

6. Конвейерный процессор.
Конвейер – это простой подход к использованию параллелизма, основанный на одновременном выполнении различных фаз (выборки инструкции, декодирование, выполнение и т.д.) обработки инструкции. Конвейерная передача предполагает, что эти фазы независимы между различными операциями и могут быть перекрыты – когда это условие не выполняется, процессор останавливает последующие фазы для обеспечения зависимости. Таким образом, несколько операций могут обрабатываться одновременно с каждой операцией на разных этапах её разработки.
Instruction 1
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 2
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 3
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 4
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Time →
Примеры SoC с использованием конвейерных Soft процессоров – процессор реализован с помощью ПЛИС или аналогичной реконфигурируемой технологии.
Процессор |
Длина слова (бит) |
Уровень конвейера |
Всего И/Д-кеш (КБ) |
Floating-Point Unit (FPU) |
Реализация |
|
Xilinx MicroBlaze |
32 |
3 |
0-64 |
Опционально |
FPGA |
|
Altera Nios II fast |
32 |
6 |
0-64 |
- |
FPGA |
|
ARC 600 |
16/32 |
5 |
0-32 |
Опционально |
ASIC |
|
Tensilica Xtensa LX |
16/32 |
5-7 |
0-32 |
Опционально |
ASIC |
|
Cambridge XAP3a |
16/32 |
2 |
- |
- |
ASIC |
|
7. Ilp (параллелизм на уровне инструкций).
Хотя конвейер не обязательно приводит к выполнению нескольких инструкций одновременно, есть и другие методы. Эти технологии могут использовать некоторую комбинацию статического планирования и динамического анализа для одновременного выполнения фактической фазы оценки нескольких различных операций, потенциально обеспечивая скорость выполнения более одной операции за каждый цикл. Поскольку исторически большинство инструкций состоят только из одной операции, этот вид параллелизма был назван ILP (параллелизм на уровне инструкций).
Две архитектуры, которые используются в ILP – это суперскалярные процессоры и процессоры VLIW. Они используют различные методы для достижения скорости выполнения, превышающей одну операцию за цикл.
Суперскалярный процессор динамически исследует поток инструкции, чтобы определить, какие операции являются независимыми и могут быть вырезаны.
Процессор VLIW (very long instruction word – «очень длинная машинная команда») полагается на компилятор, для анализа доступных операций (OP) и планирования независимых операций в длинные слова инструкции, которые затем выполняют эти операции параллельно без дальнейшего анализа.
Instruction 1
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 2
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 3
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 4
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 5
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Instruction 5
-
IF
→
ID
→
AG
→
DF
→
EX
→
WB
Time →
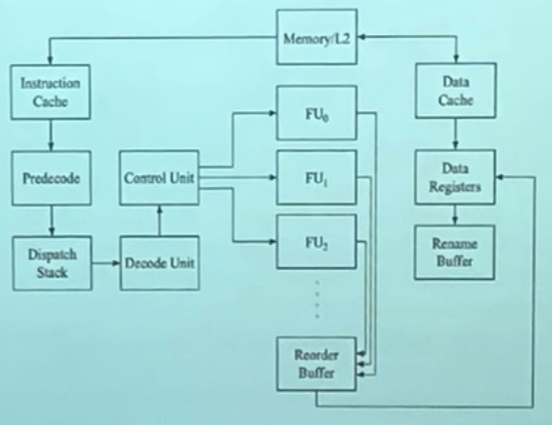
Суперскалярные процессоры. Динамические конвейерные процессоры по-прежнему ограничены выполнение одной операции за цикл в силу своего скалярного характера. Этого ограничения можно избежать, добавив несколько функциональных блоков и динамического планировщика для обработки более одной инструкции за цикл.
Наиболее значительным преимуществом суперскалярного процессора является то, что обработка нескольких команд за цикл выполняется прозрачно для пользователя.
Процессоры VLIW. В отличие от динамического анализа в аппаратном обеспечении для определения того, какие операции могут выполняться параллельно, процессоры VLIW полагаются на статический анализ в компиляторе.
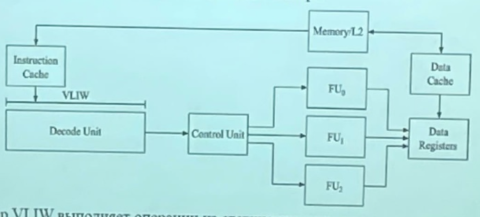
Процессор VLIW выполняет операции из статически запланированных инструкций, которые содержат несколько независимых оераций.
Для приложений, которые могут быть запланированы статически для эфеективного использования ресурсов процессора, простая реализация VLIW приводит к высокой производительности. К сожалению, не все приложения могут быть эффективно запланированы статически. Во многих приложениях выполнение не проходит точно по определённому пути.