

5.3 Связь корректирующей способности кода с кодовым расстоянием
При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе символов.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга или просто кодовым расстоянием.
Кодовое расстояние выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d.
Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в сумме этих комбинаций по модулю 2. Например
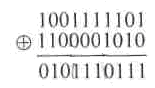
Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют минимальным кодовым расстоянием.
Более полное представление о свойствах кода дает матрица расстояний D, элементы которой dij (i,j = 1,2,...,n) равны расстояниям между каждой парой из всех m разрешенных комбинаций.
Пример: Представить симметричной матрицей расстояний код X1 = 000; Х2 = 001; Х3 = 010;X4=111
Решение. . Минимальное кодовое расстояние для кода d=1.
Это вытекает из рассмотрения симметричная матрицы всех возможных кодовых расстояний между словами кода.
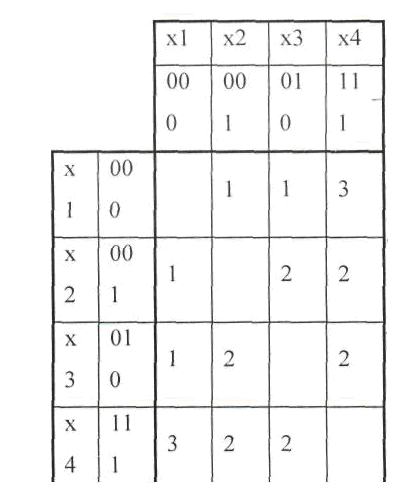
Таблица 5.1
Декодирование после приема производится таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии.
Такое декодирование называется декодированием по методу максимального правдоподобия.
Лекция 6.
6.1 Корректирующие свойства кодов с избыточностью.
Рассмотрим сущность помехоустойчивого кодирования на уже рассмотренном на предыдущей лекции рисунке
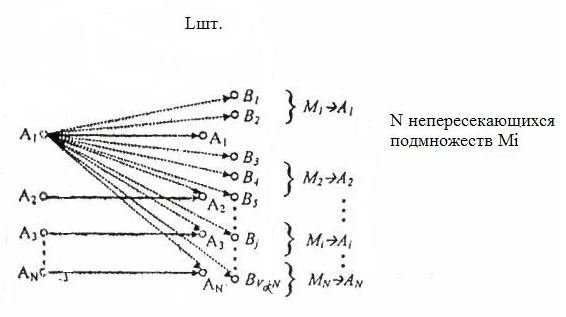
На этом рисунке через Ai (N шт.)обозначенные разрешеные кодовые слова, Bj (L-N)шт.запрещенные слова, а Mi (Nшт.) некоторые подмножества, элементами которых являются те или другие запрещенные кодовые слова.
Из рисунка видно, что при передаче кодовой комбинации Ai она может под воздействием помех перейти в одну из комбинаций Bj, то есть ошибка может быть выявлена (L-N) случаях из общего количества L кодовых слов. Так происходит каждый раз, когда передается любая из N разрешенных кодовых комбинаций. Общее количество ошибочных комбинаций, которые обнаруживаются , равняется N(L-1) а общее количество возможных комбинаций L*N поэтому часть ошибочных комбинаций, которые обнаруживаются , равняется
µ=1-(N/L);
Аналогичный прием используется и для исправления ошибок. Для использования кода как корректирующего надо разбить множества Bj всего (L-N)шт.запрещенных кодовых комбинаций -на N непересекающихся подмножеств Mi. Каждое из подмножеств Mi приписывается одному из кодовых слов Ai . Способ корректировки или исправления ошибок заключается в том, что когда принятая комбинация Bj принадлежит Мi, тогда считается, что передана комбинация Аi. При таком способе декодирования существует возможность исправления ошибок.
Из рисунка видно, что при любом способе разбития ошибка может быть исправлена в L-N (для Bj) случаях и обнаружена в N(L-N) случаях. Отношение количества ошибочных комбинаций, которые исправляются, к количеству ошибочных комбинаций равно 1/N.
Наконец, определим, что количество -ошибок, которые не исправляются равняется N*(N-1) ,при этом часть некорректируемых ошибок по отношению к общему количеству последствий равняется (N-1)/L. Отмеченные результаты имеют общий характер и верны для всех корректирующих кодов.
Мы говорили о корректирующих свойствах кодов с избыточностью.
Рассмотрим теперь простые примеры, которые связывают кодовое расстояние d с корректируюшими свойствами кода.
Очевидно, что при кодовом расстоянии d=1 все кодовые комбинации являются разрешенными.
Например, при n=3 разрешенные комбинации образуют следующее множество:
000,001,010,011, 100, 101, 110, 111 с кодовым расстоянием d=1.
Любая одиночная ошибка трансформирует данную комбинацию в другую разрешенную комбинацию. Это случай безызбыточного кода, не обладающего корректирующей способностью.
Если d = 2, то ни одна из разрешенных кодовых комбинаций при одиночной ошибке не переходит в другую разрешенную комбинацию. Например, подмножество разрешенных кодовых комбинаций может быть образовано по принципу четности в нем числа единиц. Например, для n=3, d=2:
011, 101, 110-разрешенные комбинации;
010, 100, 111 - запрещенные комбинации.
При любой одиночной ошибке разрещенная комбинация преращается в запрещенную. Код обнаруживает одиночные ошибки, а также другие ошибки нечетной кратности .
В общем случае при необходимости обнаруживать ошибки кратности до г включительно минимальное хэммингово расстояние между разрешенными кодовыми комбинациями должно быть по крайней мере на единицу больше r, т.е d >r+1.
Действительно, в этом случае ошибка, кратность которой не превышает r, не в состоянии перевести одну разрешенную кодовую комбинацию в другую.
Для исправления одиночной ошибки кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций множеству исходных кодовыхкомбинаций.
Чтобы эти подмножества не пересекались, хэммингово расстояние между разрешенными кодовыми комбинациями должно быть не менее трех. При n=3 за разрешенные кодовые комбинации можно, например, принять 000 и 111 с d=3. Тогда разрешенной комбинации 000 необходимо приписать подмножество запрещенных кодовых комбинаций 001, 010, 100, образующихся в результате двоичной ошибки в комбинации 000.
Подобным же образом разрешенной комбинации 111 необходимо приписать подмножество запрещенных кодовых комбинаций: 110, 011, 101, образующихся в результате возникновения единичной ошибки в комбинации 111:
Разрешенной комбинации 000 соответствуют запрещенные комбинации 001 010 100.
Если принято любое кодовое слово из этого набора, то по принципу максимального правдоподобия можно предположить, что передавалось кодовое слово 000.
Разрешенной комбинации 111 соответствуют запрещенные комбинации 011 101 110.
Если принято любое кодовое слово из этого набора, то по принципу максимального правдоподобия передавалось кодовое слово 111.
Таким образом для кода 000 и 111 с d=3 может быть исправлена одна ошибка.
В общем случае для обеспечения возможности исправления всех ошибок кратности до s включительно каждая из ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству исходной разрешенной кодовой комбинации.
Ошибка будет не только обнаружена, но и исправлена, если искаженная комбинация остается ближе к первоначальной, чем к любой другой разрешенной комбинации, то есть должно быть:
d>=2S+1;
Рассмотрим геометрическую интерпретацию кодового расстояния d и его связь с числом обнаруживаемых и исправляемых ошибок.
Для выявления произвольных ошибок, которые изменяют в кодовых словах, , не больше r символов, необходимо и достаточно, чтобы никакие r-кратные ошибки не переводили одно кодовое слово кода в другое, смотри рисунок.

Это условие будет выполнено, если кодовые комбинации выбраны так, что среди них нет таких, которые находятся на расстоянии, меньше чем r+1. Если такой код использован для кодировки сообщения, тогда принятое кодовое слово Y, которого нет в списке разрешенных слов, является признаком обнаружением ошибки. Рассмотренные ранее 4 комбинации -000, 011, 101, 110,- представляют код с обнаружением одиночной ошибки, потому что для них кодовое расстояние d = 2. Для того, чтобы код исправлял все ошибки, кратность которых не превосходит s,.векторы каждой пары Xi, Xj должны находиться один от другого на расстоянии, не меньшем чем 2s+1.
В общем случае для выявления ошибок кратности r, одновременного исправления ошибок кратности s необходимо и достаточно выполнение условия
d>=r+s+1.
Кодовое расстояние лишь частично характеризует качество кода, потому что кроме ошибок, которые полностью исправляются или обнаруживаются, часто обнаруживаются или исправляются ошибки большей кратности.
Рассмотрим понятие качества корректирующего кода более подробно.
Одной из основных характеристик корректирующего кода является избыточность кода, указывающая степень удлинения кодовой комбинации для достижения определенной корректирующей способности.
Если на каждые n символов выходной последовательности кодера канала приходится k информационных и r проверочных, то относительная избыточность кода может быть выражена как:
ρ =(n-k)/n=r/n=0…1;
Коды, обеспечивающие заданную корректирующую способность при минимально возможной избыточности, называют оптимальными.
В связи с нахождением оптимальных кодов оценим, например, возможное наибольшее число Q разрешенных или информационных комбинаций n-значного двоичного кода, обладающего способностью исправлять взаимно независимые ошибки кратности до s включительно. Это равносильно отысканию числа комбинаций, кодовое расстояние между которыми не менее d=2s+l.
Общее число различных исправляемых ошибок для каждой разрешенной комбинации составляет
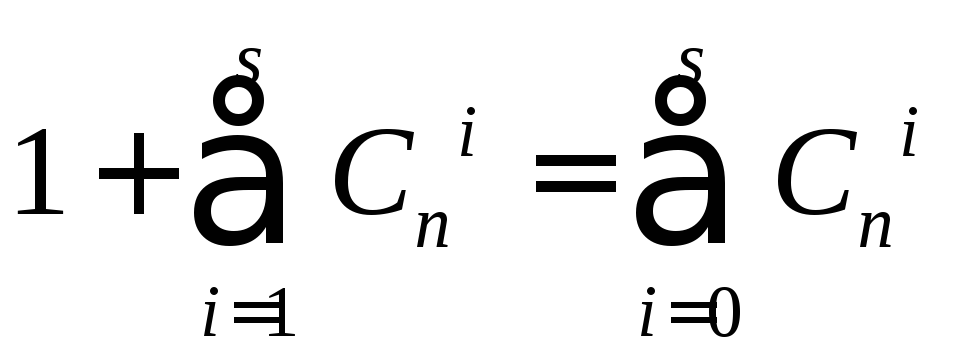
где Сni- число ошибок кратности i<s.
Каждая из таких ошибок должна приводить к запрещенной комбинации, входящей в подмножество Mi для данной разрешенной комбинации. Совместно с этой разрешенной комбинацией подмножество включает всего вот столько комбинаций.
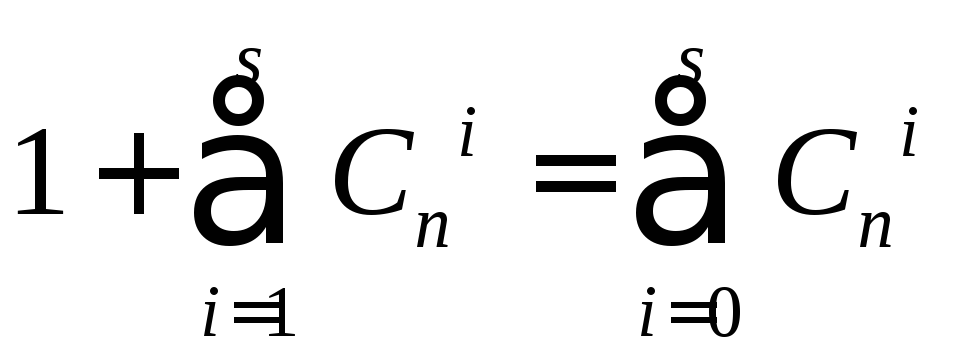
Однозначное декодирование возможно только в том случае, когда указанные подмножества не пересекаются. Так как общее число различных комбинаций n- значного двоичного кода составляет 2n, то число разрешенных комбинаций не может превышать
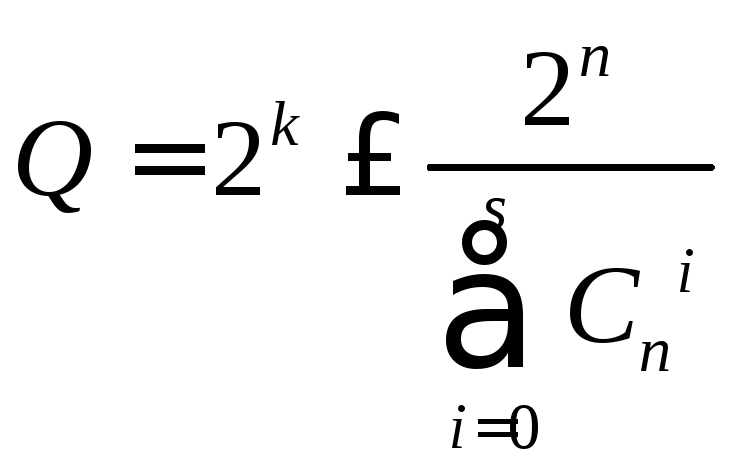
Эта верхняя оценка найдена Хэммингом. Для некоторых конкретных значений кодового расстояния d, соответствующие Q укажем в таблице:
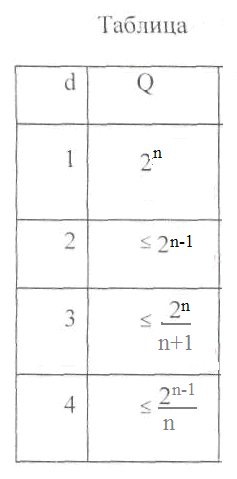
Коды, для которых в приведенном соотношении достигается равенство, называют также плотно упакованными.
Однако не всегда целесообразно стремиться к использованию кодов, близких к оптимальным. Необходимо учитывать другой, не менее важный показатель качества корректирующего кода - сложность технической реализации процессов кодирования и декодирования. Здесь должен искаться компромисс между корректирующими свойствами кода и сложностью технической реализации.
Если информация должна передаваться но медленно действующей и дорогостоящей линии связи, а кодирующее и декодирующее устройства предполагается выполнить на высоконадежных и быстродействующих элементах, то сложность этих устройств не играет существенной роли. Решающим фактором в этом случае является повышение эффективности пользования линией связи, поэтому желательно применение корректирующих кодов с минимальной избыточностью.
Если же корректирующий код должен быть применен в системе, выполненной на элементах, надежность и быстродействие которых равны или близки надежности и быстродействию элементов кодирующей и декодирующей аппаратуры. Это возможно, например, для повышения достоверности воспроизведения информации с запоминающего устройства ЭВМ. Тогда критерием качества корректирующего кода является надежность системы в целом, то есть с учетом возможных искажений и отказов в устройствах кодирования и декодирования. В этом случае часто более целесообразны коды с большей избыточностью, но простые в технической реализации.