

Тема 8. Методы кодирования информации со сжатием.
Лекция 12
12.1 Подстановочные или словарно-ориентированные алгоритмы сжатия информации. Методы Лемпела-Зива.
Алгоритмы кодирования информации, которые приводят к уменьшению длины кода, относительно исходной длины сообщения, называют алгоритмами сжатия информации, а такое кодирование называют кодированием со сжатием.
Мы с вами, на самом деле, уже знакомы с кодами такого рода. Это коды Шеннона –Фано и Хаффмена которые называют оптимальным неравномерными кодами с переменной длиной слова. Если мы кодируем , например текстовое сообщение без учета вероятности появления символов, то на каждый знак мы можем тратить до 8 бит ( если знаки определяются таблицей ASCII). Знание статистики появления знаков позволяет сократить количество битов на знак алфавита в среднем до величины энтропии источника.
Методы кодирования Шеннона-Фэно, Хаффмена обобщающе называют статистическими методами, так как они используют вероятности появления отдельных слов или символов в источнике сообщений для получения эффекта сжатия. Словарные алгоритмы носят более практичный характер. Их преимущество перед статистическими теоретически объясняется тем, что они позволяют экономно кодировать последовательности символов разной длины без знания статистики источника сообщений.
Практически все словарные методы кодирования основаны на алгоритмах описанных в работе двух израильских ученых - Зива и Лемпела, опубликованной в 1977 году. Сущность их состоит в том, что фразы в сжимаемом тексте заменяются указателем (или ссылкой) на то место, где они в этом тексте уже встречались.
Одной из причин популярности алгоритмов LZ является их исключительная простота при высокой эффективности сжатия.
Этот метод быстpо пpиспосабливается к стpуктуpе текста и может кодировать короткими указателями те слова, которые часто появляются в тексте. Новые слова и фразы могут также кодироваться частями ранее встреченных слов путем их замены на их указатели или номера.
Декодирование сжатого текста осуществляется напрямую - происходит простая замена указателя готовой фразой из словаря, на которую тот указывает. На практике LZ-метод добивается хорошего сжатия, его важным свойством является очень быстрая работа декодера. (Когда мы говорим о тексте, то предполагаем, что кодированию подвергается некоторый набор данных с конечным дискретным алфавитом, и это не обязательно текст в буквальном смысле этого слова.)
Все словарные методы кодирования вида LZ можно разбить на две группы.
Первая группа с неявным видом словаря – основа алгоритм LZ77
Методы, принадлежащие к первой группе, находят в кодируемой последовательности цепочки символов, которые ранее уже встречались, и вместо того, чтобы повторять эти цепочки, заменяют их указателями на предыдущие повторения этих цепочек.
Словарь в этой группе алгоритмов в неявном виде содержится в обрабатываемых данных, сохраняются лишь указатели на встречающиеся цепочки повторяющихся символов.
Все алгоритмы из этой группы базируются на алгоритме LZ77. Наиболее совершенным представителем этой группы, включившим в себя все достижения, полученные в данном направлении, является алгоритм LZSS, опубликованный в 1982 году Сторером и Шимански.
Процедура кодирования в соответствии с алгоритмами этой группы иллюстрируется примером 12.1.
Вход А Б В Г Д А Б В Е
1
Выход А Б В Г Д 1 Е
Пример 12.1
произошло сжатие за счет повторяющегося куска текста А Б В.
Алгоритмы второй группы на основе метода LZ78 используют словарь в явном виде
Алгоритмы второй группы в дополнение к исходному словарю источника в ходе сжатия-кодирования создают словарь фраз, представляющих собой повторяющиеся комбинации символов исходного словаря, которые встречаются во входных данных. При этом размер словаря источника возрастает, и для его кодирования потребуется большее число бит, но значительная часть этого словаря будет представлять собой уже не отдельные буквы, а буквосочетания или целые слова. Когда кодер обнаруживает фразу, которая ранее уже встречалась, он заменяет ее индексом этой фразы в словаре. При этом длина кода индекса получается меньше или намного меньше длины кода фразы.
Все методы этой группы базируются на алгоритме, разработанном и опубликованном Лемпелем и Зивом в 1978 году, – LZ78. Наиболее совершенным на данный момент представителем этой группы словарных методов является алгоритм LZW, разработанный в 1984 году Терри Вэлчем.
Идею этой группы алгоритмов можно также пояснить с помощью примера 12.2.
Пример 12.2
Вход А Б В А Б В А Б Г Д Е
Словарь основной А-1, Б-2, В-3, Г-4, Д-5, Е-5, словарь фраз АБ-6, АБВ-7
Выход 12361645 плюс необходимо каким-то образом сохранять и основной словарь.
12.2 LZ-алгоритмы упаковки данных :LZ77
Рассмотрим алгоритм работы кодировщика сжатия по алгоритму LZ77 более подробно.
Основная идея LZ77 состоит в том, что второе и последующие вхождения некоторой строки символов в сообщении заменяются ссылками на ее первое вхождение.
LZ77 использует уже просмотренную часть сообщения как словарь. Чтобы добиться сжатия, он пытается заменить очередной фрагмент сообщения на указатель этого фрагмента в словаре.
LZ77 использует "скользящее" по сообщению окно, разделенное на две неравные части. Первая, большая по размеру, включает уже просмотренную часть сообщения. Это текущий словарь кодировщика, откуда он берет посторяющиеся куски. Вторая, намного меньшая, является буфером, содержащим еще незакодированные символы входного потока. Обычно размер окна словаря составляет несколько килобайт, а размер буфера - не более ста байт. Алгоритм пытается найти в скользящем по тексту словаре фрагмент, совпадающий с содержимым буфера или части буфера.
Алгоритм LZ77 выдает коды, состоящие из трех элементов:
смещение в словаре относительно его начала подстроки, совпадающей с началом содержимого буфера;
длина этой подстроки;
первый символ буфера, следующий за подстрокой.
Пример. 12.3
Закодировать по алгоритму LZ77 строку "КРАСНАЯ КРАСКА".
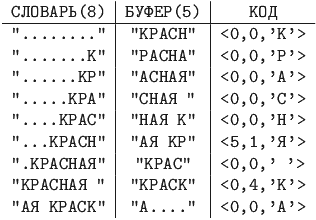
В 9-й строке необходим сдвиг на5 позиций (длина совпадающей строки +1) и считывание стольких же символов в буфер.
В последней строчке, буква "А" берется не из словаря, т.к. она последняя.
Длина кода вычисляется следующим образом: длина подстроки не может быть больше размера буфера, а смещение не может быть больше размера словаря минус единица. Следовательно, длина двоичного кода смещения будет округленным в большую сторону log2(размер словаря), а длина двоичного кода для длины подстроки будет округленным в большую сторону log2(размер буфера+1). А символ кодируется 8 битами (например в таблице ASCII+).
В последнем примере длина полученного кода равна 9*(3+3+8)=126 бит, против 14*8=112 бит исходной длины строки.
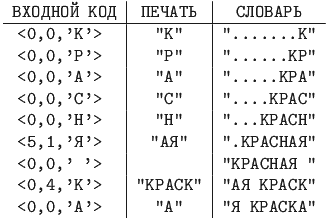
LZ77-алгоритм распаковки данных. Пример 12.4
1. LZ77, длина словаря - 8 байт (символов). Коды сжатого сообщения
-![]()
Недостатки LZ77:
LZ77 обладает следующими очевидными недостатками:
длина подстроки, которую можно закодировать, ограничена размером буфера.
с ростом размеров словаря скорость работы алгоритма-кодера пропорционально замедляется;
кодирование одиночных символов очень неэффективно.
Кодирование одиночных символов можно сделать эффективным, отказавшись от ненужной ссылки на словарь для них. Кроме того, в некоторые модификации LZ77 для повышения степени сжатия добавляется возможность для кодирования идущих подряд одинаковых символов.
Если механически чрезмерно увеличивать размеры словаря и буфера, то это приведет к снижению эффективности кодирования, т.к. с ростом этих величин будут расти и длины кодов для кодирования смещения и длины, что сделает коды для коротких подстрок недопустимо большими.
12.3 LZ-алгоритмы упаковки данных :LZ78
В 1978 г. авторами LZ77 был разработан алгоритм LZ78, лишенный названных недостатков.
LZ78 не использует "скользящее" окно, он хранит словарь из уже просмотренных фраз. При старте алгоритма этот словарь содержит только одну пустую строку (строку длины нуль). Алгоритм считывает символы сообщения до тех пор, пока накапливаемая подстрока входит целиком в одну из фраз словаря. Как только эта строка перестанет соответствовать хотя бы одной фразе словаря, алгоритм генерирует код, состоящий из индекса строки в словаре, которая до последнего введенного символа содержала входную строку, и символа, следующего за совпадением. Затем в словарь добавляется введенная подстрока. Если словарь уже заполнен, то из него предварительно удаляют менее всех используемую в сравнениях фразу.
Ключевым для размера получаемых кодов является размер словаря во фразах, потому что каждый код при кодировании по методу LZ78 содержит номер фразы в словаре. Из последнего следует, что эти коды имеют постоянную длину, равную округленному в большую сторону двоичному логарифму размера словаря +8 (это количество бит в байт-коде расширенного ASCII).
Пример 12.5.
Закодировать по алгоритму LZ78 строку "КРАСНАЯ КРАСКА", используя словарь длиной 16 фраз.
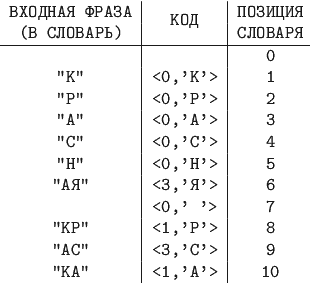
Указатель на любую фразу такого словаря - это число от 0 до 15, для его кодирования достаточно четырех бит.
LZ-алгоритмы распаковки данных. Пример 13.6
LZ78, длина словаря - 16 фраз. Коды сжатого сообщения -
![]()
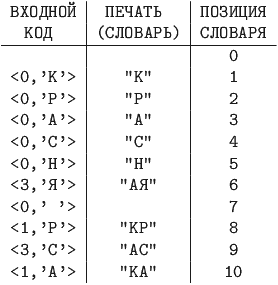
В последнем примере длина полученного кода равна 10*(4+8)=120 битам.
Алгоритмы LZ77, LZ78 и могут использоваться свободно.
В 1984 г. Уэлчем (Welch) был путем модификации LZ78 создан алгоритм LZW, более эффективный чем его прототип. Алгоритм LZW используется как основа во многих известных и эффективных программах сжатия данных программах – архиваторах.
Лекция 13