

Красавин Компютерныы практикум в среде МатЛаб 2015
.pdf7.4. Сортировка обменами
При сортировке обменами два элемента меняются местами, если они расположены не по порядку (рис. 7.7), этот процесс повторяется до тех пор, пока не будут перебраны все возможные пары элементов.
Рис. 7.6. Сортировка выбором. Серым фоном показаны упорядоченные элементы
Рис. 7.7. Сортировка обменами. Серым фоном показаны упорядоченные элементы. В левом столбце показаны номера элементов, которые сравниваются на текущем шаге
Временные затраты при этом способе сортировки составляют порядка /2 операций, этот метод является более экономным по сравнению с предыдущими и часто используется в стандартных математических пакетах. Блок-схема алгоритма показана на
81
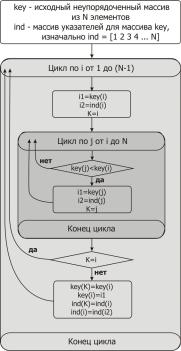
рис. 7.8; в этом алгоритме, помимо сортировки элементов
исходного массива |
, создается также массив указателей |
на |
|
упорядоченные элементы массива |
. |
|
|
7.5. Оптимизированный метод
Представленные выше методы сортировки будут выполнять сортировку за разумное время при числе элементов порядка нескольких тысяч. При большем количестве элементов время сортировки будет замедляться, и необходимы более эффективные методы. Одним из вариантов ускорения алгоритмов сортировки является идея производить перемещения не между отдельными элементами, а сразу между блоками из нескольких десятков или сотен элементов.
Рис. 7.8. Блок-схема алгоритма сортировки обменами
82

Приведем один из вариантов такой оптимальной сортировки.
Разделим |
весь неупорядоченный |
массив из |
элементов на |
||||
кластеры – блоки из |
|
|
|
элементов (при таком размере |
|||
|
|
|
|||||
кластера |
скорость |
описанного ниже способа сортировки будет |
|||||
|
3√ |
|
|
||||
максимальной). Количество кластеров в полном массиве также будет порядка , причем в последнем кластере будет элементов, где – остаток от целочисленного деления на (рис. 7.9). Внутри каждого из кластеров проводится обычная сортировка (например, методом обменов), что займет порядка
операций.
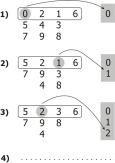
Рис. 7.9. Подготовка неупорядоченного массива для оптимальной сортировки:
1)исходный массив из десяти элементов;
2)массив разделен на блоки по три элемента, при этом в последнем блоке оказался один элемент;
3)внутри каждого блока проведена сортировка элементов
Далее просматриваем минимальные элементы в каждом кластере (так как все кластеры к этому моменту уже упорядочены, то минимальным элементом в каждом кластере будет первый элемент) и выбираем наименьший из них. Этот процесс займет порядка операций. Выбранный элемент заносим в новый массив, в котором будут накапливаться упорядоченные элементы, и удаляем его из кластера, где он находился (рис. 7.10). При этом следует следить за числом элементов в каждом кластере и не рассматривать кластеры, из которых все элементы перешли в упорядоченный массив. Заполнение всего упорядоченного массива
займет порядка |
операций, т.е. будет даже быстрее |
|
83 |
первоначальной сортировки, и в итоге весь алгоритм потребует порядка ~ / операций.
Рис. 7.10. Оптимизированная сортировка
Представленный метод не является самым оптимальным. Существуют подходы, доводящие время сортировки до ~ операций.
Задания
7.1. Реализовать алгоритмы сортировки одномерных массивов произвольных чисел:
1)методом выбора;
2)методом вставки;
3)методом обмена;
4)оптимизированным методом.
Провести сортировку 500, 1000, 2000, 4000, 8000, … чисел каждым из методов и построить на одном графике зависимость времени сортировки от количества элементов в массиве для каждого метода. С какого количества элементов оптимизированный метод становится более эффективным?
84
7.2. Имеется массив из различных упорядоченных по возрастанию чисел. Реализовать программу поиска номера заданного элемента в массиве
1)прямым перебором;
2)методом деления отрезка пополам.
Построить графики зависимости времени поиска от длины массива для каждого из методов. Сравнить эффективность двух алгоритмов.
7.3. Имеется массив из различных упорядоченных по возрастанию целых чисел. Построить и реализовать алгоритм поиска номера заданного элемента в массиве методом деления отрезка пополам, проводя поиск по разрядам.
85
8
Работа с файлами
8.1. Запись информации в файл
При использовании информации из внешних источников, а также при сохранении информации для ее последующей обработки возникает необходимость использования функций работы с файлами.
Существует три основных метода работы с файлами: считывание информации из файла, запись информации в файл (создание файла) и добавление информации в файл. Файлы в общем случае могут иметь произвольные типы и расширения. Здесь будут рассмотрены файлы с расширениями .dat, .txt,
.mat, наиболее часто используемые при работе с MatLab.
Функция save используется для записи информации из матричной переменной в файл или для создания файла с данной матричной переменной:
save filename matrixvariablename -ascii
Аргумент -ascii используется для создания файлов в текстовом формате. Например,
mymat = rand(2,3)
mymat = |
0.8214 |
0.6154 |
0.4565 |
||
0.0185 |
0.4447 |
0.7919 |
save testfile.dat mymat -ascii
86
Приведенный набор команд создаст файл testfile.dat, в котором будет записана матрица
0.4565 0.8214 0.6154
0.0185 0.4447 0.7919
в текстовом формате. Если файл testfile.dat уже существует, то данный набор команд его пересоздаст.
Функция type используется для отображения содержимого файла:
type mymat
4.5646767e-001 8.2140716e-001 6.1543235e-001
1.8503643e-002 4.4470336e-001 7.9193704e-001
Для добавления информации к файлу используется дополнительный аргумент -append, например,
mat2 = rand(3,3)
mat2 =
0.9218 0.4057 0.4103
0.7382 0.9355 0.8936
0.1763 0.9169 0.0579
save testfile.dat mat2 -ascii -append
В результате выполнения данных команд файл testfile.dat
изменится и будет содержать следующие данные:
0.4565 0.8214 0.6154
0.0185 0.4447 0.7919
0.9218 0.4057 0.4103
0.7382 0.9355 0.8936
0.1763 0.9169 0.0579
87
8.2. Чтение информации из файла
Для считывания информации из файла используется функция load. Если файл имеет расширение .txt или .dat, то при прочтении файла будет создана матричная переменная с именем, аналогичным имени файла. Например,
load testfile.dat
who |
% |
запрос |
обо |
всех |
переменных |
рабочего |
пространства |
|
|
|
|
||
Your variables are: testfile
testfile |
|
|
testfile = |
0.8214 |
0.6154 |
0.4565 |
||
0.0185 |
0.4447 |
0.7919 |
0.9218 |
0.4057 |
0.4103 |
0.7382 |
0.9355 |
0.8936 |
0.1763 |
0.9169 |
0.0579 |
Функция load работает только тогда, когда в каждой строке файла имеется одинаковое число значений, таким образом информация может быть сохранена в виде матричной переменной, так как функция savе может сохранять только матричные переменные. В других случаях следует использовать функции низкоуровневого общения с файловой системой.
8.3. Функции низкоуровневого общения с файловой системой
Работа с файлами с помощью функций низкоуровневого общения с файловой системой делится на три этапа: открытие файла; считывание, запись (создание) файла, изменение информации в файле; закрытие файла.
88
Для того чтобы открыть файл, используется функция fopen. По умолчанию функция fopen открывает файл для чтения. Для открытия файла в ином режиме, например, для записи или изменения, используется дополнительный строковый аргумент. Если функция fopen возвращает -1, то это означает, что открытие файла прошло неудачно. Если же открытие файла прошло удачно, то возвращается положительное целочисленное значение, которое соответствует идентификатору файла. Данный идентификатор используется в дальнейшем для вызова функций низкоуровневого общения с файловой системой. Например,
fid = fopen('filename', 'permission string'); % здесь fid – идентификатор файла, permission string –
строковый аргумент
Строковый аргумент может принимать следующие значения: r – для чтения информации из файла;
w – для записи информации в файл (создания файла); a – для добавления информации в файл.
После использования функции fopen значение возвращенного идентификатора файла следует проверять, для того чтобы определить успешность открытия файла. Например,
fid = fopen('samp.dat'); if fid == -1
disp('Файл не удается открыть') else
...
% Команды работы с файлом
...
end
После завершения работы с файлом его следует закрыть. Для этого используется функция fclose, которая возвращает 0, если файл закрыт успешно, или -1, если файл не удалось закрыть. Файлы можно закрывать по отдельности, используя
89
идентификаторы, или можно закрыть все файлы вместе, используя аргумент all. Например,
closeresult = fclose(fid);
closeresult = fclose('all');
Возвращаемое значение closeresult также следует проверять. Например,
fid = fopen('filename', 'permission string'); if fid == -1
disp('Файл открыт не удается открыть')
else
...
% Команды работы с файлом
...
closeresult = fclose(fid); if closeresult == 0
disp('Файл закрыт успешно')
else
disp('Файл не удается закрыть')
end
end
Существует несколько функций низкоуровневого общения с файловой системой, предназначенных для чтения информации из файлов. Функция fscanf считывает форматированную информацию в матричную переменную, используя такие специальные аргументы для преобразования типов, как %d – для целых чисел (integer), %s – для строковых данных (string) и %f – для чисел с плавающей точкой (float). Функция textscan считывает текстовую информацию из файла и сохраняет ее в виде массива ячеек (cell array), также используя специальные аргументы для преобразования типов. Функции fgetl и fgets считывают файл построчно, разница между ними заключается в том, что
90