attenuation. Fortunately, shadowing is unnecessary because of the co-linearity between with the imaging optics and the light source. The anatomy is moist and reflective, creating numerous conspicuous specular highlights, which yield important depth cues. We have applied high-quality visual texture to the geometry of the virtual patient, generated from the surface reconstruction of the VHD project.
7.5.5 Surgical Interaction
Since a fully realistic simulation would be a difficult undertaking, we have implemented dissection in a limited way: tissue appears to vanish when dissected. This simplification does not compromise training value significantly.
The simulator also models the complex interaction of specific steps of ESS. The injection of a vaso-constrictor to reduce bleeding is one step in the performance of an anterior ethmoidectomy. During simulation, recursive algorithms search to find vertices inside the virtual needle tip, averaging their original color with blood red to simulate the puncture. In a similar fashion, vertices in the volume surrounding the needle’s tip are averaged with white to simulate the blanching.
The simulator supports 15 different tools and 3 endoscopes (zero, 30, and 70). The instructor interface provides control of the simulation state, instrument selection, and patient selection. The right side of the instructor interface displays a CT image. The simulator tracks the surgical instruments in the patient coordinates and in real time retrieves the coronal CT image of the plane nearest to the tip of the selected surgical tool, marking its position within the image with a graphic cursor.
7.5.6 Curriculum Design
The sinus simulator takes medical simulation several major steps forward in its evolution. Aside from its technical accomplishments, the integration of a well- thought-out curricular framework allows it to take advantage of virtual reality without sacrificing the benefits of more traditional computer-aided instruction.

Virtual Reality and Surgical Simulation |
111 |
Three levels of interaction are available for training:
Model 1 introduces the student into an abstract environment, allowing the student to gain the required hand-eye coordination with the endoscope and the special skills needed to maneuver the instrumented forceps without requiring the student to concentrate on anatomy (Figure 7.5).
Model 2 introduces the student to the anatomy but still utilizes the training aids from Model 1. This model gives the student the help of hoops for the initial passes through the anatomy, targets for injection areas, and labels on the anatomical structures with which interaction is necessary. The educational advantages of simulation can best be achieved with a model of this kind (Figure 7.6).
Model 3 introduces the student to a more realistic environment. There are no longer any training aids to guide the student through the procedure. For navigation of the scope, the student must rely on what was learned when navigating through the hoops in Model 2. For injection, the student must remember where injection of the vasoconstrictor is useful. For dissection, the student has no labels to indicate the anatomy of interest; as a result, the student must rely on what was learned in Model 2 to perform the procedure (Figure 7.7).
FIGURE 7.5 The Madigan Endoscopic Sinus Surgical Simulator includes a variety of skill levels for the support of student surgical education. The display system for the novice stage is shown.

112 |
Edmond |
FIGURE 7.6 The Madigan Endoscopic Sinus Surgical Simulator includes a variety of skill levels for the support of student surgical education. At the intermediate stage, visual cues, including ‘‘hoops’’ and direct labels, are presented. The displayed hoops are targets through which the user must pass the virtual telescope.
FIGURE 7.7 The Madigan Endoscopic Sinus Surgical Simulator includes a variety of skill levels for the support of student surgical education. At the advanced stage, the virtual surgical field has the appearance of the real world nasal cavity. The visual aids that have been incorporated into the less complex levels have been dropped at this level.