

Metodichka_chast_2
.pdfДля нахождения последующих коэффициентов дифференцируем заданное уравнение
y |
2х 2уу ; |
y(4) 2 2( у )2 2yy ; |
|
|||||||||||||||||
y |
(5) |
|
|
|
|
|
|
2yy |
|
|
|
|
2yy |
|
. |
|||||
|
|
4y y |
2y y |
|
6y y |
|
|
|||||||||||||
При х= –1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y ( 1) 2 2 2 |
1 |
0 ; |
y(4) ( 1) 22,5 ; |
y(5) ( 1) 15 . |
||||||||||||||||
2 |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Тогда получаем |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
y 2 |
1 |
(x 1) |
5 |
(x 1)2 |
15 |
(x 1)4 |
|
1 |
(x 1)5 . |
|||||||||||
|
|
|
|
|
||||||||||||||||
|
2 |
|
2 |
|
|
|
16 |
|
|
|
8 |
|
|
|
||||||
9. ЗАДАНИЯ, РЕКОМЕНДУЕМЫЕ ДЛЯ САМОСТОЯТЕЛЬНОГО РЕШЕНИЯ ПО ТЕМЕ «ЧИСЛО-
ВЫЕ И ФУНКЦИОНАЛЬНЫЕ РЯДЫ»
1. Установить расходимость ряда, пользуясь достаточным условием расходимости
|
|
3n |
|
|
|
2n 1 |
|
|
|
n2 1 |
|
||||||||
1) |
|
|
|
; |
|
|
2) |
|
|
; |
3) |
|
|
|
|
|
; |
||
2n |
|
2n 1 |
|
|
|
|
|||||||||||||
|
|
|
2n |
||||||||||||||||
|
n 0 |
|
|
|
|
|
|
n 1 |
|
|
|
|
|
n 1 |
|
|
|
|
|
|
|
n |
n |
|
|
6n2 3n 1 |
|
|
n! |
|
|||||||||
4) |
|
|
|
; |
5) |
|
|
|
|
|
; 6) |
|
|
|
|
. |
|
||
|
|
|
10n |
2 |
10000 |
10 |
n |
|
|||||||||||
|
n 1 |
n 1 |
|
|
n 1 |
|
|
n 1 |
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
2. Пользуясь признаками сравнения, изучить сходимость рядов
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1) |
|
|
|
1 |
|
; |
2) |
|
|
n |
|
; |
|||
|
|
|
|
|
n |
2 |
|||||||||
|
n 1 |
100n 1 |
|
n 1 |
|
1 |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 n4 |
|
|
|
|
|
1 |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
||||||
4) |
|
|
|
|
|
; |
|
5) |
|
|
|
|
|
; |
|
n |
2 |
|
|
|
2 |
n |
3 |
||||||||
|
n 1 |
|
|
|
|
|
n 0 |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
n
3) ; n 1 n n 1
|
|
|
|
|
6) |
|
1 |
|
. |
|
|
|
||
n 1 |
n 4 |
|||
3. С помощью признака Даламбера исследовать на сходимость ря-
ды
|
|
|
2n |
|
|
n2 |
|
|
|
10n3 |
||||||||
1) |
|
|
; |
2) |
|
|
|
; |
|
|
3) |
|
|
|
|
; |
||
|
2 |
n |
|
3 |
n |
|
||||||||||||
|
n 1 |
|
n! |
|
n 1 |
|
|
|
|
|
n 1 |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
2n |
|
|
n! |
|
|
|
52n |
|
|
||||||
4) |
|
|
|
; |
5) |
|
|
|
|
|
; |
6) |
|
|
|
. |
|
|
|
100 |
2n ! |
n! |
|
||||||||||||||
|
n 1 |
n |
|
n 1 |
|
|
n 1 |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
4. С помощью признака Коши исследовать на сходимость ряды
63

|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
n 1 n |
|
|
|
|
|
5n2 |
2 |
n |
|
||||||||||||||||||
1) |
|
|
|
|
|
; |
|
|
|
|
|
2) |
|
|
|
|
|
|
; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
2 |
n |
|
|
|
|
|
|
|
|
|
2n 1 |
|
3) |
|
3n |
2 |
1 |
|
; |
|||||||||||||||||||||||
|
n 1 |
|
|
|
|
|
|
|
|
|
|
n 1 |
|
|
|
n 1 |
|
|
|
|
|||||||||||||||||||||||
|
|
2 |
n |
1 |
|
|
|
|
|
|
n 1 |
n2 |
|
|
|
|
n |
2 |
n2 |
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
4) |
|
|
n |
n |
|
; |
|
|
|
5) |
|
|
|
|
|
; |
|
6) |
|
|
|
|
|
|
|
. |
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
n 1 |
|
|
|
|
|
|
|
|
|
|
n 1 |
|
n |
|
|
|
|
|
|
|
|
|
n 1 3n 1 |
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
5. Исследовать ряды на абсолютную и условную сходимость |
|
|
||||||||||||||||||||||||||||||||||||||||
|
|
|
1 n |
|
|
|
|
|
|
|
|
1 n |
|
|
|
|
|
|
|
|
|
|
1 n |
|
|
|
|
||||||||||||||||
1) |
|
|
|
|
|
|
|
|
|
|
|
; |
|
2) |
|
|
|
|
|
|
|
|
|
|
; |
|
3) |
|
|
|
|
|
|
|
. |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|||||||||||||
|
n 1 |
n n |
1 |
|
|
|
|
n 1 |
|
|
|
n3 2 |
|
|
|
n 1 |
3 |
|
2 |
|
|
|
|
||||||||||||||||||||
|
6. Найти интервал сходимости степенного ряда |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
|
|
x 1 n |
|
|
|
x 3 n |
|
|
|
|
|
|
xn |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
1) |
|
|
; |
|
2) |
|
|
|
|
|
|
|
|
; |
|
3) |
|
|
; |
|
|
|
|
|
|
|
|||||||||||||||||
n 1 ! |
|
|
|
|
2n |
|
|
|
|
n2 |
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
n 0 |
|
|
|
|
|
|
|
|
|
|
|
|
n 0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
n 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7. Разложить в степенной ряд по степеням x функцию |
|
f (x) |
|
|
||||||||||||||||||||||||||||||||||||||
1) |
f (x) e5x ; |
|
2) |
f (x) e2 x 1 ; |
|
3) |
|
f (x) xsin3x ; |
|||||||||||||||||||||||||||||||||||
4) |
f (x) sin x2 ; |
|
5) |
f (x) ln(1 2x) ; |
6) |
|
f (x) |
|
1 |
|
|
. |
|
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x 2 |
|
||||||
|
8. Разложить функции по степеням x x0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
1) |
f (x) ex , |
x 1 ; |
|
|
|
|
|
|
2) |
|
|
f (x) ex , |
|
x 1; |
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3) |
f (x) cos(x), x0 |
2 ; |
|
|
|
|
|
4) |
|
|
f (x) |
1 |
|
, |
x0 |
2 ; |
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
x |
|
|
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
9. Вычислить определенный интеграл с точностью до 0,001 путем предварительного разложения подынтегральной функции в степенной ряд и почленного интегрирования этого ряда
1 |
0,2 |
2 |
e |
x |
1 |
sin( |
x) |
|
||
1) cos(x2 )dx ; |
2) e 3x2 dx ; |
3) |
|
dx ; |
4) |
dx ; |
||||
|
|
|
|
|||||||
0 |
0 |
1 |
x |
0,25 |
|
x |
||||
10. При указанных начальных условиях найти три первых отличных от нуля члена разложения в степенной ряд функции y = f(x), являющейся решением заданного дифференциального уравнения
1) |
y ' x |
1 |
, |
|
y 0 1 ; |
2) |
y ' cos( y) x, |
y 0 0,5 ; |
||
|
|
|||||||||
|
|
y |
|
|
|
|
|
|
|
|
3) |
y" y x |
2 |
, |
4) |
y" xe |
x |
|
|
||
|
|
2yy , |
|
|||||||
|
y 1 1, y 1 0 ; |
|
y 0 0, y 0 1. |
|||||||
64
10.ЭЛЕМЕНТЫ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
10.1.Задачи математической статистики
Математическая статистика – это один из разделов математики. Все основные методы, используемые в математической статистике, основаны на понятиях теории вероятностей.
Каждое исследование случайных явлений, выполненное методами теории вероятностей, опирается на экспериментальные данные.
Математическая статистика занимается разработкой методов сбора, описания и анализа экспериментальных данных, получаемых в результате наблюдения массовых случайных явлений.
В любом процессе, связанном с применением статистических методов, можно выделить три этапа: сбор данных, обработка данных, статистические выводы – прогнозы и решения.
Типичными задачами математической статистики являются:
1)определение закона распределения случайной величины по статистическим данным;
2)проверка правдоподобия гипотез;
3)нахождение неизвестных параметров распределения.
Генеральная совокупность. Выборка
Множество однородных объектов, подлежащих статистическому
изучении, называется статистической совокупностью. Отдельные объекты называются элементами совокупности, а их число – объемом совокупности.
Элементы совокупности можно охарактеризовать одним или несколькими признаками, значения которых изменяются при переходе от одного элемента совокупности к другому.
Для изучения вариации (изменения) признака проводится статистическое наблюдение. Различают два вида статистических наблюде-
ний: сплошное и выборочное.
При сплошном наблюдении изучается каждый элемент совокупности. Однако такое наблюдение сопряжено со значительными затратами труда или же может оказаться вообще неосуществимым.
По этой причине в большинстве случаев используют выборочное наблюдение, в основе которого лежит выделение из статистической совокупности некоторой ее части – выборочной совокупности (выборки). Исходная совокупность в этом случае называется генеральной со-
вокупностью.
Главная задача выборочного метода заключается в том, чтобы по статистическим показателям малой выборки как можно точнее охарактеризовать всю генеральную совокупность. Другими словами, при помощи сравнительно ограниченных средств, которые дают возможность
65
изучать единичные явления, установить характерные свойства и законы для бесконечного числа возможных или встречающихся явлений.
Таким образом, основополагающая задача математической ста-
тистики заключается в исследовании свойств выборки и обобщении этих свойств на всю генеральную совокупность.
Статистический закон распределения.
Пусть для изучения некоторой случайной величины Х из генеральной совокупности извлечена выборка x1, x2 ,...,xn объема n. Предста-
вим значения выборки в виде таблицы, в первой строке которой даны номера элементов выборки, а во второй – сами элементы. Такая табли-
ца называется простым статистическим рядом.
Статистические данные в виде простого статистического ряда при большом объеме выборки довольно трудно обработать. В этом случае производят группировку данных.
При изучении дискретной случайной величины наблюденные значения располагаются в порядке возрастания, а затем подсчитываются частоты mi , т.е. количество появлений одинаковых значений случай-
ной величины, и относительные частоты |
wi |
mi |
, где n – объем вы- |
|||||||||||||
n |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
борки. Результаты записываются в виде таблиц: |
|
|
|
|
||||||||||||
Статистический ряд распределения частот |
|
|
|
|||||||||||||
Наблюденные |
|
x1 |
|
x2 |
|
|
|
... |
|
xk |
||||||
значения xi |
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Абсолютные |
|
m1 |
|
m2 |
|
|
|
... |
|
mk |
||||||
частоты mi |
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Статистический ряд распределения относительных частот |
||||||||||||||||
Наблюденные |
|
x1 |
|
x2 |
|
|
|
... |
|
xk |
||||||
значения xi |
|
|
|
|
|
|
||||||||||
Относительные |
|
m1 |
|
|
m2 |
|
|
|
|
|
|
mk |
|
|||
частоты wi |
mi |
|
|
|
|
|
|
... |
|
|||||||
|
n |
|
n |
|
|
|
|
n |
||||||||
n |
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Если изучается непрерывная случайная величина, то для выполнения группировки нужно весь интервал наблюденных значений случайной величины разбить на k частичных интервалов равной длины. Затем
подсчитать частоты mi и относительные частоты wi |
mi |
попаданий |
|
n |
|||
|
|
наблюденных значений в частичные интервалы. Количество k интервалов выбирается произвольно в пределах от 5 до 15, но рекомендуется определять k по формуле k 1 3,2lgn , где n – объем выборки. Ре-
66
зультаты записываются в виде таблиц:
Интервальный статистический ряд распределения частот
Интервалы наблю- |
|
[x0 |
, x1 ) |
[x1, x2 ) |
... |
|
[xk 1, xk ] |
||||||||
денных значений xi |
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Абсолютные |
|
m1 |
|
m2 |
. . . |
|
|
mk |
|||||||
частоты mi |
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Интервальный статистический ряд распределения |
|
|
|
||||||||||||
|
|
|
относительных частот |
|
|
|
|
|
|||||||
Интервалы наблюден- |
|
[x0 , x1 ) |
[x1, x2 ) |
. . . |
|
[xk 1, xk ] |
|||||||||
ных значений xi |
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Относительные ча- |
|
|
m1 |
|
|
m2 |
|
|
|
|
mk |
|
|||
стоты wi |
mi |
|
|
|
|
. . . |
|
|
|||||||
|
|
|
n |
|
n |
|
|
n |
|||||||
n |
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Перечень наблюденных значений xi случайной величины Х (или интервалов наблюденных значений) и соответствующих им относи-
тельных частот |
|
wi |
mi |
называется статистическим законом рас- |
|||||||||||
|
n |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
пределения случайной величины Х. |
|
|
|
|
|
|
|||||||||
Пример 1. Дан простой статистический ряд |
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
№ пп |
1 |
|
2 |
|
|
3 |
|
4 |
5 |
6 |
|
7 |
8 |
9 |
10 |
xi |
5 |
|
7 |
|
|
5 |
|
2 |
7 |
7 |
|
7 |
5 |
7 |
7 |
Построить статистический ряд распределения относительных частот.
Решение. Выполним группировку и получим статистический ряд распределения частот.
xi |
2 |
5 |
7 |
mi |
1 |
3 |
6 |
Найдем относительные частоты и результаты запишем в виде статистического ряда распределения относительных частот:
xi |
|
|
2 |
5 |
7 |
|
wi |
mi |
|
0,1 |
0,3 |
0,6 |
|
n |
||||||
|
|
|
|
|||
10.2. Эмпирическая функция распределения
67
Эмпирической функцией распределения случайной величины Х называется функция F * (x) , определяющая для каждого значения х
относительную частоту события X x : |
F * (x) |
nx |
, где n |
x |
– число |
|
|||||
|
|
n |
|
||
|
|
|
|
||
значений xi , меньших, чем х, а n – объем выборки.
Эмпирическая функция распределения обладает всеми свойствами
интегральной функции распределения:
1)значения эмпирической функции принадлежат отрезку [0; 1] ;
2) функция F * (x) – неубывающая;
3)если x1 – наименьшее значение в выборке, а xk – наиболь-
шее, то F* (x) 0 при x x1 и F * (x) 1 при x xk . Пример 1. Построить эмпирическую функцию распределения по
статистическому распределению случайной величины Х:
xi |
|
|
|
|
2 |
|
|
|
3 |
5 |
wi |
mi |
|
|
|
0,75 |
|
|
|
0,20 |
0,05 |
n |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
||
Решение. |
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
0, |
если |
x 2, |
|
|
|
|
|
|
|
|
|
|
если |
2 x 3, |
|
|
|
|
|
* |
(x) |
0,75, |
|
|
||
|
|
|
F |
|
|
|
|
3 x 5, |
|
|
|
|
|
|
|
|
0,95, |
|
если |
|
|
|
|
|
|
|
|
|
|
если |
x 5. |
|
|
|
|
|
|
|
1, |
|
|
||
Графическое изображение статистических рядов
Сгруппированные статистические ряды для наглядности можно представлять графиками и диаграммами. Наиболее распространен-
ными графиками являются полигон, гистограмма и кумулята.
Полигон и кумулята применяются как для дискретных, так и для интервальных статистических рядов. Гистограмма применяется для изображения только интервальных рядов.
Для построения гистограммы относительных частот на оси абсцисс откладывают частичные интервалы наблюденных значений случайной величины Х, на каждом из которых строится прямоугольник. Высота прямоугольника равна wi – относительной частоте для
i-го интервала.
Если на гистограмме относительных частот соединить середины верхних сторон элементарных прямоугольников, то полученная замкнутая ломаная линия образует полигон относительных частот.
68
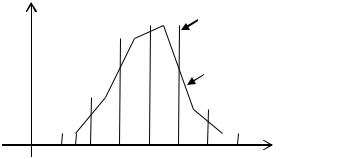
Для построения кумуляты на оси абсцисс откладываются наблюденные значения случайной величины Х, а на оси ординат – накопленные относительные частоты. Значения накопленных относительных частот являются значениями эмпирической функции распределения
F * (x) .
Пример 2. Дано распределение 100 рабочих по затратам времени на обработку одной детали (мин.):
Частичные |
22-24 |
24-26 |
26-28 |
28-30 |
30-32 |
32-34 |
|
интервалы |
|||||||
|
|
|
|
|
|
||
Частоты mi |
2 |
12 |
34 |
40 |
10 |
2 |
Построить гистограмму, полигон и кумуляту относительных частот по данному распределению.
Решение. Вначале вычислим относительные частоты и запишем статистическое распределение в виде таблицы:
Частичные |
|
|
|
|
|
22-24 |
|
|
|
24-26 |
26-28 |
28-30 |
30-32 |
32-34 |
|||||||||
интервалы |
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Частоты |
mi |
|
|
|
|
2 |
|
|
|
12 |
|
|
34 |
|
40 |
10 |
2 |
||||||
Относительные |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
частоты wi |
|
|
mi |
|
|
|
|
0,02 |
|
|
|
0,12 |
0,34 |
|
0,40 |
0,10 |
0,02 |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
100 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Построим гистограмму и полигон относительных частот: |
|
|
|||||||||||||||||||||
Wi |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Гистограмма относительных |
|
|
||||||
0,40 - |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
частот |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0,34 - |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Полигон относительных частот |
|||||||
0,12 - |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,10 - |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,02 - |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
• |
|
|
• |
• |
• |
• |
• |
• |
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|||||||||||||||||
|
22 |
|
|
24 |
26 |
28 |
30 |
32 |
34 |
x |
|
|
|
||||||||||
Найдем эмпирическую функцию распределения и построим кумуляту:
69
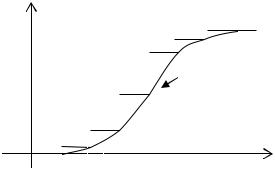
|
|
|
0, |
|
если |
x 22, |
|
|
|
||
|
|
|
0,02, |
если |
22 x 24, |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,14, |
если |
24 x 26, |
|
|
||||
|
|
F * (x) |
0,48, |
если |
26 x 28, |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,88, |
если |
28 x 30, |
|
|
||||
|
|
|
|
|
|
|
30 x 32, |
|
|
||
|
|
|
0,98, |
если |
|
|
|||||
|
|
|
|
|
|
|
x 32. |
|
|
|
|
|
|
|
1, |
|
если |
|
|
|
|||
F*(x) |
|
|
|
|
|
|
|
|
|
|
|
1 |
- |
|
|
|
|
|
|
|
|
• |
|
0,98 |
- |
|
|
|
|
|
|
|
• |
|
|
|
|
|
|
|
|
|
|
|
|||
0,88 - |
|
|
|
|
|
|
• |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Кумулята |
|
|
|
0,48 |
- |
|
|
|
|
|
• |
|
|
|
|
0,14 |
- |
|
|
|
• |
|
|
|
|
|
|
0,02 |
- |
|
|
|
|
|
|
|
|
|
|
• |
|
• |
• |
|
• |
• |
• |
• |
|
||
|
|
|
• |
|
|
||||||
|
|
22 |
24 |
26 |
28 |
30 |
32 |
34 |
x |
||
ч
10.3. Статистические оценки параметров распределения
Статистические распределения содержат полную информацию о вариации признака. Между тем при решении многих задач эта информация может оказаться избыточной.
Для описания статистических распределений обычно используют три вида характеристик (показателей):
1)средние;
2)характеристики изменчивости (рассеяние);
3)характеристики, отражающие дополнительные особенности распределений (в частности их форму).
Все эти характеристики вычисляются по результатам наблюдений и построенных в результате их первичной обработки распределений и называются статистическими. Расчет статистических характеристик является вторым после группировки этапом обработки данных.
Пусть x1, x2 ,...,xn – выборка из генеральной совокупности.
Средним значением выборки или выборочным средним называет-
ся число
70

xв 1 n xi .
n i 1
Эта формула применяется к статистическому ряду, данные которого не сгруппированы. Если же данные сгруппированы, то выборочная средняя (взвешенная средняя арифметическая) вычисляется по фор-
мулам
x |
|
1 |
k |
x m или |
|
|
k |
x w . |
|
|
x |
|
|||||||
n |
|||||||||
в |
|
i i |
в |
i i |
|||||
|
|
|
|
||||||
|
|
|
i 1 |
|
|
|
i 1 |
|
|
где k – число групп, |
mi |
– частоты, wi |
– относительные частоты. Ча- |
||||||
стоты и относительные частоты в этих формулах называются весами. Пример 1. В сельхозпредприятии собран урожай пшеницы с трех
различных участков. С первого участка площадью в 240 га получено по 30 ц/га, со второго на площади 260 га – по 28 ц/га и с третьего площадью 500 га – по 34 ц/га. Определить среднюю урожайность.
Решение. Запишем данные урожая пшеницы в виде таблицы:
Урожайность, ц/га (xi ) |
|
|
28 |
|
30 |
34 |
|
Площадь, га (mi ) |
|
|
260 |
|
240 |
500 |
|
Так как данные сгруппированы, то |
|
|
|
|
|||
x |
28 260 30 240 34 500 |
31,48 ц/га . |
|
||||
|
|
||||||
в |
1000 |
|
|
|
|
||
|
|
|
|
|
|
||
Чем теснее отдельные значения признака группируются вокруг средней, т.е. чем меньше они рассеяны, тем лучше выборочная средняя характеризует данное распределение. Поэтому кроме выборочной средней нужно рассматривать вариацию признака относительно средней, т.е. характеристики рассеяния. В практике, как правило, оценка рассеяния является не менее важной, чем выборочная средняя.
Наиболее грубая оценка рассеяния легко определяется по данным статистического ряда и называется размахом выборки:
R xmax xmin .
Однако этот показатель может сильно меняться при добавлении или исключении крайних значений. Поэтому, если данные не сгруппированы, то в качестве меры рассеяния используется выборочная дисперсия, определяемая по формуле
n
Dв 1 (xi xв )2 . n i 1
Если же данные сгруппированы, то для определения выборочной дисперсии используются формулы
71
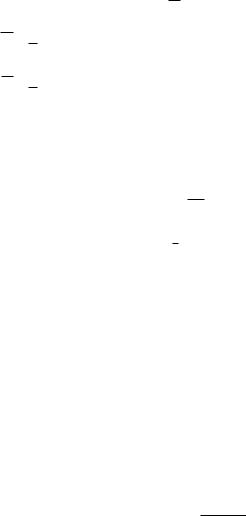
D |
1 |
k |
(x x )2 m |
или D |
k |
(x x )2 w . |
|
n |
|
|
|||||
в |
i в i |
в |
i в i |
||||
|
|
|
|||||
|
|
i 1 |
|
|
i 1 |
|
В практических вычислениях для определения дисперсии удобнее пользоваться формулой
Dв x2 xв 2 ,
n
где x2 1 xi 2 для данных, которые не сгруппированы; n i 1
k
x2 1 xi 2mi для данных, которые сгруппированы.
n i 1
Так как при вычислении дисперсии суммируются квадраты отклонений, то дисперсия измеряется в квадратных единицах. Вследствие этого получается искаженное представление о самой величине отклонений и о величине значений признака. Чтобы согласовать единицы измерения рассеяния и значений признака, вводится среднее квадра-
тическое отклонение
в 
 Dв ,
Dв ,
которое показывает, на сколько в среднем отклоняются значения xi признака от выборочной средней xв .
Коэффициент вариации вычисляется по формуле
V в 100% xв
и применяется для оценки вариации в распределениях с разными значениями средней.
Кроме рассмотренных характеристик в статистическом анализе применяются медиана и мода.
Медиана Me( X ) – это значение признака X, разделяющее ранжированную совокупность на две равные по численности группы. В первой группе содержатся элементы со значениями признака xi Me(X ) , а во второй – со значениями признака xi Me(X ) . Из определения
накопленной относительной частоты следует, что F* (Me(X )) 0,5 . Для определения медианы Me( X ) интервального ряда пользуются
формулой
Me( X ) x0 h n 2 n1 ,
2 mMe
72