

3.6. Ошибки спецификации
Спецификация эконометрической модели, реально отражающей действительность, тонкая и сложная задача. Модель – это всегда – упрощенное, схематичное описание реальности, которая намного порядков сложнее любой модели. Не существует простых моделей, которые могут адекватно отразить сущность реальных детерминант из интересующего нас множества.
Цель построения модели –достижение такой её простой формулировки, которая не противоречит лежащей в её основе сложной реальности. Хотя простая форма модели определенно лучше для работы, существенные расхождения модели с реальностью могут иметь следствием серьезные ошибки в заключениях о поведении изучаемого объекта.
Важный аспект спецификации модели – выбор функциональной формы, соединяющей зависимую и независимые переменные. Если принять за основу для модели функциональную форму существенно отличающуюся от истинной, то любые заключения по оцениваемой модели будут иметь сомнительную ценность. Другая важная часть спецификации модели состоит в предположении о статистических свойствах в терминах ошибок уравнения регрессии. (об этом мы уже так же говорили). Мы всегда начинаем анализ (построение модели) в предположении, что эти ошибки имеют постоянную вариацию, некоррелированны друг с другом. Если эти предположения верны, то мы используя МНК и подходящую для нашей задачи процедуру оценивания, делаем и заключения об изучаемом процессе. Однако, если эти предположения серьезно нарушаются, то заключения наши так же будут расходиться с реальностью.
Обсудим одну специфическую форму ошибочной спецификации модели и прольем свет на возможные последствия этого явления. При формулировке регрессионной модели исследователь обычно делает попытку соотнести зависимую переменную интересующую его со всеми важными детерминантами. Отсюда, если как подходящая форма, принята линейная модель, то мы желаем включить в число независимых переменных все величины, которые могут заметно воздействовать на зависимую переменную.
В
формулировке регрессионной модели
неявно предполагается, что набор
независимых переменных содержит все
величины, существенно влияющие на
поведение зависимой переменной. Ясно,
что в любой практической проблеме будут
другие факторы, которые так же влияют
на зависимые переменные. Совместное
влияние этих факторов и отражено в
термине ошибки
![]() .
Однако, потенциально очень важным
является допущение, что в перечне
независимых переменных нет пропущенных
из числа тех, что существенно влияют на
зависимую переменную.
.
Однако, потенциально очень важным
является допущение, что в перечне
независимых переменных нет пропущенных
из числа тех, что существенно влияют на
зависимую переменную.
Исключая очень специальный (и редкий) случай, когда пропущенные переменные некоррелируют с независимыми переменными, включенными в регрессионную модель, очень важные последствия может иметь следующий из этого тип ошибочной спецификации. В частности оценки МНК будут смещенными и обычные заключения, которые мы производим из доверительных интервалов или проверок гипотез могут быть весьма ошибочными.
Для иллюстрации этого частного типа ошибочной спецификации обсудим пример из параграфа 3.2. Заключение, которое мы сделали в результате анализа задачи, состоит в том, что для заданного числа кредитных учреждений увеличение на один процент годовой ставки по депозитам ведет к ожидаемому увеличению на 0.237 процентов в годовом доходе этих учреждений.
Теперь
предположим, что нас интересует только
эффект влияния процентной ставки по
депозитам на годовой доход кредитных
учреждений. Один из подходов к этой
проблеме может состоять в том, что мы
оценим регрессионное уравнение с двумя
переменными, где зависимая переменная
– как и прежде - годовой доход кредитных
учреждений, а независимая – процентная
ставка по депозитам. Мы используем тот
же набор значений за 25 лет. Результатом
анализа будет модель:
![]() .
Значение стандартной ошибки для
коэффициента регрессии составило
0,0356. ЗначениеR2
для этой модели заметно уменьшилось и
составило 0,59. Однако здесь есть и более
серьезные последствия. Полученная
модель предполагает, что однопроцентное
увеличение по долларовым депозитам
ведет к ожидаемому снижению на 0,169
процента годового дохода. Более того,
сравнение коэффициента оценки с оценкой
стандартной ошибки показывает, что нуль
гипотеза о нелинейной связи между этими
переменными отклоняется в пользу
альтернативной, состоящей в том, что
увеличение процента по депозитам ведет
к ожидаемому снижению годового дохода.
Но такое заключение, несомненно, не
соответствует нашему интуитивному
пониманию проблемы, состоящему в том,
что, при прочих равных, мы можем ожидать,
что рост ставок депозитов повлечет за
собой увеличение годового дохода
кредитной организации. Однако за 25
летний период, для которого мы оценивали
модель условие «при прочих равных» не
выполнялось. В частности, другая
потенциально важная переменная – число
кредитных учреждений – заметно изменялась
в течение этого периода. Когда эта важная
переменная была включена в регрессионный
анализ, мы пришли к противоположному
заключению. Выяснилось, как мы и
предполагали, что связь между прибылью
и процентом по депозиту – положительная,
если число кредитных учреждений
принимается в расчет.
.
Значение стандартной ошибки для
коэффициента регрессии составило
0,0356. ЗначениеR2
для этой модели заметно уменьшилось и
составило 0,59. Однако здесь есть и более
серьезные последствия. Полученная
модель предполагает, что однопроцентное
увеличение по долларовым депозитам
ведет к ожидаемому снижению на 0,169
процента годового дохода. Более того,
сравнение коэффициента оценки с оценкой
стандартной ошибки показывает, что нуль
гипотеза о нелинейной связи между этими
переменными отклоняется в пользу
альтернативной, состоящей в том, что
увеличение процента по депозитам ведет
к ожидаемому снижению годового дохода.
Но такое заключение, несомненно, не
соответствует нашему интуитивному
пониманию проблемы, состоящему в том,
что, при прочих равных, мы можем ожидать,
что рост ставок депозитов повлечет за
собой увеличение годового дохода
кредитной организации. Однако за 25
летний период, для которого мы оценивали
модель условие «при прочих равных» не
выполнялось. В частности, другая
потенциально важная переменная – число
кредитных учреждений – заметно изменялась
в течение этого периода. Когда эта важная
переменная была включена в регрессионный
анализ, мы пришли к противоположному
заключению. Выяснилось, как мы и
предполагали, что связь между прибылью
и процентом по депозиту – положительная,
если число кредитных учреждений
принимается в расчет.
Этот пример очень хорошо иллюстрирует обсуждаемую ситуацию. Если важная объясняющая переменная не была включена в регрессионную модель, любые заключения об эффекте других независимых переменных могут быть абсолютно ложными. В этом частном случае мы видим, что добавление необходимой переменной, может изменить связь от существенной негативной на существенную позитивную.
Дальнейшее осмысление может быть достигнуто проверкой исходных данных. Во второй части периода годовой доход уменьшался, а ставки депозитов росли, что предполагает негативную связь между переменными. Однако дальнейший взгляд в данные обнаруживает рост числа кредитных учреждений в этот период. Мы предполагали возможность того, что этот фактор может быть причиной уменьшения годового дохода. Разумный путь выхода из запутанной ситуации - разделение эффекта двух независимых переменных на зависимую переменную в модели с совместным их влиянием в регрессионном уравнении. Этот пример иллюстрирует важность использования множественной регрессии вместо парной в случае, когда изучаемое явление существенно детерминирует несколько независимых переменных.
Фиктивные переменные в моделях множественной регрессии
Как известно, одним из условий, лежащих в основе стандартных регрессионных моделей, является то, что переменные должны быть непрерывного типа. Значительная часть переменных в социально-экономических исследованиях таковыми не является. Так, например, среди переменных, имеющих значительное влияние на величину заработной платы, мы анализируем пол, образование, профессию и ряд других переменных дискретного типа. Обойти это препятствие в регрессионной модели позволяет введение двоичных или, как еще называют, фиктивных (dummy) переменных. При введении таких переменных в модель мы преобразуем их в атрибутивные и присваиваем значение единицы в случае наличия признака и нуля – при его отсутствии.
Поясним наш подход на следующем простом примере. Пусть yi – заработная плата i-го работника (или функция от заработной платы), xi – пол работника. Предположим, что заработная плата распределена согласно нормальному закону с дисперсией 2 и средней 0 в случае если работник - женщина, и 1, если работник - мужчина. Эта ситуация описывается регрессионной моделью, в которой зависимая переменная – заработная плата (Y), а пол работника (X) – объясняющая переменная.
![]() (3.13),
(3.13),
где
![]() ,
если работник мужчина,
,
если работник мужчина,
![]() ,
в других случаях,
,
в других случаях,
– случайная переменная, удовлетворяющая основным условиям классической нормальной регрессионной модели.
Средняя оценка y корреспондирует с двумя оценками x так, что:
e(yx=0) =,
e(yx=1) =+.
Отсюда =0 и += 1 или =1-0.
Это означает, что свободный член модели – мера средней заработной платы при условии, что работник – женщина, а коэффициент – разница между заработной платой мужчины и женщины.
Коэффициенты регрессионного уравнения (3.13) оцениваются методом наименьших квадратов. Напомним:
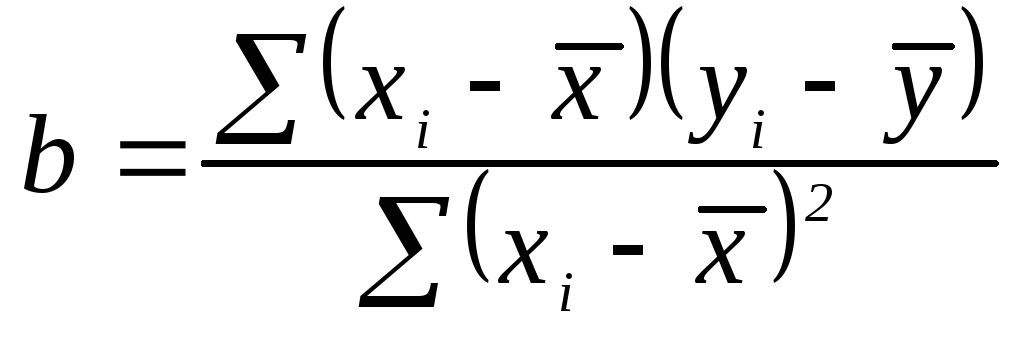 ,.
,.
![]()
Пусть
![]() - число мужчин в выборке,
- число мужчин в выборке,
![]() -
число женщин.
-
число женщин.
![]() -
средняя заработная плата мужчин,
-
средняя заработная плата мужчин,
![]() -
средняя заработная плата женщин.
-
средняя заработная плата женщин.
Тогда
![]()
![]()
![]()
![]()
Следовательно,
![]()
и
![]() ,
,
и
![]() .
.
То
есть оценка МНК коэффициентов регрессии
равна разности между выборочной средней
заработной платой мужчин и женщин, а
свободный член, полученный МНК равен
средней заработной плате женщин. Проверка
гипотезы о равенстве ![]() эквивалентна t-статистике о равенстве
двух средних.
эквивалентна t-статистике о равенстве
двух средних.
Если нам необходимо ввести в уравнение в качестве объясняющей переменной полихотомические характеристики такие, например, как образование, профессия и так далее, то необходимо каждую из категорий преобразовать в двоичную переменную. Например, если шкала видов образования работника имеет следующие характеристики: высшее, среднее и неполное среднее, то необходимые для модели двоичные переменные будут иметь вид xi1=1, если работник имеет высшее образование, и равна 0 во всех других случаях, xi2=1, если работник имеет среднее образование, и равна 0 во всех других случаях, xi3=1, если у работника неполное среднее образование, равна 0 во всех других случаях.
Обозначим среднюю заработную плату работников с различным типом образования 1, 2, 3 соответственно. Подходящее регрессионное уравнение может быть записано так:
yi=1+2xi2+3xi3+i, (3.14)
где Y- заработная плата.
Заметим, что когда xi2=0, xi3 должен быть равен 1 и наоборот. Средняя оценка yi корреспондирует с различными оценками регрессора как
e(yi xi2=1, xi3=0) = 1+2,
e(yi xi2=0, xi3=1) = 1+3,
e(yi xi2=0, xi3=0) = 1.
Из этого следует, что
1=1,
2=2-1,
3=3-1.
Такой результат аналогичен полученному для дихотомической переменной в уравнении (3.13). Модели, описанные в уравнениях (3.13) и (3.14), аналогичны моделям дисперсионного анализа, но более компактны и легки в интерпретации.
Модели довольно просто расширить на случай нескольких качественных объясняющих переменных. Для пояснения воспользуемся предыдущими переменными, описанными в уравнениях (3.13) и (3.14). Предположим, что заработная плата работника зависит не только от его пола, но и от того какое он имеет образование. Мы вновь допускаем, что заработная плата – нормально распределенная величина с дисперсией 2 и наблюдения независимы. Пусть:
11 – средняя заработная плата в случае, если работник – мужчина с высшим образованием;
10 – средняя заработная плата в случае, если работник – женщина с высшим образованием;
21 – средняя заработная плата в случае, если работник – мужчина со средним образованием;
20 – средняя заработная плата в случае, если работник – женщина со средним образованием;
31 – средняя заработная плата в случае, если работник – мужчина с неполным средним образованием;
30 – средняя заработная плата в случае, если работник – женщина с неполным средним образованием.
Регрессионная модель формулируется так:
yi=1+2xi2+3xi3+zi+i, (3.15)
где yi, xi2, xi3 – определены как в уравнениях (3.13) и (3.14), а zi=1, если работник мужчина, zi=0, если – женщина. Заметим вновь, что когда xi2=0, то xi3=1 и наоборот. Средние оценки yi, корреспондирующие с различными оценками регрессора, следующие:
e(yi xi2=1, xi3=0, zi=1) = 1+2+,
e(yi xi2=1, xi3=0, zi=1) = 1+3+,
e(yi xi2=1, xi3=0, zi=1) = 1+,
e(yi xi2=1, xi3=0, zi=0) = 1+2,
e(yi xi2=1, xi3=0, zi=0) = 1+3,
e(yi xi2=1, xi3=0, zi=0) = 1.
Вследствие чего:
1= 10,
2= 20-10 = 21-11,
3= 30-10 = 31-11,
= 11-10 = 21-20 = 31-30.
Это значит, что 1 – мера средней заработной платы, если работник – женщина с высшим образованием, 2 – разница между средними заработками в случае, если работник имеет высшее или среднее образование независимо от пола, 3 – разница между средней заработной платой в случае, если работник имеет неполное среднее образование и если работник с высшим образованием независимо от пола, – разница между средними заработками в зависимости от того мужчина это или женщина.
Увеличение числа объясняющих переменных не меняет принципа интерпретации результатов регрессионных моделей с двоичными переменными. Необходимо лишь строго соблюдать ряд правил. Так, мы не можем представить трихотомическую переменную тремя двоичными переменными, необходимо использовать две переменные, иначе мы пропустим константу в регрессионном уравнении. Например, если мы запишем уравнение (3.14) в виде:
yi=1+2xi2+3xi3+4xi4+i,
где xi4=1, если работник имеет высшее образование, а xi4=0 во всех других случаях, то решение для b1, b2, b3, b4 будут неопределенными. Причина этого в том, что xi4=1-xi2-xi3 и система нормальных уравнений не будет независима. Таким образом, когда объясняющие характеристики предполагают классификацию по G типам, мы используем (G-1) двоичных переменных для их представления.
Следующее обстоятельство связано с интерпретацией эффекта двоичных переменных в полулогарифмических уравнениях. Это уравнения, зависимая переменная в которых представлена в логарифмической форме. Как правило, при оценке заработной платы мы исходим из того, что она подчиняются логарифмически-нормальному распределению, поэтому во всех уравнениях мы используем значение логарифма заработной платы. Общая форма уравнения может быть записана в следующем виде:
![]() ,
(3.16)
,
(3.16)
где xi – представляет непрерывные (количественные) переменные, а Dj представляет двоичные переменные. Коэффициенты количественных переменных:
![]()
![]() (3.17)
(3.17)
Следовательно, i, умноженное на сто, показывает на сколько процентов изменяется y при малых изменениях в x, то есть интерпретируется как коэффициент эластичности.
Поскольку двоичные переменные входят в уравнение в дихотомической форме, то производная от зависимой переменной по отношению к двоичной переменной не существует. Подходящую интерпретацию коэффициента двоичных переменных можно продемонстрировать путем трансформации регрессионного уравнения. Предположим для простоты, что в уравнении одна двоичная переменная. Уравнение запишется так:
![]() ,
,
где g – относительный эффект присутствия фактора, представленного двоичной переменной. Тогда g=(y1-y0)/y0, где y1 и y0 – оценки зависимой переменной, когда двоичная переменная равна 1 или 0 соответственно. Отсюда коэффициент при двоичной переменной =Ln(1+g). Относительный эффект на y: g=exp()-1, а процентный эффект: 100g=100(exp()-1). Для малых g приблизительно равно g. Когда g положительно, меньше, чем g, а когда отрицательно, то алгебраически меньше, чем g, но больше по абсолютной величине.
Модель множественной регрессии может включать в себя и переменные, называемые “интерактивными терминами”. В предыдущем примере мы обсуждали зависимость заработной платы от пола и образования работника. Мы условно предполагали, что средняя заработная плата зависела от уровня образования работника и его пола и что разница между средней заработной платой мужчин и женщин – одинакова для всех уровней образования. Предположим, что мы не уверены в правильности такого допущения. Тогда регрессионная модель (3.15) может быть модифицирована так:
![]() (3.18),
(3.18),
где
все переменные определены как в (3.14).
Среднее значение ![]() ,
корреспондирующее с различными значениями
регрессора есть:
,
корреспондирующее с различными значениями
регрессора есть:
![]()
![]()
![]()
![]()
![]()
![]()
Это означает, что мы можем определить регрессионные коэффициенты в терминах средней заработной платы следующим образом:
1=10
2=20-10
3=30-10
=11-10
2=(31-30) –(11-0)
3=(21-20) –(11-0)
Различия в средней заработной плате для мужчин и женщин, имеющих различный уровень образования составит:
-
Высшее образование
11-10=
Среднее образование
21-20=+3
Не имеет среднего образования
31-30=+2
В эконометрических моделях не так часты ситуации, когда к качестве объясняющих переменных выступают только фиктивные или только количественные переменные. Чаще в модели присутствуют и те, и другие переменные. Традиционный пример – функция потребления, оцениваемая из данных, которые включают различные периоды времени, например, военное и мирное время. В этой модели предполагается, что среднее потребление зависит от дохода и от того какой период мы рассматриваем: войну или мир. Простой путь представления такой модели есть:
![]()
где С представляет потребление, Y – доход, а Z – фиктивная переменная, такая, что
Zt = 1, если период войны,
Zt= 0, в другом случае.
Тогда мы имеем:
![]() -
война,
-
война,
![]() -
мир.
-
мир.
Таким
образом, мы фактически постулируем, что
в военное время пересечение (свободный
член модели) функции потребления
изменяется от ![]() до
до
![]() .
Графическая иллюстрация этого дана на
рисунке 9
.
Графическая иллюстрация этого дана на
рисунке 9
П Военное
время Мирное
время

Доходы
Рис. 9
Если представить свободный член модели как прожиточный минимум, то эта модель показывает, как прожиточный минимум изменяется в период войны. Существенность этих изменений можно проверить, выдвигая гипотезу:
H0: =0
H1: 0.
Эффект войны можно учесть в функции потребления различно, например, если мы постулируем, что военные условия влияют на наклон линии регрессии, но не на пересечение с функцией потребления (то есть прожиточный минимум). В соответствии с такой теоретической формулировкой регрессионная модель есть:
![]() (3.19).
(3.19).
где переменные определены так же. В этом случае мы имеем:
![]() -
война
-
война
![]() -
мир.
-
мир.
Уравнение (3.19) показывает, что эффект войны изменяет предельную склонность к потреблению, как показано на рисунке 10.
П Военное время
Мирное
время

Доходы
Рис. 10
Это
значение может быть проверено при помощи
гипотезы о равенстве нулю ![]() .
.
Третья, последняя возможность оценки различий между потреблением в военное и мирное время состоит в предположении, что и свободный член и наклон линии регрессии изменяются для военного времени. Регрессионное уравнение примет вид:
![]() (3.20).
(3.20).
Тогда имеем:
![]() -
война
-
война
![]() -
мир.
-
мир.
Эти
взаимоотношения иллюстрируются рисунком
11. Интересным в уравнении является то,
что оценка МНК регрессионных коэффициентов
совершенно та же как и те, что были бы
получены из двух отдельных регрессий
Ct
и Yt ,
одна из которых получена для данных
военного времени, а другая для данных
мирного времени. Это можно доказать
путем преобразования формул МНК, но мы
не будем это делать. Разница в двух
подходах заключается только оценке
относительно ![]() .
Если мы предполагаем нормальное
распределение, то вариация
.
Если мы предполагаем нормальное
распределение, то вариация ![]() не
изменяется в течение периода, тогда их
оценка из (3.19?) основанная на всех
наблюдениях, будет эффективной. Тогда
как две оценки, полученные из двух
различных подвыборок не будут таковыми.
Это происходит вследствие того, что
оценка
не
изменяется в течение периода, тогда их
оценка из (3.19?) основанная на всех
наблюдениях, будет эффективной. Тогда
как две оценки, полученные из двух
различных подвыборок не будут таковыми.
Это происходит вследствие того, что
оценка ![]() основана на любой повыборке и не
использует информацию о
основана на любой повыборке и не
использует информацию о ![]() ,
содержащуюся в другой подвыборке.
,
содержащуюся в другой подвыборке.
Военное
время
П
 отребление
отребление
Мирное
время

Доходы