

Методичка__Сарычева Т.В
..pdf
|
|
5 |
|
|
|
|
|
|
|
на 1000 |
|
|
y = - 109,60 + 1,66x |
|
|
|
|
|
|
, |
|
0 |
R2 = 0,81 |
|
|
|
|
|
|
населения |
|
|
|
|
|
|
|
||
человек населения |
|
|
|
|
|
|
|
|
|
естественного прироста |
-5 |
|
|
|
|
|
|
|
|
-10 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
||
Коэффициент |
|
-15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-20 |
|
|
|
|
|
|
|
|
|
54 |
56 |
58 |
60 |
62 |
64 |
66 |
68 |
|
|
|
|
Доля населения в трудоспособном возрасте, % |
|
|
|||
Рисунок 5 – Результаты редактирования диаграммы
После того как вы начали такое редактирование, вы не сможете использовать функции Уменьшить или Увеличить разрядность для изменения точности.
Команда Добавить линию тренда в результате выдает
аппроксимирующую прямую, уравнение и R2.
Для получения дополнительной информации о зависимости двух переменных необходимо использовать инструмент Анализа данных - Регрессия.
2 СПОСОБ: Инструмент Анализа данных – Регрессия
Скопируйте исходные данные на Лист 2
Расположите данные, как и ранее, по столбцам, переменная
xслева, переменная y справа.
В меню Сервис выберите Анализ данных.
51

В диалоговом окне Анализа данных выберите Регрессия и нажмите Ok.
Появится диалоговое окно Регрессия (на рис. 6.)
Рисунок 6 – Диалоговое окно Регрессия
В диалоговом окне Регрессия для перемещения между строками используйте мышь или клавишу Таb. В строках, требующих ввода промежутка, выберите необходимый промежуток, щелкнув по строке ввода и указав его на листе. Чтобы увидеть ячейки листа, передвиньте диалоговое окно Регрессии, щелкнув по заголовку окна и перетащив, или щелкните по кнопке сворачивания справа в строке редактирования промежутка. Для получения дополнительной информации щелкните по кнопке
Справка.
Входной интервал Y: укажите или введите ссылки на диапазон со значениями зависимой переменной, включая метку над данными.
52
Входной интервал Х: укажите или введите ссылки на диапазон со значениями независимой переменной, включая метку над данными.
Метки: Отметьте этот пункт, так как входные интервалы Х, Y включают в себя подписи сверху.
Константа - ноль: данную опцию включите только в том случае, если вы хотите, чтобы моделируемая прямая регрессии проходила через начало координат (0, 0).
Уровень надежности: Excel автоматически выводит 95% доверительный интервал для коэффициентов регрессии. Для получения других доверительных интервалов выделите этот пункт и введите уровень значимости.
Параметры вывода: поставьте метку на против Выходной интервал и в соответствующей строке справа укажите или введите ссылку на левый верхний угол области шириной в 16 столбцов, где будут располагаться итоговые результаты и диаграммы. В случае если вы хотите, чтобы результаты располагались на отдельном листе, щелкните по кнопке Новый рабочий лист и, если нужно, введите имя нового листа; или нажмите кнопку Новой рабочей книги для расположения результатов в отдельной книге.
Остатки: включите эту опцию для получения подобранных значений (предсказанных Y) и остатков.
График остатков: отметьте этот пункт, чтобы получить диаграмму остатков для каждого значения переменной Х.
Стандартизированные остатки: Отметьте этот пункт для получения нормированных остатков (каждый из остатков делится на стандартное отклонение остатков). Данная операция позволяет легко увидеть значения, выходящие за пределы.
График подбора: отметьте этот пункт для получения точечной диаграммы входных значений Y и подобранных значений Y относительно переменной Х. Данная диаграмма
53
похожа на график с добавленной линией тренда, описанной ранее
График нормальной вероятности: данная возможность реализована не полностью, поэтому ее включать не следует.
После выбора всех опций и введения ссылок нажмите Ok.
Для того чтобы сделать все результаты видимыми, измените ширину столбцов, выполняя раздельное выделение:
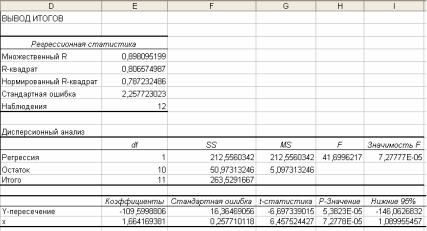
Сначала выделите ячейку с меткой Нормированный R-
квадрат (D6).
Удерживая клавишу Ctrl, щелкните по следующим ячейкам: Значимость F (I11), Коэффициенты (Е16), Стандартная ошибка (FI6), t-статистика (G16), Нижние 95% (I16) и Верхние 95% (J16).
В меню Формат выберите Столбец/Автоподбор ширины.
Отформатированные результаты должны иметь вид, как на
рис. 7
Рисунок 7 - Итоговые результаты инструмента Регрессии
Дополнительно: остатки расположены под итоговыми результатами. Чтобы облегчить сравнение:
54
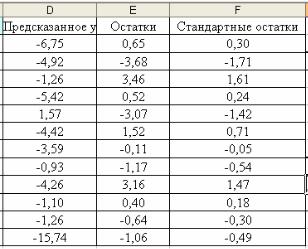
Переместите их, выделив столбцы D:F, выбрав команду Добавить ячейки в контекстном меню.
Выделите остатки (Н24:J39), включая строку меток, но без номеров Наблюдений.
Выберите Копировать или Вырезать в контекстном меню.
Выделите ячейку D1 и выберите Вставить в контекстном меню.
Подберите ширину столбцов D:F и уменьшите число десятичных знаков в ячейках С2:Е16 для получения результатов, показанных на рис..8.
Рисунок 8 – Перемещенные остатки
Смещение и наклон аппроксимирующей прямой (параметры уравнения регрессии) представлены в столбце результатов
«Коэффициенты» на рис. 7.
Число на пересечении строк Коэффициенты и Y- пересечение, равное -109,6 является постоянным членом уравнения линейной регрессии – параметром a, а на пересечеии Коэффициенты и х является наклоном – коэффициентом
55
регрессии b =1,6642. Построенное уравнение линейной регрессии выглядит так:
yˆx 109,6 1,6642x
Интерпретируются параметры регрессии точно также, как представлено выше в 1-ом способе построения уравнения, который основан на добавлении линии тренда.
Предсказанные значения результативного признака y , приведенные в остатках на рис. 8 и иногда называемые подобранными значениями, являются результатами оценивания коэффициента естественного прироста для каждого в отдельности наблюдаемого значения доли трудоспособного населения с помощью уравнения регрессии.
Остатки равны разнице между фактическими и подобранными значениями.
Например, для первого наблюдения доля трудоспособного населения составляет 61,8%. В среднем мы ожидаем, что коэффициент естественного прироста в этом случае составит -6,75 ед. на 1000 человек населения, но реальное значение коэффициента равно «-6,1».
Остаток для данного наблюдения составляет 0,65.
Обычно для ответа на вопрос «Насколько хорошо приближение?» используются следующие четыре характеристики:
Стандартная ошибка,
R2,
t-статистика
F-статистика.
Стандартная ошибка 2,257723 ≈ 2,26 приведена в ячейке
H7 и выражается в тех же единицах, что и зависимая переменная – коэффициент естественного прироста – в ед. на 1000 человек населения. Стандартную ошибку часто называют стандартной ошибкой оценки.
Значение R-квадрат, приведенное в ячейке H5, характеризует долю изменений зависимой переменной, описываемых линией регрессии. Данное число должно быть в пределах от нуля до единицы и часто выражается в процентах. В
56
нашем примере приблизительно 80,7% колебаний коэффициент естественного прироста описывается моделью с долей трудоспособного населения в качестве независимой переменной линейного уравнения.
Нормированный R-квадрат, приведенный в ячейке H6,
используется для сравнения выбранной модели с другими, использующими дополнительные независимые переменные.
Значения t-статистики в ячейках J17:J18 являются частью проверок гипотез о коэффициентах регрессии.
Например, данные 12 коэффициентов естественного прироста могут рассматриваться как выборка из большей совокупности. Нулевая гипотеза состоит в том, что зависимость отсутствует, то есть коэффициент регрессии равен нулю, а следовательно, изменение доли населения в трудоспособном возрасте не влияет на коэффициент естественного прироста. Коэффициент регрессии выборки 1,6642 со стандартной ошибкой коэффициента (оценка ошибки выборки) 0,2577 находится на расстоянии 6,4575 стандартных ошибок от нуля. Двустороннее p- значение 0,000072 приведено в ячейке К18 и является вероятностью получить данные результаты или что-либо более экстремальное при выполнении нулевой гипотезы. Таким образом, мы отвергаем нулевую гипотезу и заключаем, что имеется существенная зависимость между коэффициентом естественного прироста и долей трудоспособного населения.
Таблица анализа дисперсии в ячейках G10:L14 является критерием общего соответствия уравнения регрессии данным. Так как она подытоживает проверку нулевой гипотезы, что все коэффициенты регрессии равны нулю. Значение наблюдаемой F- статистики, представленное в ячейке K12, является частью проверки гипотезы о статистической значимости и надежности уравнения в целом. Значимость F 0,000072 приведено в ячейке L12 и является вероятностью ошибки предположения о надежности уравнения. Данное значение значительно ниже уровня значимости 0,05, следовательно построенное уравнение зависимости коэффициента естественного прироста от доли населения в трудоспособном возрасте в линейном виде является статистически значимым и надежным.
57
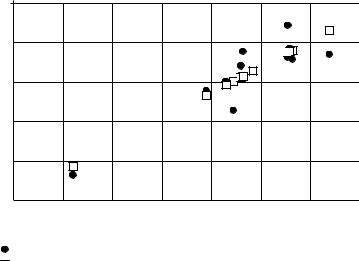
В случае парной (простой) линейной регрессии инструмент анализа строит две диаграммы: График остатков и График подбора. Данные диаграммы располагаются вверху листа, справа от итоговых результатов. В нашем примере диаграммы изначально располагаются в ячейках М1:S12, а после перемещения остатков в
Р1:V12.
Данная диаграмма подобна графику с добавленной линией тренда, за исключением того, что предсказанные значения на диаграмме отображаются маркерами без соединяющей их линии. Преобразуйте диаграмму к виду, представленному на рис. 9.
y |
График подбора |
5
0 |
|
|
|
|
|
|
|
-5 |
|
|
|
|
|
|
|
-10 |
|
|
|
|
|
|
|
-15 |
|
|
|
|
|
|
|
-20 |
|
|
|
|
|
|
|
54 |
56 |
58 |
60 |
62 |
64 |
66 |
68 |
y |
|
|
|
|
|
|
x |
 Предсказанное y
Предсказанное y
Рисунок 9 – Преобразованный график подбора прямой
График остатков (после преобразования) представлен на рис. 10. Данный тип диаграмм применяется для определения, является ли приемлемой форма функционала аппроксимирующей кривой. Если график остатков имеет случайный рисунок, то линейное приближение является удовлетворительным. Если же график
58
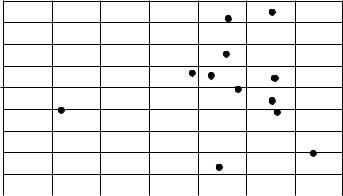
остатков имеет определенную структуру, то может потребоваться дополнительное моделирование.
График остатков
Остатки
4
3
2
1
0 -1 -2 -3 -4 -5
54 |
56 |
58 |
60 |
62 |
64 |
66 |
68 |
x |
Рисунок 10 – Преобразованный график остатков регрессии.
3 МЕТОД: Регрессионные функции
Третьим способом выполнить регрессионный анализ является использование встроенных статистических функций. В данной лабораторной работе описываются пять функций, применимых для парной (простой) регрессии, причем четыре из них имеют одни и те же аргументы.
Функция ОТРЕЗОК, которая позволяет определить значение свободного члена в уравнении имеет следующий синтаксис:
ОТРЕЗОК( известные_значения _ х;известные_значения_у).
Такой же синтаксис имеют функции НАКЛОН, определяющая значение коэффициента регрессии, КВПИРСН,
оценивающая R2 , и СТОШУХ - стандартная ошибка оценки.
Скопируйте исходные данные на Лист 3.
59
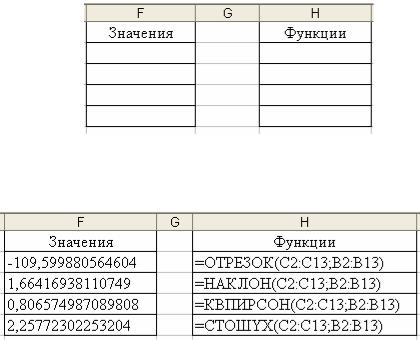
Сформируйте две таблица Значения и Функции., как показано на рис. 11
Рисунок 11 – Образец формирования таблиц
Данные четыре функции введите в ячейки Н2:Н5 рис. 12, а значения, возвращаемые ими, находятся в ячейках F2:F5.
Рисунок 12 – Регрессия с использованием функций
Для того чтобы получить рис. 12, значения функций в столбце Н еобходимо:
скопировать в Буфер обмена (Правка-Копировать);
вставить в столбец F (Правка – Специальная вставка – Значения).
Чтобы формулы отображались в столбце Н,
выберите Параметры в меню Сервис,
щелкните по вкладке Вид;
отметьте пункт Формулы в разделе Параметры окна. Сопутствующая функция ЛИНЕЙН вычисляет
коэффициенты регрессии, стандартные ошибки и другие общие характеристики. Так же как и функция ТЕНДЕНЦИЯ, она может
60