

Методичка__Сарычева Т.В
..pdfвведите данные в столбец С, как показано на рис. 6.:
в ячейку С1 введите метку «ln x»;
в ячейку С2 и введите формулу «=LN(B)».
скопируйте формулу в остальные ячейки столбца С, выделив С2 и дважды щелкнув по маркеру заполнения в правом нижнем углу. Логарифмы исходных значений доли трудоспособного населения появятся в столбце D.
В меню Сервис выберите Анализ данных. В диалоговом окне
Анализа данных выберите Регрессия и нажмите Ok.
Появится диалоговое окно Регрессии.
Входной интервал Y: укажите на листе или введите ссылки на диапазон со значениями зависимой переменной (D1 :DI3), включая метку в первой строке.
Входной интервал Х: укажите на листе или введите ссылки на диапазон со значениями независимой переменной (C1:C13), включая метку в первой строке.
Метки: включите эту опцию, так как во Входные интервалы
xи y были включены подписи.
Не выбирайте пункты Константа - Ноль и Уровень
надежности.
Параметры вывода: щелкните по кнопке Выходного интервала, выберите текстовую строку справа и укажите на листе или введите ссылку на левую верхнюю ячейку области шириной в 16 столбцов, где будут располагаться результаты и диаграммы (Е1).
Дополнительно можно включить Остатки.
Нажмите Ok.
На рис. 6 представлены результаты инструмента регрессии. По сравнению с линейной моделью, рассмотренной в предыдущей лабораторной работе, данная логарифмическая модель имеет меньшую стандартную ошибку и большее R2; в соответствии с этим логарифмическая модель несколько лучше линейной.
71
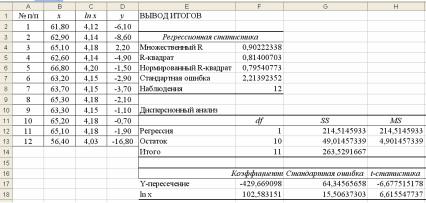
Рисунок 6 – Результаты для логарифмической регрессии
Детальный анализ построенной модели зависимости коэффициента естественного прироста населения от доли трудоспособного населения в форме логарифмической функции выполните самостоятельно.
Чтобы осуществить прогноз коэффициента естественного прироста населения от доли трудоспособного населения на уровне 63,45% в логарифмической форме:
введите значение 63,45 в ячейку (например, B14)
в ячейке С14 рассчитайте логарифм значения, представленного в ячейке B14: «=LN(B14)»;
введите формулу для предсказанного коэффициента естественного прироста населения в ячейке D14
«=F17+F18*C1».
Самостоятельно
По данным Вашего варианта приложения В постройте полиномиальное, логарифмическое, степенное и экспоненциальное приближения. Опишите в отчете, выполненном в MS Word полученные результаты.
Сделайте вывод о том, какая из функций лучше описывает исследуемую Вами взаимосвязь.
72
Лабораторная работа № 3. Построение моделей парной регрессии в ППП Statistica
Задача:
В файле Задача 3.sta представлены данные за 15 лет о численности населения РФ (млн. чел) и численности занятых (млн. чел) (Приложение Б).
Необходимо:
4. Построить уравнения зависимости численности населения y от численности занятых x с использованием
следующих моделей:
Линейной
Полинома второй степени
5.Оценить качество, точность, надежность и статистическую значимость каждого уравнения регрессии
6.Сравнить полученные результаты. Выделить лучшую модель.
7.Построить прогноз численности населения, при занятости на уровне 64 млн. чел.
Решение:
1Произведите расчет парного коэффициента корреляции и проанализируйте его значение
1.1Запустите программу Statistica
(Пуск – Программы – STATISTICA)
1.2Откройте файл Задача 3.sta (Файл – Открыть – Задача 3.sta)
1.3Рассчитайте коэффициент парной корреляции:
В главном меню рабочего окна выберите пункт меню
Статистика
В открывшемся подменю выберите пункт Основная
статистика / Таблицы
73

В открывшемся окне Basic Statistica and Tables (Основные статистики и таблицы) выберите пункт Correlation matrices (Корреляционные матрицы) как представлено на рис. 1.
Рисунок 1 – Основные статистики и таблицы
Откроется окно Product – Moment and Partial correlations (Парные и частные корреляции) следующего вида (рис.2):
Рисунок 2 – Парные и частные корреляции
74

Нажмите на кнопку Summary: Correlation matrix (Корреляционная матрица).
В открывшемся окне Select one or two variable lists (Выбор одной или двух переменных) в поле First variable list (Первая переменная) щелчком мыши укажите Y, в поле Second variable list (optional) (вторая переменная) – X, так как показано на рис. 3.
Рисунок 3 – Выбор переменных
Нажмите Ok.
Значение парного коэффициента корреляции rxy 0,86
отразилось в окне Correlations (Корреляции) (рис.4).
Рисунок 4 – Значение коэффициента корреляции
Так как значение парного коэффициента выделено красным цветов, следовательно можно сделать вывод о его статистической
75
значимости. Аналогичный вывод позволяет сделать запись «Marked correlations are significant at p < ,05000» данного окна, говорящая о том, что уровень значимости p<0,05.
Отдцательное значение коэффициента парной корреляции говорит об обратной (отрицательной) связи между исследуемыми показателями, то есть при численности занятого населения численность населения в РФ будет сокращаться. Так как ryx 0,86 0.7;1,0 следовательно связь между признаками
сильная, что позволяет сделать вывод о возможности построения в форме линейной зависимости между переменные.
2 Построение парной линейной регрессионной модели
Закройте окно Correlation щелчком мыши на кнопке закрыть (крестике), расположенной в верхнем правом углу окна.
В меню Статистика выберите пункт Множественная регрессия.
Откроется окно Multiple Linear Regressions (Множественная регрессия), представленное на рис. 5.
Рисунок 5 – Стартовое окно модуля линейной множественной регрессии
Определите переменные, участвующие в анализе:
76

Щелкните на кнопке Variables (Переменные).
В открывшемся окне Select dependent and independent variables lists (Выбор зависимой и независимых переменных) щелчком мыши в соответствующих полях, как показано на рис. 6, зависимую и независимую переменные для анализа.
Рисунок 6 – Выбор зависимой и независимой переменных
Нажмите Ok.
Вновь инициируйте кнопку Ok в окне Multiple Linear Regressoin либо нажмите Enter на своей клавиатуре.
Открылось окно Multiple Regression Results (Результаты множественной регрессии), представленное на рис.7., в котором можно просмотреть разносторонние результаты построения линейного уравнения регрессии.
В данном окне просмотрите результаты оценивания. Окно результатов имеет следующую структуру:
Верх окна – информационный. Он состоит из двух частей. В первой части окна содержится основная информация о результатах оценивания. Во второй - высвечиваются регрессионные коэффициенты.
Внизу окна находятся закладки с функциональными кнопками, которые позволяют всесторонне просмотреть результаты анализа.
Рассмотрим вначале информационную часть окна. В ней содержаться краткие сведения о результатах анализа:
77
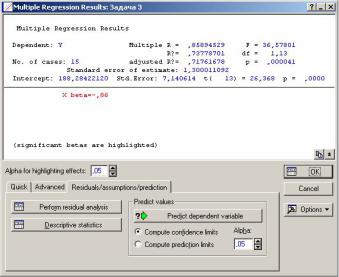
Рисунок 7 – Результаты множественной регрессии
Dependent (Имя зависимой переменной).
В нашем случае – Y;
No. of cases (Число наблюдений, по которым построена регрессия).
В нашем случае – 15.
Multiple R (Линейный коэффициент множественной корреляции или совокупный коэффициент корреляции). Он характеризует тесноту связи рассматриваемого набора факторов с исследуемым признаком, т.е. оценивает тесноту совместного влияния факторов на результат.
В нашем случае факторный признак только один, поэтому значение множественного коэффициента корреляции по модулю совпадает с парным коэффициентом корреляции и составляет 0,85894529, что подтверждает сильную связь между признаками.
R? (Квадрат линейного коэффициента множественной корреляции, обычно называемый коэффициентом
78
детерминации) является одной из основных статистик. Используется для статистической оценки тесноты связей между результативным и объясняющими показателями. Изменяется от 0 до 1. Коэффициент определяет долю дисперсии, т.е. показывает долю общего разброса относительно выборочного среднего зависимой переменной, которая объясняется построенной регрессией. Доля дисперсии, объясняемой регрессией, всегда меньше коэффициента корреляции. Используется для оценки качества регрессионной модели.
В нашем случае R? = 0,73778701. Он достаточно велик, поэтому можно считать, что в регрессионную модель включен существенный фактор и построенная модель в линейной форме отражает реальные соотношения между переменными, включенными в модель, т.к. построенная регрессия объясняет
только приблизительно 73,8% разброса значений переменной Y
относительно среднего, прочие факторы, не включенные в модель составляют соответственно 26,2% от общей вариации Y .
adjusted R? (Несмещенная оценка R? - скорректированный коэффициент детерминации) определяется как
adjusted R?=1-(1- R?)*(n/(n-p),
где n – число наблюдений в модели, p - число параметров модели (число независимых переменных плюс 1, так как в модель включен свободный член). Используется для недопущения возможности преувеличения тесноты связи. Чем больше объем совокупности, по которой исчислена регрессия, тем меньше различаются adjusted R?
и R?.
В нашем случае adjusted R?=0,71761678 R?, что говорит о том, что количество наблюдений достаточно для построения регрессионного уравнения.
df = 1,13 - число степеней свободы для вычисления F-критерия
F (Значение F-критерия). Проверяет гипотезу о статистической значимости уравнения регрессии и показателя тесноты связи (R?=0). Определяется по критерию Фишера, оценивающему вероятность случайного отклонения от нуля коэффициента
79
детерминации при отсутствии связи в генеральной совокупности.
В нашем случае для проверки гипотезы, утверждающей, что между результативной переменной и объясняющими показателями есть линейная зависимость, при числе степеней свободы – df=(1, 13) Fнабл= 36,57801 > Fтабл(0,05; 1; 48) 4,67, т.к. значение F-критерия при =0,05 превышает табличное, и даваемый уровень значимости в окне p = 0,0000, то с вероятностью 1- =0,95 построенное регрессионное уравнение и показатель тесноты связи R? значимы.
Standard error of estimate (Стандартная ошибка оценки – среднеквадратическое отклонение) – важная характеристика модели, является мерой рассеивания наблюдаемых значений относительно регрессионной прямой.
В нашем случае она равна 1,30, достаточно мала, не превышает 10% от среднего значения результативного признака, что позволяет сделать вывод о надежности подобранного уравнения
Intercept (Оценка свободного члена регрессии) – характеризует усредненное влияние факторных признаков, не включенных в модель
В нашем случае свободный член (константа) линейного уравнения регрессии составляет 188,28
Std.Error (Стандартная ошибка оценки свободного члена уравнения регрессии)
Стандартная ошибка оценки свободного члена в нашем уравнении равна 7,140614
t(df) и p(value) (Значение t-критерия и уровень p) Используются для проверки гипотезы о равенстве 0 свободного члена уравнения регрессии.
В нашем случае значения tнабл 26,368 tтабл 2,16и p 0,0000 говорят о том, что свободный член является значимым и условие о равенстве его нулю отвергается.
80