

2 Методологічні основи статистичного аналізу соціально-економічних явищ і процесів
2.1 Методологія статистичних групувань. Оформлення статистичного угрупування у вигляді ряду розподілу та його графічне зображення
При проведенні групування ознаки можуть бути атрибутивними або кількісними. Для атрибутивної ознаки число груп відповідає числу їх різновидів.
Якщо групувальна ознака кількісна, постає питання про кількість груп та межі кожної з них. Кількість груп залежить від ступеня варіації групувальної ознаки та обсягу сукупності. Так, для дискретної ознаки, діапазон варіації якої обмежений (кількість дітей у сім’ї, тарифний розряд тощо), груп, як правило, стільки, скільки варіант ознаки. Якщо розглядається неперервна ознака (стаж роботи працівника, собівартість продукції) або у разі значної варіації дискретної ознаки (кількість працюючих на підприємстві, кількість укладених на біржі угод) діапазон варіації розбивається на m інтервалів.
Орієнтовно оптимальна кількість груп визначається за стандартними
процедурами, зокрема за формулою Стерджеса:
![]() (2.1)
(2.1)
де Хmax, Хmin - найбільше та якнайменше значення ознаки,
m - кількість груп.
Кількість груп визначається або самостійно, або за формулою:
m = 1 + 2,30259 lg n, (2.2)
де n — обсяг сукупності;
m — число інтервалів (груп).
де Хmax, Хmin - найбільше та якнайменше значення ознаки,
m - кількість груп.
Визначаючи межі інтервалів, ширину h доцільно округлювати. Якщо діапазон варіації ознаки надто широкий і поділ значень нерівномірний, беруть нерівні інтервали, зокрема сформовані за принципом кратності, коли ширина кожного наступного інтервалу в k раз більша (менша), ніж попереднього.
Принцип рівних частот використовують нечасто і переважно в аналітичних групуваннях, щоб уникнути зважування групових середніх. При утворенні інтервалів за цим принципом не буває нечисленних груп, що дозволяє отримати достовірну характеристику кожної групи.
Групування проводять за однією або за декількома ознаками. Групування по одній ознаці є простим, по декількох - складним. Останнє може бути комбінаційним, якщо в його основі послідовно скомбіновано дві або більше ознаки, або багатовимірним, якщо воно проводиться по декількох ознаках одночасно.
Надалі, шляхом добавлення величини інтервалу до мінімального значення ознаки у групі («нижньої границі»), одержують групи об'єктів за розміром аналізованої ознаки. Результати такого угрупування надаються у таблиці за формою таблиці 2.1.
Таблиця 2.1 - Схема угрупування
|
№ групи |
Межі групи |
Кількість одиниць сукупності | |
|
в абсолютному вираженні |
% до підсумку | ||
|
… |
… |
… |
… |
|
… |
…. |
… |
… |
|
|
Разом |
|
100,0 |
Таким чином, на основі групування одиниць спостереження за однією ознакою та підрахунків числа одиниць в кожній групі одержують ряд розподілу, який складається з двох елементів: варіант (окремі значення ознаки, що варіює) та частот.
Ряд розподілу за величиною груповочної ознаки можливо представити графічно у вигляді полігону або гістограми.
Для графічного подання рядів розподілу використовують три види графіків: гістограму, полігон та кумуляту.
Полігон використовується для графічного зображення дискретних та атрибутивних рядів розподілу. Це лінійний графік, при цьому по осі Х відкладаються значення варіант, а по осі У – частоти.

Рисунок 2.1 – Приклад побудови полігону
Гістограму можна перетворити у полігон, з`єднавши відрізками прямої середини верхівок стовпчиків. Наведемо приклад побудови полігону, побудованого на основі дискретного ряду розподілу шкіл за кількістю класів:
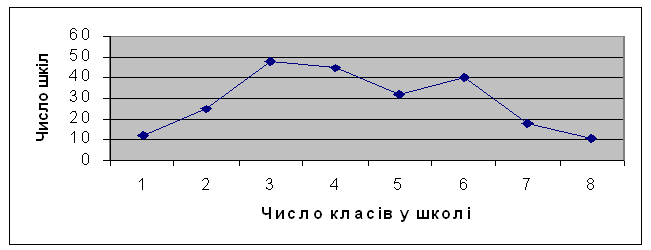
Рисунок 2.2 –Приклад побудови гістограми
2.2 Розрахунок середньої та характеристик варіації. Оцінка довірчих меж для середньої
Середня арифметична величина є найбільш поширеним видом середньої. Вона використовується у тому випадку, коли обсяг варіюючої ознаки одержується як сума індивідуальних значень. Середня арифметична величина має таку загальну логічну формулу розрахунку:
![]() (2.3)
(2.3)
У тому випадку, коли середня величина визначається на основі індивідуальних, тобто незгрупованих даних, використовується формула середньої арифметичної простої:
![]() (2.4)
(2.4)
Середня гармонійна величина використовується у тому випадку, якщо відомі обернені значення осереднюваного показника. У цьому разі:
![]() (2.5)
(2.5)
де х — значення прямого (осереднюваного) показника;
![]() —
значення
оберненого показника.
—
значення
оберненого показника.
Для індивідуальних (незгрупованих) даних використовується середня гармонійна проста:
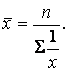 (2.6)
(2.6)
Для рядів розподілу застосовують середню гармонійну зважену:
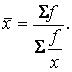 (2.7)
(2.7)
Частіше при розрахунках середньої величини використовується середня гармонійна у вигляді:
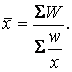 (2.8)
(2.8)
![]() де: W = хf
— значення об’ємного показника;
де: W = хf
— значення об’ємного показника;
х — значення осереднюваного показника.
Остання формула застосовується у тих випадках, коли частоти у явній формі невідомі, а є готові добутки варіант і частот (W = xf).
Обмежене використання у статистиці знаходять середня квадратична та середня геометрична величини.
Середня квадратична (проста і зважена) обчислюються за формулами:
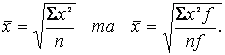 (2.9)
(2.9)
Вона використовується при розрахунках показників варіації (середнього квадратичного відхилення) у модифікованому вигляді.
Середня геометрична величина застосовується тоді, коли обсяг ознаки дорівнює не сумі, а добутку варіант. Її формула має вигляд:
![]() (2.10)
(2.10)
За наведеною формулою підраховується середній коефіцієнт росту, при цьому Х – ланцюгові коефіцієнти росту.
У окремих випадках виникає потреба визначити узагальнений середній показник по декількох ознаках одночасно. Він має назву багатомірної середньої. При цьому осереднюються не абсолютні значення ознак, а коефіцієнти відношення до середнього рівня по кожній ознаці. Названі коефіцієнти визначаються за формулою:
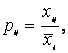 (2.11)
(2.11)
де: і = 1, 2, 3, ....... , m — число ознак;
j = 1, 2, 3, ....... , n — число одиниць у сукупності.
Багатомірна середня має вигляд:
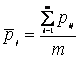 (2.12)
(2.12)
Основні характеристики міри і ступеня варіації:
1) Розмах варіації:
R = Xmax – Xmin.
Цей показник, як бачимо, базується на крайніх значеннях ознаки. Може статись, що одне з цих значень є цілком випадкове, тому R не є надійним показником варіації.
2) Середнє лінійне відхилення:
![]() (2.13)
(2.13)
(при умові обчислення з первинних даних),
![]() (2.14)
(2.14)
(дані згруповані).
Ця характеристика показує, наскільки в середньому відхиляються індивідуальні значення ознаки від середньої по сукупності.
Ця характеристика в математичному відношенні дещо некоректна, бо при її обчисленні ігноруються математичні знаки.
Абсолютно коректними в цьому відношенні є такі характеристики, як дисперсія і середнє квадратичне відхилення.
3) Дисперсія (середній квадрат відхилення)
![]() (2.15)
(2.15)
(при умові обчислення з первинних даних),
![]() (2.16)
(2.16)
(дані згруповані).
Дисперсія – величина абстрактна (не має одиниці виміру).
4) Середнє квадратичне відхилення
![]() . (2.17)
. (2.17)
За економічним змістом середнє квадратичне відхилення і середнє лінійне відхилення однакові, а за числовим значенням, при умові симетричного розподілу вони мають такий зв’язок:
![]() . (2.18)
. (2.18)
Наведені вище характеристики є показниками міри варіації. Вони не можуть бути використані для порівняння міри варіації по двох сукупностях при різних середніх та для порівняння міри варіації різних ознак по одній і тій же сукупності.
Це завдання можна вирішити за допомогою характеристик ступеня варіації.
5) Коефіцієнт варіації
![]() –лінійний
коефіцієнт варіації.
(2.19)
–лінійний
коефіцієнт варіації.
(2.19)
![]() –квадратичний
коефіцієнт варіації.
(2.20)
–квадратичний
коефіцієнт варіації.
(2.20)
Ця характеристика показує на скільки % в середньому відхиляються індивідуальні значення ознаки від середнього її значення по сукупності.
Довірчий інтервал — інтервал, у межах якого з заданою довірчою імовірністю можна чекати значення оцінюваної (шуканої) випадкової величини.
Застосовується для більш повної оцінки точності в порівнянні з точковою оцінкою.
Межі
довірчого інтервалу для середньої
визначаються на основі точкової оцінки
та граничної помилки вибірки
![]() . Наприклад, для факторного показника
визначення довірчих меж ввідбувається
наступним чином:
. Наприклад, для факторного показника
визначення довірчих меж ввідбувається
наступним чином:
![]() ;
(2.21)
;
(2.21)
де — стандартна (середня) помилка вибірки (необхідно надати її поняття);
t — квантиль розподілу ймовірностей (коефіцієнт довіри, що відповідає ймовірності ).
Величину стандартної помилки можна визначити за формулою для відбору:
повторного
![]() (2.22)
(2.22)
безповторного
![]()
![]() (2.23)
(2.23)
де n - обсяг вибірки,
D – частка вибіркової сукупності в генеральній.
2.3 Методологія побудови та аналізу моделі парної регресії
Оскільки статистичні явища пов'язані між собою та обумовлюють одне одне, то необхідні спеціальні статистичні методи аналізу, які дозволяють вивчити форму, близькість та інші параметри статистичних взаємозв'язків. Одним з таких методів є кореляційний аналіз. На відміну від функціональних залежностей, при яких зміна будь-якої ознаки – функції – повністю та однозначно визначається зміною іншої ознаки-аргументу, при кореляційних формах зв'язку змінам одного або декількох факторів відповідає зміна середнього значення результативної ознаки. При цьому фактори, що розглядаються визначають результативну ознаку повністю.
За даними курсової роботи на рівень продуктивності праці оказують вплив не тільки показники фондомісткості, стажу та інші, но й багато інших: технічний рівень виробництва, характер організації праці і т.д. У тому випадку, якщо досліджується зв'язок між одним фактором та однією ознакою, зв'язок має назву однофакторного та кореляція є парною. Якщо досліджується зв'язок між декількома факторами та однією ознакою, зв'язок має назву багатофакторного та кореляція є множинною.
На першому етапі дослідження взаємозв'язків між факторами необхідно з множини факторів, які сформовані шляхом інтуітивних міркувань, відібрати ті, які дійсно вагомі з точки зору їхнього впливу на показник. Рішення завдань такого виду здійснюється за допомогою дисперсійного аналізу – однофакторного, якщо перевіряється істотність впливу того чи іншого фактора, або багатофакторного у випадку вивчення впливу на нього комбінації факторів.
Для вивчення зв'язку між явищами та їх ознакам будують кореляційну таблицю та аналітичне угрупування.
Кореляційна таблиця – це спеціальная комбінаційна таблиця, в якій наведено групування за двома пов'язаними ознаками: факторною та результативною. Концентрація частот біля діагоналей матриці свідчить про наявність кореляційного зв'язку між ознаками.
Аналітичне угрупування дозволяє вивчити взаємозв'язок факторної та результативної ознаки. Основні етапи проведення такого угрупування:
1. Обгрунтування факторної та результативної ознаки.
2. Підрахунок кількості одиниць в кожній з груп, що утворені.
3. Визначення обсягу ознак, що варіюють, в границях створених груп.
4. Розрахунок середніх значень результативної ознаки.
Результати групування оформлюються у таблиці (див. табл. 2.2). Кількість груп можна визначити за формулою Стреджеса, методом «сігм» або прийняти самостійно.
Таблиця 2.2 - Схема аналітичного угрупування
|
Межі угрупування по факторній ознаці, хj |
Кількість одиниць сукупності, fi |
Середнє значення результативної ознаки у групі j, уj |
|
|
f1 |
у1 |
|
|
f2 |
у2 |
|
|
:: |
:: |
|
Разом |
|
х |
Відомо, що якщо сукупність розбито на групи за певною ознакою х, то для будь-якої іншої ознаки у можна обчислити середню як у цілому по сукупності, так і в кожній групі. Центром розподілу сукупності в цілому є загальна середня
 або
або
![]() або
або![]() (2.24)
(2.24)
центром розподілу в j-й групі — групова середня
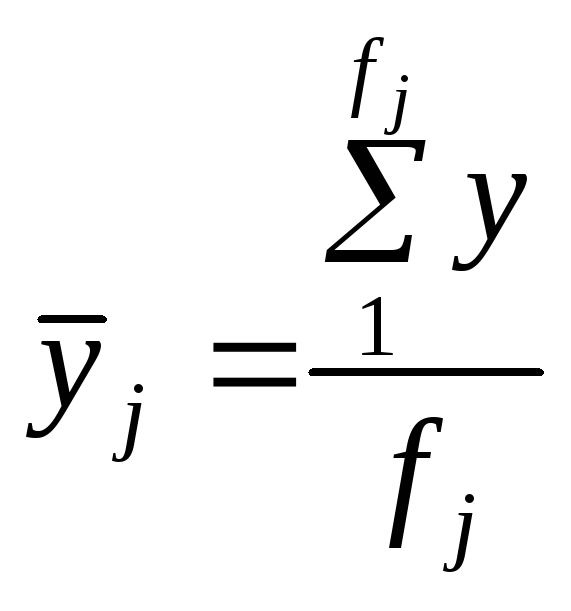 або
або
![]() (2.25)
(2.25)
де fi – частота і-го елементу сукупності,
nj = fj - обсяг j-ї групи,
n - обсяг сукупності
Для перевірки істотності зв'язку можна використовувати характеристику F-критерій (критерій Фішера), який визначається за формулою:
![]() ,
(2.26)
,
(2.26)
де
![]() ,
, ![]() -
відповідно факторна (міжгрупова) та
залишкова дисперсія
-
відповідно факторна (міжгрупова) та
залишкова дисперсія
k1, k2 - число ступенів свободи відповідно факторної та залишкової дисперсії
![]() =
m - 1;
=
m - 1;
![]() =n–m
(2.27)
=n–m
(2.27)
де n, m - відповідно число одиниць сукупності та кількість груп.
![]() (2.28)
(2.28)
![]() (2.29)
(2.29)
Тобто
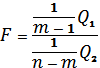 , (2.28)
, (2.28)
де
![]() (2.30)
(2.30)
![]() (2.31)
(2.31)
де уij – значення показника у, якій відповідає і-му елементу в j–й групі
![]() - середнє значення
показника у в j–й групі
- середнє значення
показника у в j–й групі
Надалі одержане розрахункове значення F порівнюється за табличним (критичним), для визначеного рівня істотності (звичайно 0,05 або 0,01) та ступенів свободи k1 та k2 .
Якщо Fрозр ≤ F табл, то вплив відповідного фактора визнається неістотним. Якщо, навпаки, Fрозр ≥ Fтабл – вплив істотний.
Сформований у результаті процедури, що описана, набір істотних факторів використовується на наступних етапах дослідження: при побудові відповідних парних моделей регресії або рівняння множинної регресії.
Рівняня
регресії досліджується у вигляді Y=|![]() (де Y
— розрахунковий (теоретичний) рівень
результативної ознаки).
(де Y
— розрахунковий (теоретичний) рівень
результативної ознаки).
Розрахунок коефіцієнтів рівняння можна здійснити за формулами
![]() (2.32)
(2.32)
![]() (2.33)
(2.33)
Необхідно побудувати кореляційне поле за емпіричними (вихідними) даними та «наложити» на нього лінію регресію, що побудована за визначенним рівнянням регресії, що дозволяє зробити попередні висновки про відповідність рівняння вихідним даним.
Вплив та напрямок однофакторного зв'язку характеризує лінійний коефіцієнт кореляції, який можна визначити за формулою
![]() (2.34)
(2.34)
Зауважимо, що за формулою лінійного коефіцієнту розраховуються також парні коефіцієнти кореляції, які характеризують тісноту зв'язку між парами змінних, що розглядаються (без урахування їх взаємодії з іншими змінними).
Показником тісноти зв'язку між результативною та факторною ознакою є коефіцієнт детермінації (множинної кореляції)
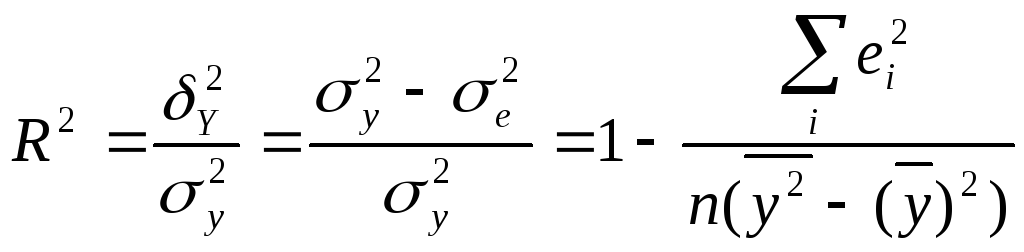 (2.35)
(2.35)
де
![]() — загальна дисперсія ознаки y;
— загальна дисперсія ознаки y;
![]() - факторна дисперсія;
- факторна дисперсія;
σ![]() - залишкова дисперсія
- залишкова дисперсія
![]() (2.36)
(2.36)
![]() (2.37)
(2.37)
![]() (2.38)
(2.38)
де Y, у|в| - відповідно розрахункові та фактичні значення результативної ознаки.
Тобто
![]() (2.39)
(2.39)
Якщо
![]() ,
це свідчить про лінійний зв'зок міжх
та у.
,
це свідчить про лінійний зв'зок міжх
та у.
Для встановлення адекватності моделі можна також використовувати F-критерій Фішера
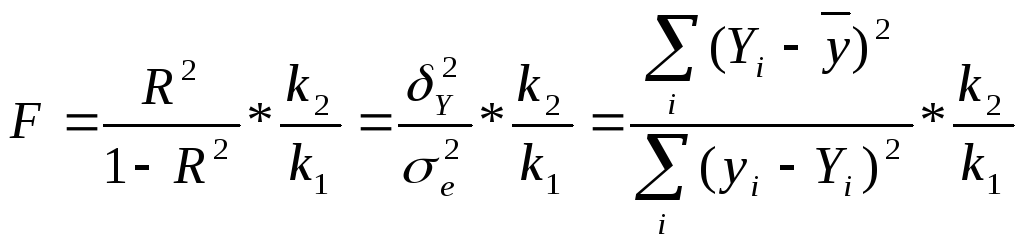 (2.40)
(2.40)
Тобто у випадку парної кореляції для лінійної моделі розрахункове значення F можна знайти за формулою:
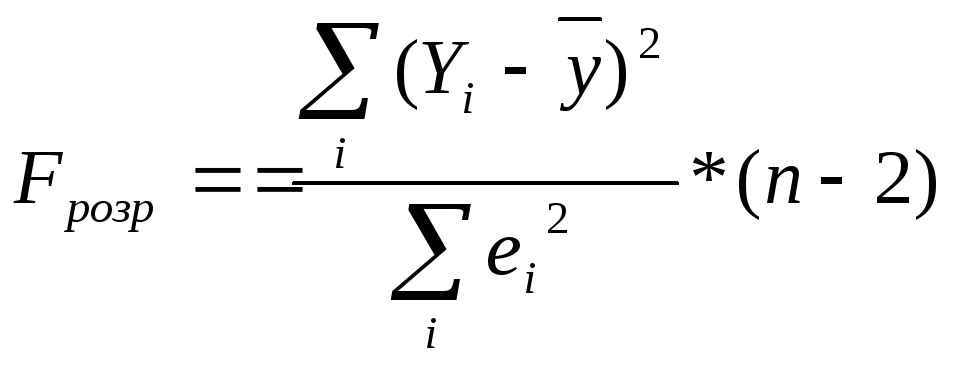 (2.41)
(2.41)
Як і в методі аналітичних групувань, надалі одержане розрахункове значення F порівнюється за табличним (критичним) для визначеного рівня істотності (звичайно 0,05 або 0,01), тобто з Fα(1, n-2)
Якщо Fрозр ≤ F табл, то вплив відповідного фактора визнається неістотним. Якщо, навпаки, Fрозр ≥ Fтабл – вплив істотний.
Необхідно також здійснювати оцінку статистичної значущості коефіцієнтів b0 та b1. Така оцінка здійснюється за допомогою t-критерію Ст'юдента. При цьому визначають розрахункові (фактичні) значення:
- для параметру b1
![]() (2.42)
(2.42)
- для параметру b0
![]() (2.43)
(2.43)
де S(b) – середньоквадратичне відхилення відповідного параметру
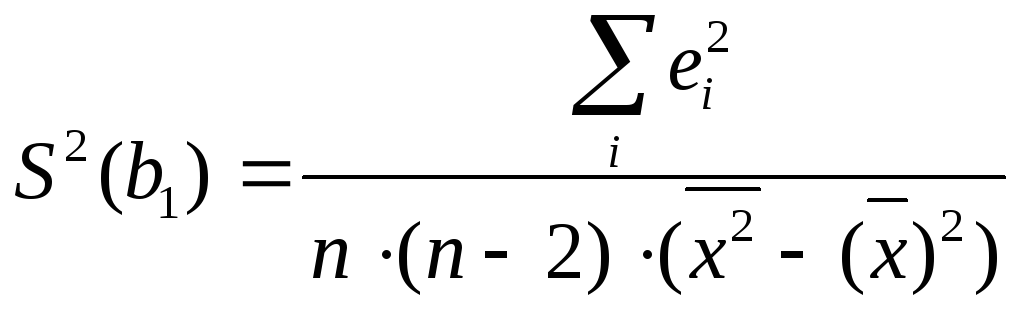 (2.44)
(2.44)
![]() (2.45)
(2.45)
де S2(b) – дисперсія відповідного параметру
Розрахункові значення t-критерію Ст'юдента порівнюють з табличними, які обираються в залежності від рівня істотності та числа ступенів свободи n -m -1 (де n – обсяг вибірки, m - кількість факторних ознак, що включено до моделі, тобто для однофакторної моделі число ступенів свободи дорівнює n-2). Критичні значення можна визначити за додатком 3 (наприклад, для одностороньої критичної області t0,05;14=1,76). Параметр визнається істотним, якщо розрахункове значення більше табличного.
За відповідними розрахунками можливо також одержати прогноз довірчого інтервалу для значення yn+1 та для його математичного очікування Myn+1. Для значення yn+1 границі довірчих меж визначаються за формулою
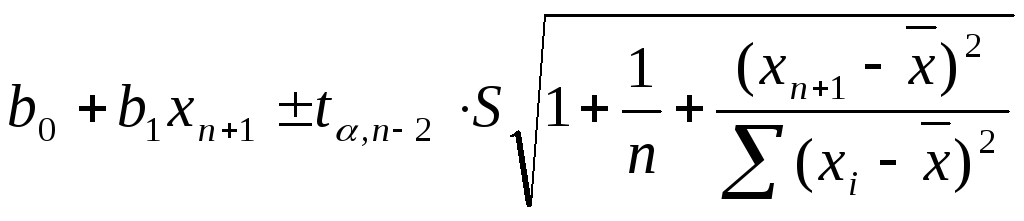 (2.46)
(2.46)
Для значення Myn+1 границі довірчих меж визначаються за формулою:
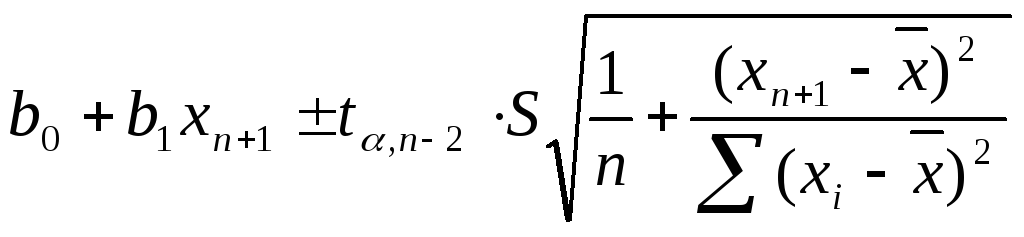 ,
(2.47)
,
(2.47)
де S2- незсунена оцінка для залишкової вибіркової дисперсії
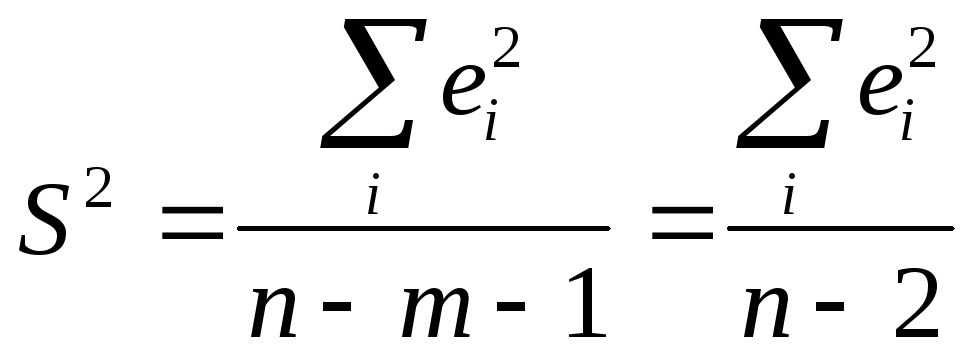 ,
(2.48)
,
(2.48)
2.4. Методологія множинного регресійного аналізу.
Економічні явища залежать від великої кількості факторів. Тому на практиці часто використовують рівняння множинної|факторів| регресії, коли на величину результативної ознаки впливають два і більш фактори.
Одна з умов кореляційного аналізу - однорідність досліджуваної інформації. Критерієм однорідності інформації служать коефіцієнти варіації, які розраховуються по кожному факторному й результативному показнику.
Коефіцієнт варіації показує відносну міру відхилення окремих значень від середньоарифметичної.
Після|потім| відбору факторів і оцінки початкової|вихідної| інформації важливим|поважним| завданням|задачею| є|з'являється| моделювання зв'язку між факторним|факторами| і результативним показником. На практиці найчастіше використовують багатофакторні лінійні моделі |факторів| і моделі, які приводяться|наводять| до лінійного вигляду|виду| відповідними перетвореннями, тобто|цебто|
![]() (2.49)
(2.49)
Рішення задачі багатофакторного кореляційного аналізу передбачає визначення парних коефіцієнтів кореляції, які характеризують тісноту зв'язку між парами змінних, що розглядаються (без врахування їхньої взаємодії з іншими змінними). Парні коєфіцієнти кореляції можна розрахувати за формулою лінійного коефіцієнту (див. формулу 2.16).
Показником тісноти зв'язку між результативною та факторними ознаками є коефіцієнт множинної кореляції.
У випадку лінійного двохфакторного зв'язку він може бути розрахован за формулою:
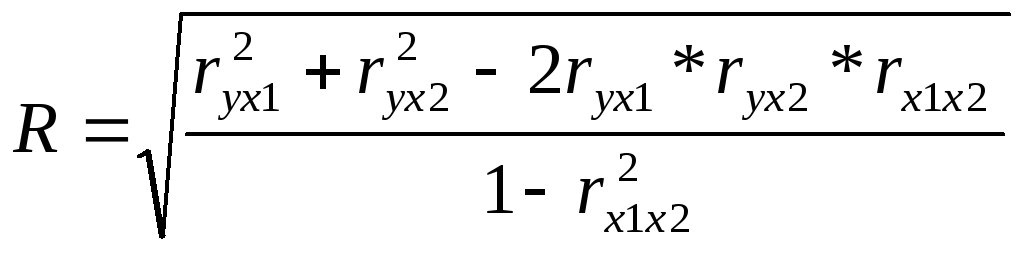 (2.50)
(2.50)
де r – лінійні (парні) коефіцієнти кореляції.
Значення цього коефіцієнту змінюється від 0 до 1. Коефіцієнт R2 має назву множинного коефіцієнту детермінації та показує, яка частка варіації результативної ознаки обумовлена впливом факторів, що враховано.
Наступним етапом кореляційно регресійного аналізу є побудова рівняння множинної регресії та визначення невідомих параметрів b0, b1 ,b2 ,….,bm обраноїх функції. Наприклад, рівняння двохфакторної лінійної регресії має вигляд
![]() (2.51)
(2.51)
де Y - розрахункові значення результативної ознаки,
хі – значення факторних ознак,
b0, b1 ,b2 – параметри рівняння регресії.
Для
визначення параметрів
![]() ,
,
![]() ...
необхідно скласти і вирішити систему
нормальних рівнянь. При
двох факторах система
рівнянь набуває вигляду
...
необхідно скласти і вирішити систему
нормальних рівнянь. При
двох факторах система
рівнянь набуває вигляду
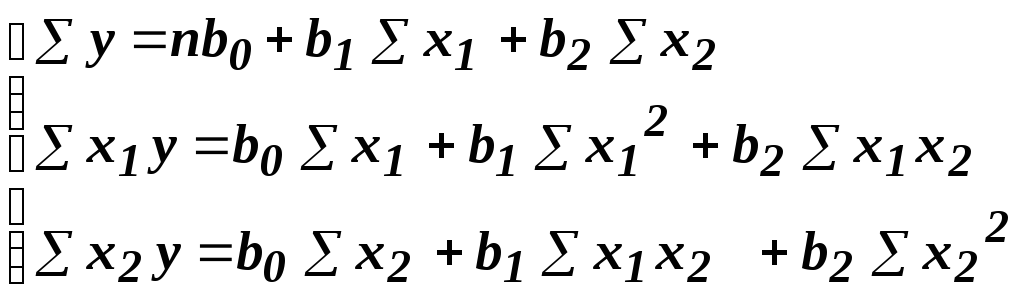 (2.52)
(2.52)
Рівняння лінійної множинної регресії можна також одержати, використовуючи програму «Microsoft Excel – Статистические функции – ЛИНЕЙН (відомі_значення_y;відомі_значення_x;конст;статистика)». Функція ЛИНЕЙН повертає масив {bm; bm-1; ... ; b1;b}, де m - кількість факторних ознак, що включено до моделі.
Відомі_значення_y - це безліч значень y, що уже відомі для співвідношення y = b1x1 + b2x2 + ... + b
Якщо масив відомі_значення y має один стовпець, то кожний стовпець масиву відомі значення x інтерпретується як окрема змінна.
Якщо масив відомі значення y має один рядок, то кожний рядок масиву відомі значення x інтерпретується як окрема змінна.
Відомі значення x - це необов'язкова множина значень x, що уже відомі для співвідношення y = b1x1 + b2x2 + ... + b
Масив відомі значення x може містити одне або декілька множин змінних. Якщо використовується тільки одна змінна, то відомі значення y і відомі значення x можуть бути масивами будь-якої форми за умови, що вони мають однакову розмірність. Якщо використовується більш однієї змінної, то відомі значення y повинні бути вектором (тобто інтервалом висотою в один рядок або шириною в один стовпець).
Якщо відомі значення x опущені, то передбачається, що це масив {1;2;3;... } такого ж розміру як і відомі значення y. Конст - це логічне значення, що вказує, чи потрібно, щоб константа b дорівнювала 0.
Якщо конст має значення ИСТИНА або опущена, то b обчислюється звичайним способом.
Якщо конст має значення ЛОЖЬ, то b покладається рівним 0 і значення bі підбираються так, щоб виконувалося співвідношення y = bx. Статистика - це логічне значення, що вказує, чи потрібно повернути додаткову статистику по регресії.
Якщо статистика має значення ЛОЖЬ або опущена, то функція ЛИНЕЙН повертає тільки коефіцієнти bі і постійну b. У цьому випадку регресійна статистика повертається за формою таблиці 2.3
Таблиця 2.3 – Регресійна статистика
|
bm |
bm-1 |
…. |
b2 |
b1 |
b |
Якщо статистика має значення ИСТИНА, то функція ЛИНЕЙН повертає додаткову регресійну статистику (див. табл. 2.4)
Таблиця 2.4 – Додаткова регресійна статистика
|
bm |
bm-1 |
…. |
b2 |
b1 |
b |
|
|
|
…. |
|
|
|
|
R2 |
|
|
|
|
|
|
F-критерій |
df (ступені свободи) |
|
|
|
|
|
|
|
|
|
|
|
Наступним етапом є розрахунок та перевірка статистичної значущості коефіцієнту детермінації, що відповідає визначенному теоретичному рівнянню, та значущості коефіцієнтів регресії.
Коефіцієнт детермінації, який надає оцінку загальної якості моделі, розраховується за формулою
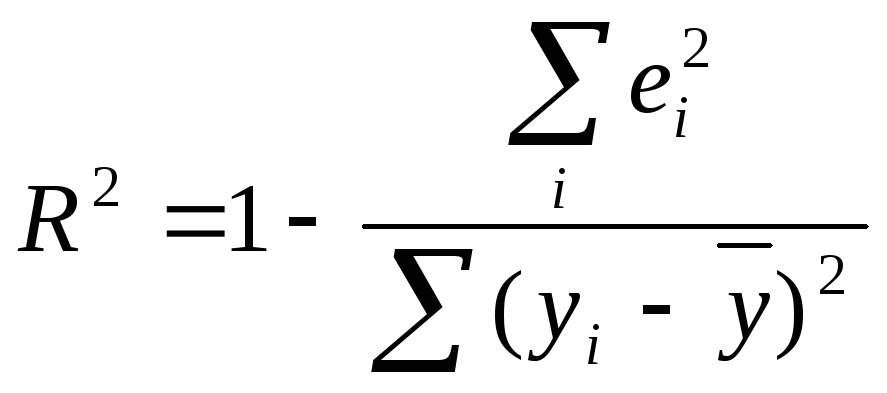 (2.53)
(2.53)
де
![]()
Перевірку статистичної істотності коефіцієнту детермінації можна здійснити за допомогою критерію Фішера, розрахункове значення якого визначається за формулою
![]() (2.54)
(2.54)
де n – обсяг вибірки,
m - кількість факторних ознак, що включено до моделі (кількість змінних у рівнянні)
Одержане розрахункове значення F порівнюється з табличним для визначеного рівня істотності , тобто з Fα (m; n -m -1). Якщо Fрозр ≥ Fтабл – коефіцієнт детермінації статистично значущ.
Оцінка істотності коефіцієнтів регресії здійснюється за допомогою t-критерію Ст'юдента. При цьому визначають розрахункові (фактичні) значення:
![]() (2.55)
(2.55)
де
![]() -
оцінка стандартної помилки коефіцієнту
-
оцінка стандартної помилки коефіцієнту
Розрахункові значення t-критерію Ст'юдента порівнюють з табличними, які обираються в залежності від рівня істотності та числа ступенів свободи
n-m-1. Параметр визначається істотним, якщо розрахункове значення перевищує табличне.
Висновки по розділу 2
1.До основних методологічних основ статистичного аналізу соціально-економічних явищ та процесів належать методологія статистичних групувань, методологія середніх величин та показників варіації, методологія рядів динаміки та методологія статистичних прийомів вивчення взаємзв’язків.
2. Методологія статистичних групувань залежить від виду ознаки, що групується, на основі проведеного групування можливо робити висновки про наявність зв’язку між ознаками. В результаті спостереження та групування статистичних матеріалів, отримують цифрові показники, які характеризують чи зміну явища в динамиці, чи розподілення одиниць сукупності за тими чи іншими вар’їруючими ознаками у статиці. При рівності фінтервалів існує формула Стреджеса, за допомогою якої визначають кількість груп при відомій чисельності сукупності.
3. За допомогою середніх можливо зрівнювати між собою різні сукупності за вар’їруючими ознаками. Середні показники широко використовуються для характеристики закономірностей розвитку явищ а процесів. Для того, щоб середня була достовірною, сукупність повинна бути якісно однорідною по відношеннь до ознаки, що осереднюється. Вибіркові характеристики дають можливість визначити межу зміни показників, що аналізуємо, генеральної сукупності. В роботі наведені формули основних видів середніх величин, формули середнього лінійного відхилення, дисперсії, середнього квадратичного відхилення, коефіцієнта варіації, формули оцінки середніх та стандартних помилок.
4.Для дослідження взаємозв'язків між факторами необхідно з множини факторів, які сформовані шляхом інтуітивних міркувань, відібрати ті, які дійсно вагомі з точки зору їхнього впливу на показник. Рішення завдань такого виду здійснюється за допомогою дисперсійного аналізу – однофакторного, якщо перевіряється істотність впливу того чи іншого фактора, або багатофакторного у випадку вивчення впливу на нього комбінації факторів. Для вивчення зв'язку між явищами та їх ознакам будують кореляційну таблицю та аналітичне угрупування.